




使用MongoDB、Flask和Next.js的LlamaIndex检索增强生成
使用MongoDB、Flask和Next.js
查看此演示运行效果!
这是什么?
LlamaIndex是一个开源框架,让您可以构建由大型语言模型(LLMs)如OpenAI的GPT-4驱动的AI应用程序。本应用程序展示了如何从零开始到完全部署的Web应用程序的整个过程。我们将向您展示如何运行此仓库中的所有内容,然后开始根据自己的需求进行定制。
在这个例子中,我们将使用MongoDB作为数据存储和向量存储。我们的后端将是由Flask驱动的Python API,前端将是用Next.js编写的JavaScript Web应用。
该应用将加载一系列推文(从Twitter存档导出加载),然后对其进行索引以回答关于作者及其观点的问题。
我们将要做什么
此演示的基本步骤是:
- 将JSON文件中的数据导入MongoDB数据库(如果您已经在Mongo中有数据,可以跳过此步骤)
- 使用LlamaIndex对数据进行索引。这将在底层使用OpenAI的gpt-3.5-turbo,并将您的文本转换为向量嵌入,因此您需要一个OpenAI API密钥,根据数据量的多少,这可能需要一些时间
- 将嵌入数据存回MongoDB。LlamaIndex将自动为您完成这一步
- 在MongoDB中创建向量搜索索引。这是您需要在MongoDB UI中手动执行的步骤
- 查询数据!这将证明数据现在是可查询的。然后您可能想在此基础上构建一个应用程序
- 设置一个Python Flask API来回答关于数据的问题,托管在Render上
- 设置一个JavaScript编写的Next.js前端,同样托管在Render上。这将接受用户问题,将它们传递给API,并显示结果
说明
您可以将这些说明作为教程,从头开始重建应用程序,或者克隆仓库并将其用作模板。
开始之前
我们假设您已安装了当前版本的Python(3.11.6或更高版本),以及用于前端的Node.js(20版或更高版本)和用于源代码控制的git。
获取代码
首先克隆此仓库
git clone git@github.com:run-llama/mongodb-demo.git
