



导师:结构化的大型语言模型输出
Instructor是一个Python库,使处理大型语言模型(LLMs)的结构化输出变得轻而易举。它构建于Pydantic之上,提供了一个简单、透明且用户友好的API,用于管理验证、重试和流式响应。准备好为您的LLM工作流加速吧!



想要您的公司徽标出现在我们的网站上吗?
如果您的公司大量使用Instructor,我们很乐意将您的徽标展示在我们的网站上!请填写这个表格
主要功能
- 响应模型:指定Pydantic模型以定义您的LLM输出结构
- 重试管理:轻松配置请求的重试次数
- 验证:使用Pydantic验证确保LLM响应符合您的预期
- 流支持:轻松处理列表和部分响应
- 灵活的后端:无缝集成各种LLM提供商,不仅限于OpenAI
- 支持多种语言:我们支持包括Python、TypeScript、Ruby、Go和Elixir在内的多种语言
几分钟内开始使用
只需一个命令即可安装Instructor:
pip install -U instructor
现在,让我们通过一个简单的示例来看一下Instructor的实际应用:
import instructor from pydantic import BaseModel from openai import OpenAI # 定义所需的输出结构 class UserInfo(BaseModel): name: str age: int # 修补OpenAI客户端 client = instructor.from_openai(OpenAI()) # 从自然语言中提取结构化数据 user_info = client.chat.completions.create( model="gpt-3.5-turbo", response_model=UserInfo, messages=[{"role": "user", "content": "John Doe is 30 years old."}], ) print(user_info.name) #> John Doe print(user_info.age) #> 30
使用Anthropic模型
import instructor from anthropic import Anthropic from pydantic import BaseModel class User(BaseModel): name: str age: int client = instructor.from_anthropic(Anthropic()) # 注意client.chat.completions.create也会有效 resp = client.messages.create( model="claude-3-opus-20240229", max_tokens=1024, system="You are a world class AI that excels at extracting user data from a sentence", messages=[ { "role": "user", "content": "Extract Jason is 25 years old.", } ], response_model=User, ) assert isinstance(resp, User) assert resp.name == "Jason" assert resp.age == 25
使用Cohere模型
确保安装cohere并通过export CO_API_KEY=<YOUR_COHERE_API_KEY>设置您的系统环境变量。
pip install cohere
import instructor import cohere from pydantic import BaseModel class User(BaseModel): name: str age: int client = instructor.from_cohere(cohere.Client()) # 注意client.chat.completions.create也会有效 resp = client.chat.completions.create( model="command-r-plus", max_tokens=1024, messages=[ { "role": "user", "content": "Extract Jason is 25 years old.", } ], response_model=User, ) assert isinstance(resp, User) assert resp.name == "Jason" assert resp.age == 25
使用Gemini模型
确保您已安装Google AI Python SDK。您应使用API密钥设置GOOGLE_API_KEY环境变量。
pip install google-generativeai
import instructor import google.generativeai as genai from pydantic import BaseModel class User(BaseModel): name: str age: int # genai.configure(api_key=os.environ["API_KEY"]) # 备用API密钥配置 client = instructor.from_gemini( client=genai.GenerativeModel( model_name="models/gemini-1.5-flash-latest", # 默认模型为"gemini-pro" ), mode=instructor.Mode.GEMINI_JSON, )
或者,您可以通过OpenAI客户端调用Gemini。您需要设置gcloud,在Vertex AI上进行设置,并安装Google Auth库。