注册MongoDB Atlas
我们将使用MongoDB的托管数据库服务MongoDB Atlas。您可以免费注册并获得一个小型免费托管集群:
注册过程将引导您创建集群并确保其配置为您可以访问。一旦集群创建完成,选择"连接",然后选择"连接到您的应用程序"。选择Python,您将看到一个类似这样的连接字符串:

设置环境变量
复制连接字符串(确保包含您的密码)并将其放入仓库根目录下名为.env的文件中。它应该看起来像这样:
MONGODB_URI=mongodb+srv://seldo:xxxxxxxxxxx@llamaindexdemocluster.xfrdhpz.mongodb.net/?retryWrites=true&w=majority
您还需要为数据库和存储推文的集合选择名称,并将它们包含在.env文件中。它们可以是任何字符串,但我们使用的是:
MONGODB_DATABASE=tiny_tweets_db
MONGODB_COLLECTION=tiny_tweets_collection
设置Python虚拟环境并安装依赖
为避免与其他Python依赖冲突,创建一个Python虚拟环境来工作是个好主意。有很多方法可以做到这一点,但我们使用的方法是在仓库根目录下运行以下命令��:
python3 -m venv .venv source .venv/bin/activate
现在我们将使用pip一次性安装所有需要的依赖:
pip install -r requirements.txt
这将安装MongoDB驱动程序、LlamaIndex本身以及一些实用程序库。
将推文导入MongoDB
现在您已准备好将我们预先准备的数据集导入Mongo。这是文件tinytweets.json,包含了大约1000条来自@seldo在2019年中期的Twitter推文。设置好环境后,您可以通过运行以下命令来完成导入:
python 1_import.py
如果您感兴趣,代码如下。如果您不想使用推文,可以用任何其他JSON对象数组替换json_file,但您需要稍后修改一些代码以确保正确的字段被索引。这里没有LlamaIndex特定的代码;您可以用任何想要的方式将数据加载到Mongo中。