pip install google-auth
import google.auth import google.auth.transport.requests import instructor from openai import OpenAI from pydantic import BaseModel creds, project = google.auth.default() auth_req = google.auth.transport.requests.Request() creds.refresh(auth_req) # 将Vertex端点和身份验证传递给OpenAI SDK PROJECT = 'PROJECT_ID' LOCATION = ( 'LOCATION' # https://cloud.google.com/vertex-ai/generative-ai/docs/learn/locations ) base_url = f'https://{LOCATION}-aiplatform.googleapis.com/v1beta1/projects/{PROJECT}/locations/{LOCATION}/endpoints/openapi' client = instructor.from_openai( OpenAI(base_url=base_url, api_key=creds.token), mode=instructor.Mode.JSON ) # JSON模式是必须的 class User(BaseModel): name: str age: int resp = client.chat.completions.create( model="google/gemini-1.5-flash-001", max_tokens=1024, messages=[ { "role": "user", "content": "Extract Jason is 25 years old.", } ], response_model=User, ) assert isinstance(resp, User) assert resp.name == "Jason" assert resp.age == 25
使用Litellm
import instructor from litellm import completion from pydantic import BaseModel class User(BaseModel): name: str age: int client = instructor.from_litellm(completion) resp = client.chat.completions.create( model="claude-3-opus-20240229", max_tokens=1024, messages=[ { "role": "user", "content": "Extract Jason is 25 years old.", } ], response_model=User, ) assert isinstance(resp, User) assert resp.name == "Jason" assert resp.age == 25
类型推断正确
这曾是Instructor的梦想,但由于OpenAI的修补,我无法让类型正常工作。现在,使用新客户端,我们可以让类型正常工作了!我们还添加了一些create_*方法,使创建迭代器和部分项以及访问原始完成项变得更容易。
调用create
import openai import instructor from pydantic import BaseModel class User(BaseModel): name: str age: int client = instructor.from_openai(openai.OpenAI())
源代码如下:
user = client.chat.completions.create( model="gpt-4-turbo-preview", messages=[ {"role": "user", "content": "Create a user"}, ], response_model=User, )
现在,如果你使用IDE,你可以看到类型被正确地推断出来。
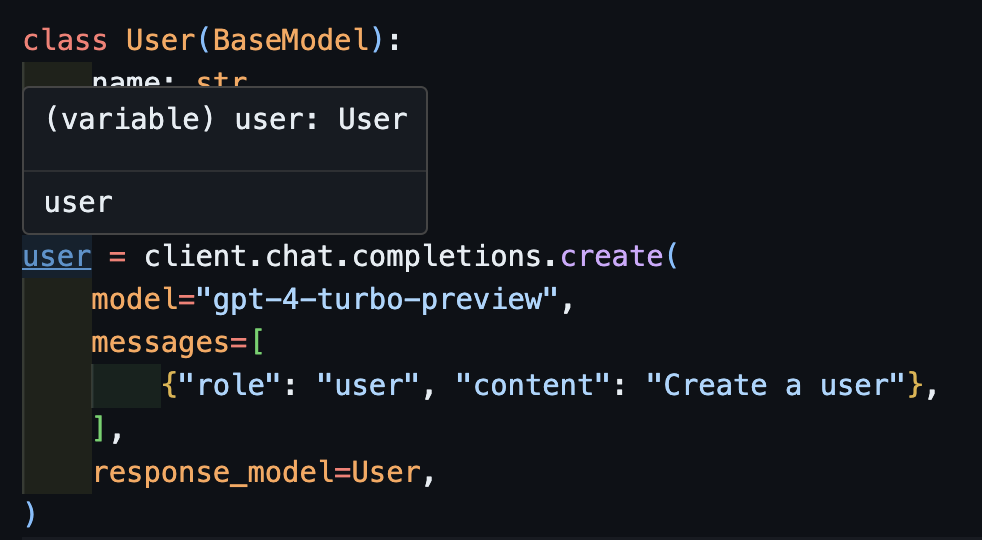
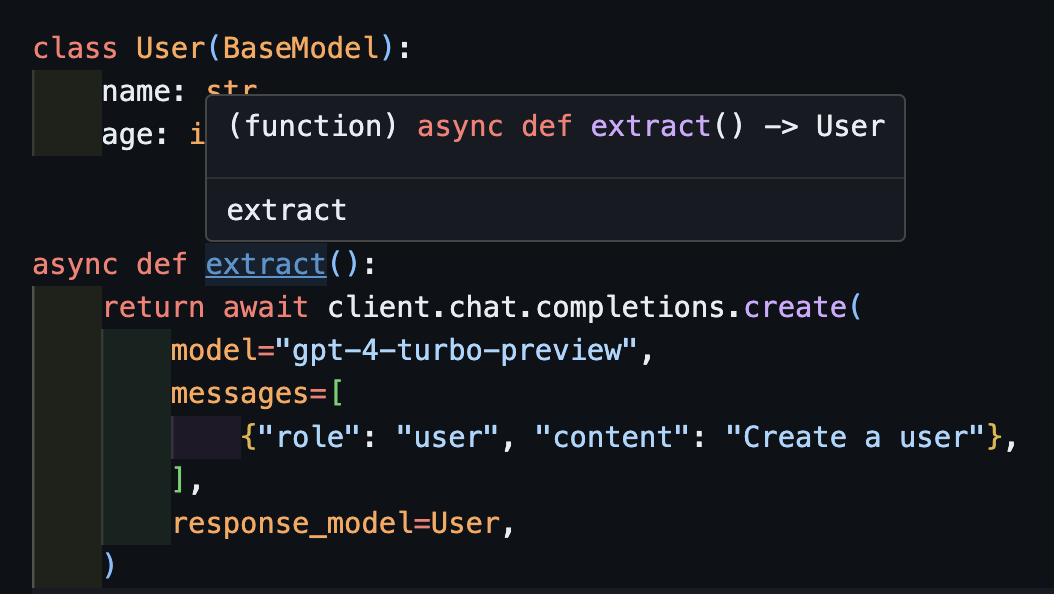
处理异步:await create
这也可以与异步客户端正确配合使用。
import openai import instructor from pydantic import BaseModel client = instructor.from_openai(openai.AsyncOpenAI()) class User(BaseModel): name: str age: int async def extract(): return await client.chat.completions.create( model="gpt-4-turbo-preview", messages=[ {"role": "user", "content": "Create a user"}, ], response_model=User, )
注意,因为我们返回了create方法,所以extract()函数将返回正确的用户类型。
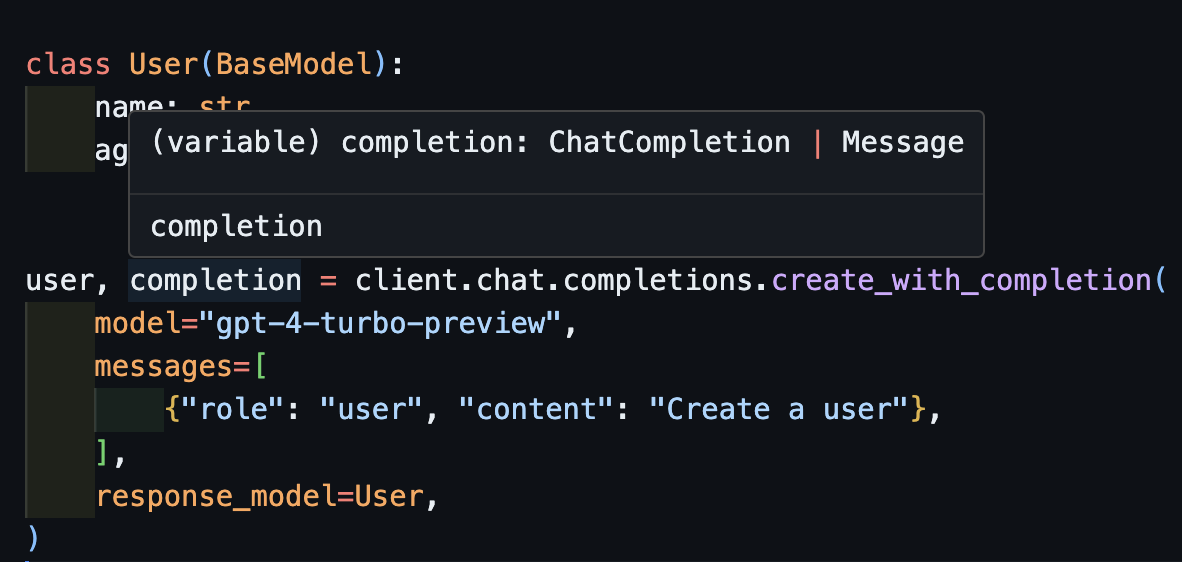
返回原始的完成对象:create_with_completion
你也可以返回原始的完成对象。