json_file = 'tinytweets.json' # 从本地.env文件加载环境变量 from dotenv import load_dotenv load_dotenv() import os import json from pymongo.mongo_client import MongoClient from pymongo.server_api import ServerApi # 从本地文件加载推文 with open(json_file, 'r') as f: tweets = json.load(f) # 创建新客户端并连接到服务器 client = MongoClient(os.getenv('MONGODB_URI'), server_api=ServerApi('1')) db = client[os.getenv("MONGODB_DATABASE")] collection = db[os.getenv("MONGODB_COLLECTION")] # 将推文插入mongo collection.insert_many(tweets)
加载和索引数据
现在我们准备索引数据。为此,LlamaIndex将从Mongo中提取文本,将其分割成块,然后将这些块发送给OpenAI转换为向量嵌入。然后,嵌入将存储在Mongo的新集合中。这个过程可能需要一些时间,取决于您有多少文本,但好消息是一旦完成,您将能够快速查询,而无需重新索引。
我们将使用OpenAI进行嵌入,所以现在是时候生成OpenAI API密钥(如果您还没有的话),并将其添加到您的.env文件中,如下所示:
OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
您还需要为存储嵌入的新集合选择一个名称,并将其添加到.env文件中,同时还要添加向量搜索索引的名称(我们将在下一步创建这个索引,在您索引数据之后):
MONGODB_VECTORS=tiny_tweets_vectors
MONGODB_VECTOR_INDEX=tiny_tweets_vector_index
如果您正在索引我们提供的推文数��据,您现在就可以开始了:
python 2_load_and_index.py
您可以查看此脚本的完整源代码,但让我们强调几个重要部分:
query_dict = {} reader = SimpleMongoReader(uri=os.getenv("MONGODB_URI")) documents = reader.load_data( os.getenv("MONGODB_DATABASE"), os.getenv("MONGODB_COLLECTION"), field_names=["full_text"], query_dict=query_dict )
在这里,您创建了一个Reader,它从指定的集合和数据库中加载数据。它在每个对象的特定键集中查找文本。在这种情况下,我们只给了它一个键:"full_text"。最后一个参数是一个mongo 查询文档,这是一个JSON对象,您可以用它来将对象过滤到一个子集。我们将其留空,因为我们想要集合中的所有推文。
# 创建新客户端并连接到服务器 client = MongoClient(os.getenv("MONGODB_URI"), server_api=ServerApi('1')) # 创建Atlas作为向量存储 store = MongoDBAtlasVectorSearch( client, db_name=os.getenv('MONGODB_DATABASE'), collection_name=os.getenv('MONGODB_VECTORS'), index_name=os.getenv('MONGODB_VECTOR_INDEX') )
现在您正在为Mongo创建一个向量搜索客户端。除了MongoDB客户端对象外,您还要再次告诉它所有内容所在的数据库。这次您给它提供了存储向量嵌入的集合名称,以及下一步将创建的向量搜索索引的名称。
这个过程可能需要一段时间,所以当我们开始时,我们将show_progress参数设置为True,这会打印一个方便的小进度条:
storage_context = StorageContext.from_defaults(vector_store=store) index = VectorStoreIndex.from_documents( documents, storage_context=storage_context, show_progress=True )
创建向量搜索索引
如果一切顺利,您现在应该能够登录Mongo Atlas UI,并在数据库中看到两个集合:原始数据在tiny_tweets_collection中,向量嵌入在tiny_tweets_vectors中。
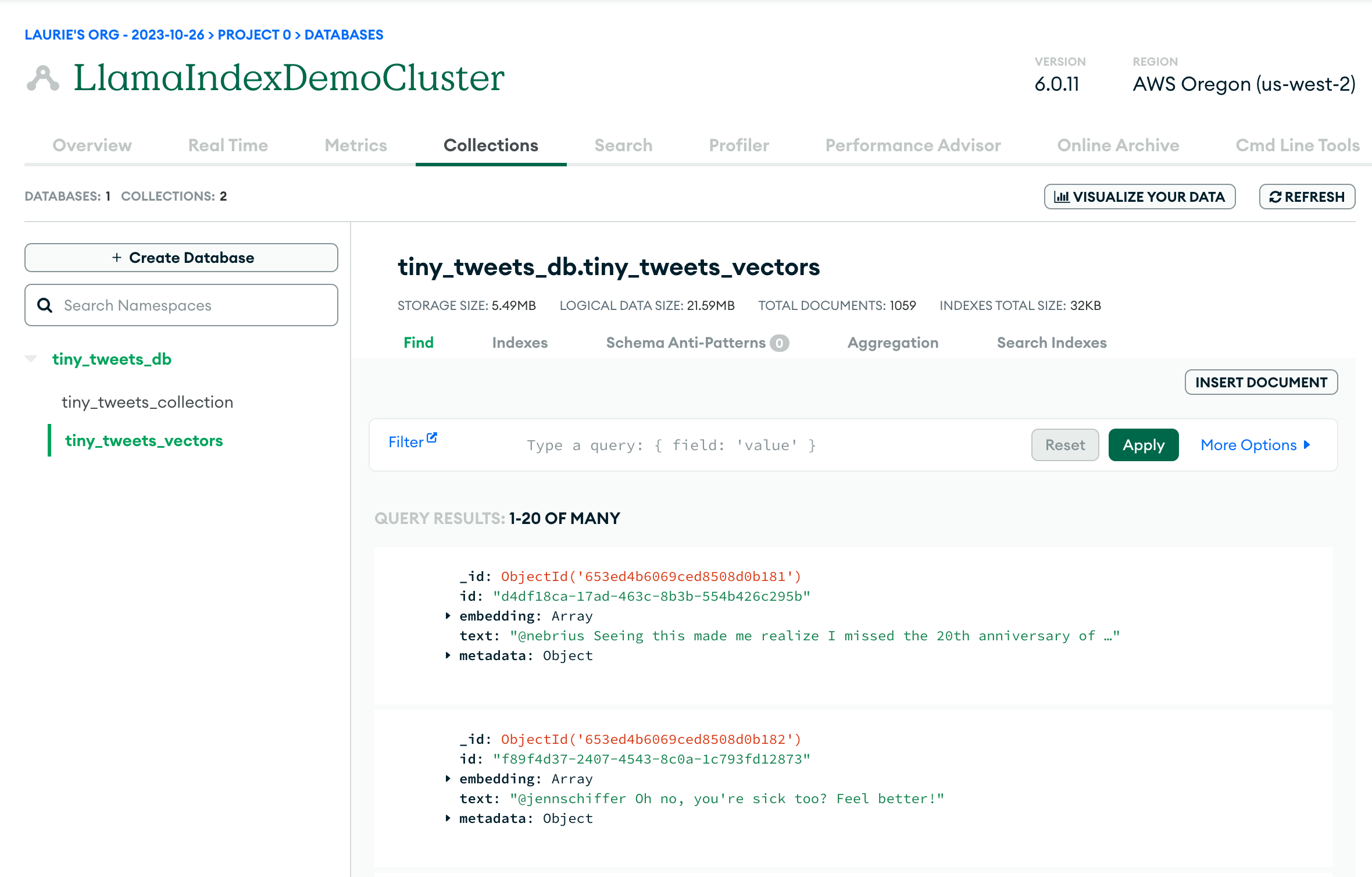
现在是时候创建向量搜索索引,以便您可以查询数据。首先,点击Search标签,然后点击"Create Search Index":
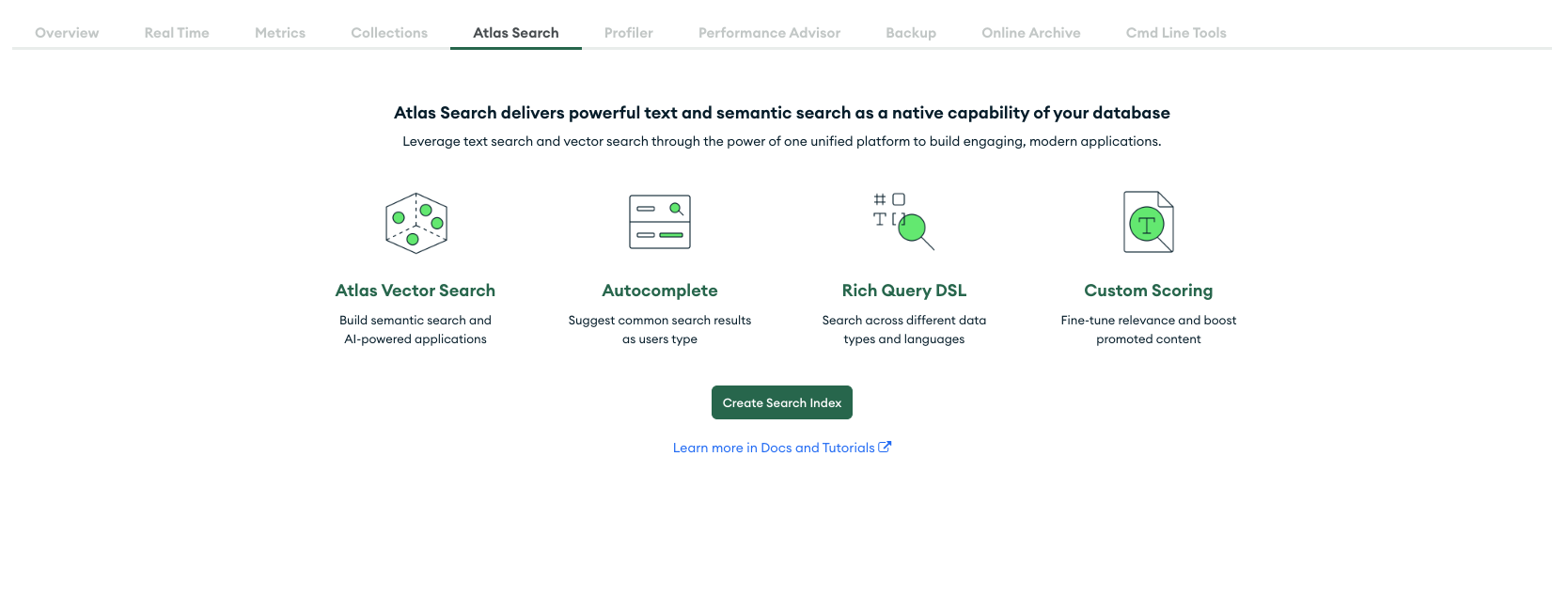
目前还不能使用可视��化编辑器创建向量搜索索引,所以选择JSON编辑器:
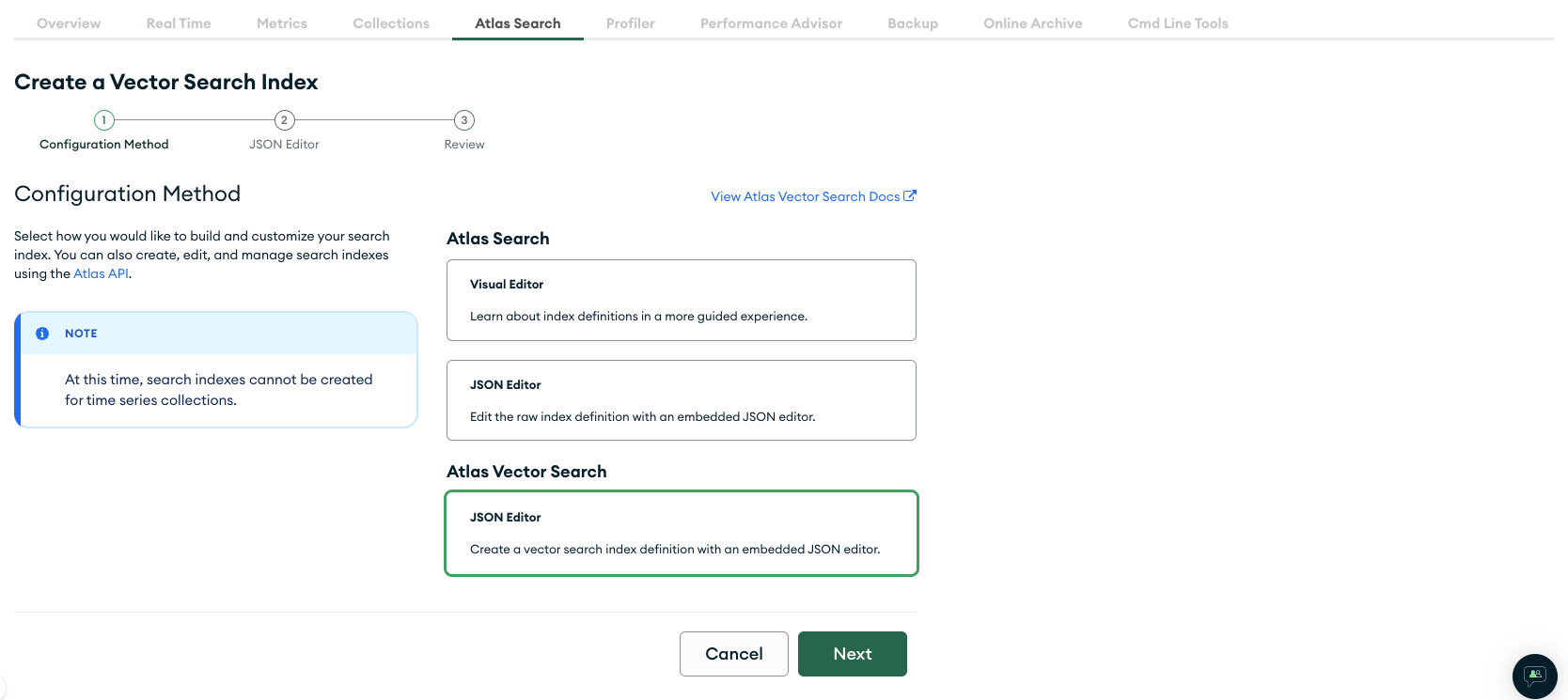
现在在"database and collection"下选择tiny_tweets_db,然后在其中选择tiny_tweets_vectors。然后在"Index name"下输入tiny_tweets_vector_index(或您在.env中为MONGODB_VECTOR_INDEX设置的任何值)。在下面,您需要输入这个JSON对象:
{ "fields": [ { "numDimensions": 1536, "path": "embedding", "similarity": "cosine", "type": "vector" } ] }
这告诉Mongo,每个文档(在tiny_tweets_vectors集合中)的embedding字段是一个1536维的向量(这是OpenAI使用的嵌入大小),并且我们想要使用余弦相似度来比较向量。除非您想使用完全不同于OpenAI的LLM,否则您不需要太关心这些值。
UI 会要求您检查并确认您的选择,然后您需要等待一两分钟,让它生成索引。如果一切顺利,您应该会看到类似这样的屏幕:
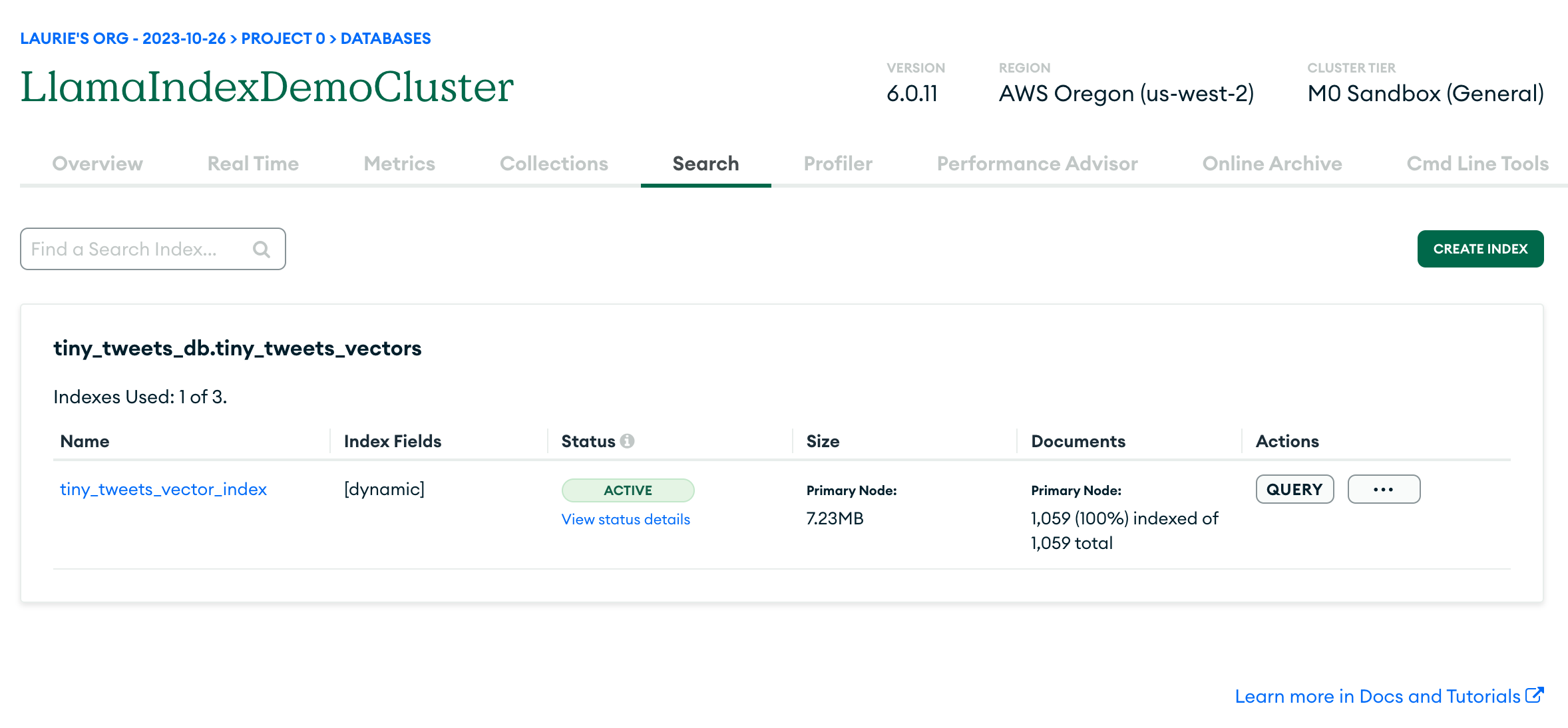
现在您已经准备好查��询您的数据了!