import openai import instructor from pydantic import BaseModel client = instructor.from_openai(openai.OpenAI()) class User(BaseModel): name: str age: int user, completion = client.chat.completions.create_with_completion( model="gpt-4-turbo-preview", messages=[ {"role": "user", "content": "Create a user"}, ], response_model=User, )
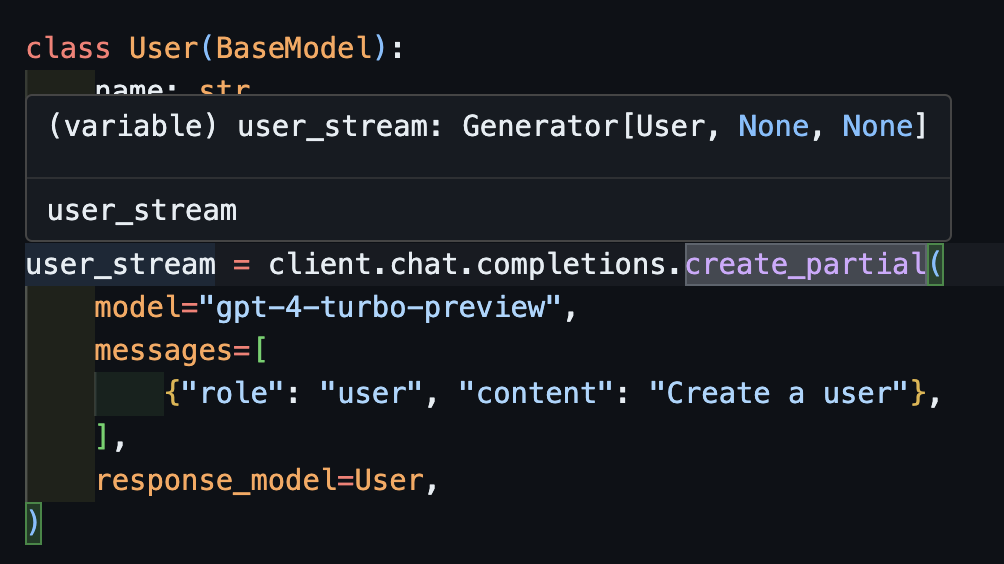
流式传输部分对象:create_partial
为了处理流,我们仍然支持Iterable[T]和Partial[T],但为了简化类型推断,我们还增加了create_iterable和create_partial方法!
import openai import instructor from pydantic import BaseModel client = instructor.from_openai(openai.OpenAI()) class User(BaseModel): name: str age: int user_stream = client.chat.completions.create_partial( model="gpt-4-turbo-preview", messages=[ {"role": "user", "content": "Create a user"}, ], response_model=User, ) for user in user_stream: print(user) #> name=None age=None #> name=None age=None #> name=None age=None #> name=None age=None #> name=None age=None #> name=None age=None #> name='John Doe' age=None #> name='John Doe' age=None #> name='John Doe' age=None #> name='John Doe' age=30 #> name='John Doe' age=30 # name=None age=None # name='' age=None # name='John' age=None # name='John Doe' age=None # name='John Doe' age=30
现在注意到,推断出的类型是Generator[User, None]
流式迭代器:create_iterable
当我们想要提取多个对象时,我们会得到一个对象的可迭代器。
import openai import instructor from pydantic import BaseModel client = instructor.from_openai(openai.OpenAI()) class User(BaseModel): name: str age: int users = client.chat.completions.create_iterable( model="gpt-4-turbo-preview", messages=[ {"role": "user", "content": "Create 2 users"}, ], response_model=User, ) for user in users: print(user) #> name='John Doe' age=30 #> name='Jane Doe' age=28 # User(name='John Doe', age=30) # User(name='Jane Smith', age=25)
Evals
我们邀请您贡献在pytest中的evals,用以监控OpenAI模型和instructor库的质量。要开始使用,请查看anthropic和OpenAI的evals,并以pytest测试的形式贡献您自己的evals。这些evals将每周运行一次,并公布结果。
贡献
如果你想帮助,请查看一些标记为good-first-issue或help-wanted的问题。它们可能包括代码改进、客座博客文章或新食谱。
命令行界面 (CLI)
我们还提供了一些额外的CLI功能,方便使用:
-
instructor jobs:帮助创建OpenAI的微调任务。简单地使用instructor jobs create-from-file --help开始创建您的第一个微调的GPT3.5模型。 -
instructor files:轻松管理您上传的文件。您可以从命令行创建、删除和上传文件。 -
instructor usage:您可以直接从CLI监控您的使用情况并按日期和时间段进行过滤,而无需每次都访问OpenAI网站。请注意,使用数据通常需要约5-10分钟才能从OpenAI更新。
许可证
本项目依据MIT许可证授权。
贡献者
<!-- ALL-CONTRIBUTORS-LIST:START - Do not remove or modify this section --> <!-- prettier-ignore-start --> <!-- markdownlint-disable --> <!-- markdownlint-restore --> <!-- prettier-ignore-end --> <!-- ALL-CONTRIBUTORS-LIST:END --> <a href="https://github.com/jxnl/instructor/graphs/contributors"> <img src="https://contrib.rocks/image?repo=jxnl/instructor" /> </a>编辑推荐精选