运行测试查询
您可以通过运行以下命令来实现:
python 3_query.py
这会像 2_load_and_index.py 一样设置与 Atlas 的连接,然后创建一个查询引擎并对其运行查询:
query_engine = index.as_query_engine(similarity_top_k=20) response = query_engine.query("作者对 Web 框架有什么看法?") print(response)
如果一切正常,您应该会得到一个关于 Web 框架的细致见解。
设置新的仓库
现在我们有了一种使用 LLM 快速查询数据的方法。但我们需要一个应用程序!为此,我们将设置一个 Python Flask API 作为后端,一个 JavaScript Next.js 应用作为前端。我们将把它们都部署到 Render,为此我们需要将它们放在一个 GitHub 仓库中。所以让我们来做这个:
- 创建一个新的公开 GitHub 仓库
- 将它克隆到您的本地机器
- 将此仓库中的所有文件复制到新�仓库(确保不包含
.git文件夹) - 提交并推送文件到 GitHub
在本教程的其余部分,我们假设您正在您刚刚创建的文件夹中工作,该文件夹与您控制的仓库相关联。
运行 Flask API
创建 Flask 应用的细节超出了本教程的范围,但您可以在仓库的 flask_app 中找到一个已经设置好的应用。它像我们在 3_query.py 中那样设置 Mongo Atlas 客户端,并有一个真正的方法 process_form,它接受一个 query 参数:
@app.route('/process_form', methods=['POST']) @cross_origin() def process_form(): query = request.form.get('query') if query is not None: # 这里我们自定义了每次查询返回的文档数量为 20,因为推文非常短 query_engine = index.as_query_engine(similarity_top_k=20) response = query_engine.query(query) return jsonify({"response": str(response)}) else: return jsonify({"error": "缺少 query 字段"}), 400
(@cross_origin() 装饰器是必要的,以允许前端向 API 发出请求。)
您可以通过运行以下命令在本地运行它:
flask run
您可以通过在浏览器中访问 http://127.0.0.1:5000 来检查它是否正在运行。您应该会得到一个 "Hello, world!" 响应。
将 Flask API 部署到 Render
设置 Render 账户(我们建议使用您的 GitHub 账户登录,以简化操作)并创建一个新的 Web 服务:
- 选择 "从 GitHub 仓库构建和部署",然后选择您上面创建的仓库。
- 给服务一个唯一的名称
- �将根目录设置为
flask_app - 将运行时设置为 Python 3
- 选择免费套餐
重要:设置 PYTHON_VERSION。您的第一次部署会失败,因为一些包无法找到,要解决这个问题,请将您的 Python 版本设置为与您本地使用的版本相同:
- 转到 "Environment"
- 选择 "Add environment variable"
- 将
key设置为PYTHON_VERSION,值设置为3.11.6(或您本地使用的任何版本) - 点击 "save changes"
- 转到右上角的 "Deploy" 按钮,选择 "deploy latest commit"。现在应该可以成功部署了。
将您的 .env 环境变量添加到 Render
以与设置 PYTHON_VERSION 相同的方式,您现在应该在 Render 环境中设置 .env 文件中的所有其他环境变量。您的代码需要知道在哪里连接 Mongo 等。所以它最终应该看起来像这样:
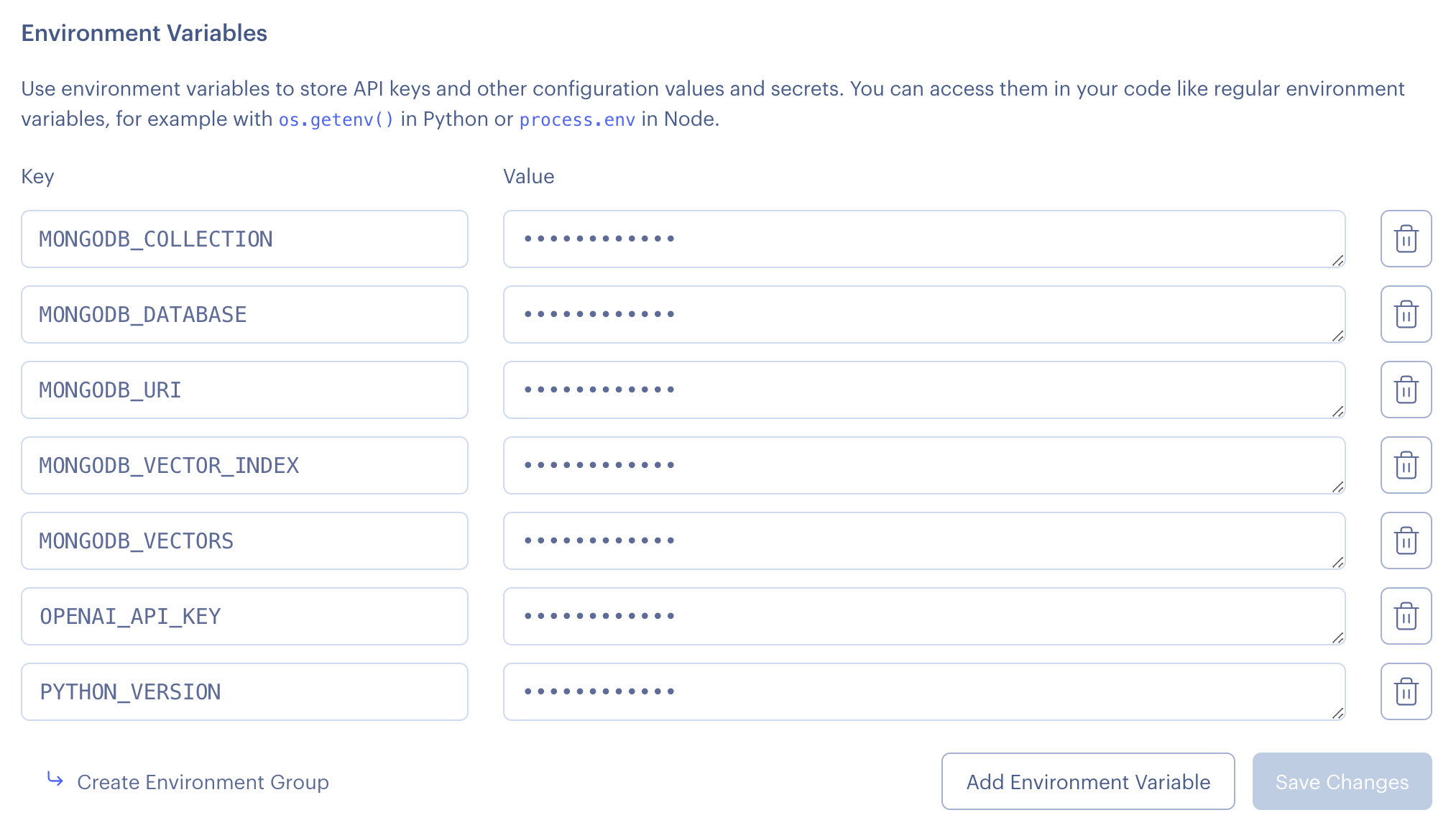
将您的应用 IP 添加到 MongoDB Atlas
为了允许您的 API 连接到 MongoDB,您需要将其 IP 地址添加到 Mongo 允许连接的 IP 列表中。您可以在 Render 右上角的 "Connect" 按钮中找到这些 IP。
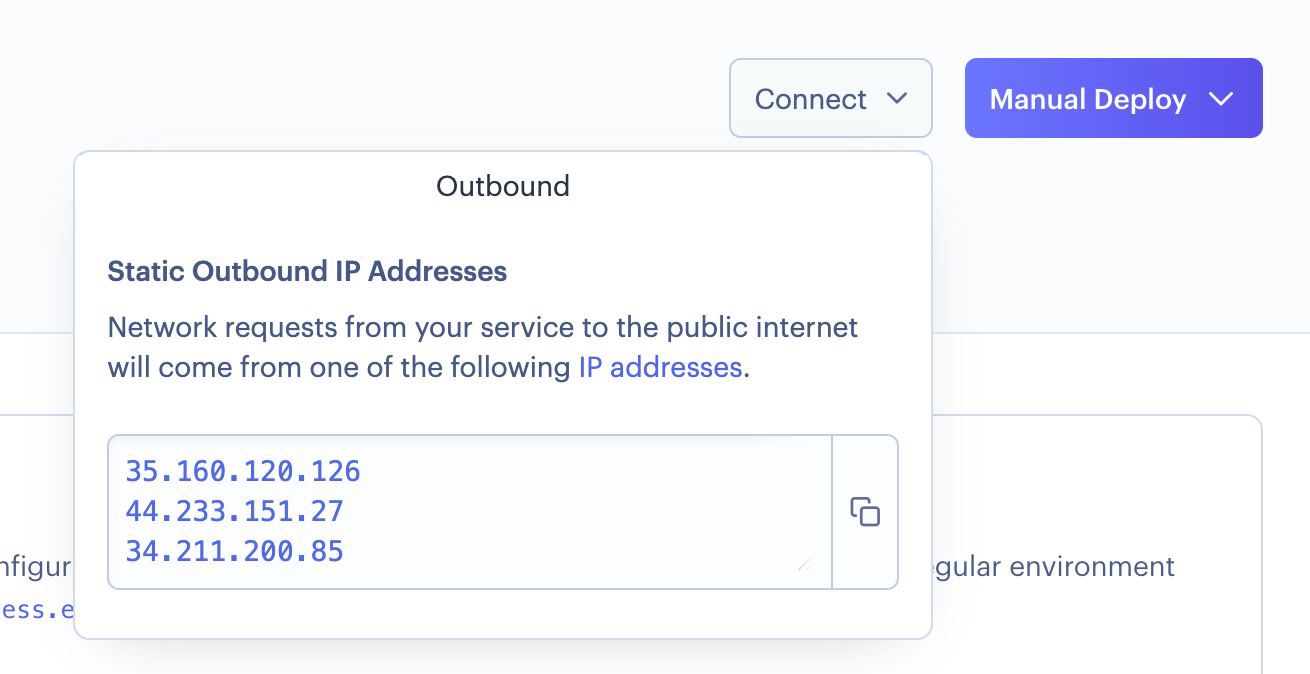
转到 MongoDB 的 UI,从左侧菜单的 "Security" 下选择 "Network Access"。点击 "Add IP address" 三次,每次添加 Render 提供的一个 IP。