GPT Plus|Pro充值
GPT充值
支持 ChatGPT Plus / Pro 充值服务,支付便捷,自动发货,售后可查。


GPT Image 2中文站
AI 图片生成平台
GPT Image 2 是面向用户的 AI 图片生成平台,支持文生图、图生图及多模型创意工作流。


Vecbase
你的AI Agent团队
Vecbase 是专为 AI 团队打造的智能工作空间,将数据管理、模型协作与知识沉淀整合于一处。算法、产品与业务在同一平台无缝协同,让从数据到 AI 应用的落地更快一步。


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


QoderWork
阿里Qoder团队推出的桌面端AI智能体
QoderWork 是阿里推出的本地优先桌面 AI 智能体,适配 macOS14+/Windows10+,以自然语言交互实现文件管理、数据分析、AI 视觉生成、浏览器自动化等办公任务,自主拆解执行复杂工作流,数据本地运行零上传,技能市场可无限扩展,是高效的 Agentic 生产力办公助手。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料�,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。


seedancetwo2.0
能听懂你表达的视频模型
Seedance two是基于seedance2.0的中国大模型,支持图像、视频、音频、文本四种模态输入,表达方式更丰富,生成也更可控。


nano-banana纳米香蕉中文站
国内直接访问,限时3折
输入简单文字,生成想要的图片,纳米香蕉中文站基于 Google 模型的 AI 图片生成网站,支持文字生图、图生图。官网价格限时3折活动


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!
推荐工具精选





AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号