完成所有这些后,您的 API 现在应该已经启动并运行,并且能够连接到 MongoDB。是时候构建前端了!
运行 Next.js 应用
就像 Flask 应用一样,我们已经为您完成了繁重的工作,您可以在 next_app 中找到该应用。要在本地运行它,请在 Next 应用的根目录下运行以下命令:
npm install npm run dev
这将在 http://127.0.0.1:3000 上给您一个本地服务器。如果您已经运行了 Flask API,您应该能够运行查询了!
将 Next.js 应用部署到 Render
就像 Flask 应用一样,我们将在免费计划上将 Next.js 应用部署到 Render。步骤非常相似:
- 选择 "从 GitHub 仓库构建和部署",然后选择您上面创建的仓库。
- 给服务一个唯一的名称
- 将根目录设置为
next_app - 将运行时设置为 Node.js
- 选择免费套餐
为 Next.js 设置环境变量
就像 Python 一样�,您需要设置一个名为 NODE_VERSION 的环境变量,将其设置为 20,并重新构建您的第一次部署。
您还需要告诉它在哪里找到 Flask API。为此,创建一个名为 NEXT_PUBLIC_API_HOST 的环境变量,并将其设置为 Render 上 Flask API 的主机名(在我们的例子中,是 https://mongodb-demo-zpxu.onrender.com/)。
您不需要设置任何其他环境变量,只有您的 Flask API 需要知道如何连接到 Mongo。
重新部署您的 Next.js 应用。
庆祝!
如果一切顺利,您现在应该有一个像我们一样的演示应用了!您可以开始根据您的用例进行自定义了。
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用��开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序�、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适�应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号