
hiera
简洁高效的分层视觉Transformer模型
Hiera是一种分层视觉Transformer模型,在图像和视频任务中表现出色,同时保持高效推理。该模型简化了现有Transformer的复杂模块,并通过MAE预训练学习空间偏置,实现了简洁高效的架构。项目提供了模型库、推理示例和基准测试脚本,支持通过PyTorch Hub和Hugging Face Hub使用预训练模型。



Hiera:一个没有繁琐设计的分层视觉 Transformer


这是我们 ICML 2023 口头报告论文的官方实现: [Hiera:一个没有繁琐设计的分层视觉 Transformer][arxiv-link] Chaitanya Ryali*, Yuan-Ting Hu*, Daniel Bolya*, Chen Wei, Haoqi Fan, Po-Yao Huang, Vaibhav Aggarwal, Arkabandhu Chowdhury, Omid Poursaeed, Judy Hoffman, Jitendra Malik, Yanghao Li*, Christoph Feichtenhofer* [ICML '23 口头报告][icml-link] | GitHub | [arXiv][arxiv-link] | BibTeX
*:同等贡献。
Hiera 是什么?
Hiera 是一个快速、强大且最重要的是简单的分层视觉 Transformer。它在各种图像和视频任务中的表现优于最先进的模型,同时速度更快。
<p align="center"> <img src="https://yellow-cdn.veclightyear.com/835a84d5/f1e95409-50b1-475d-aca7-536337344367.png" width="75%"> </p>它是如何工作的?
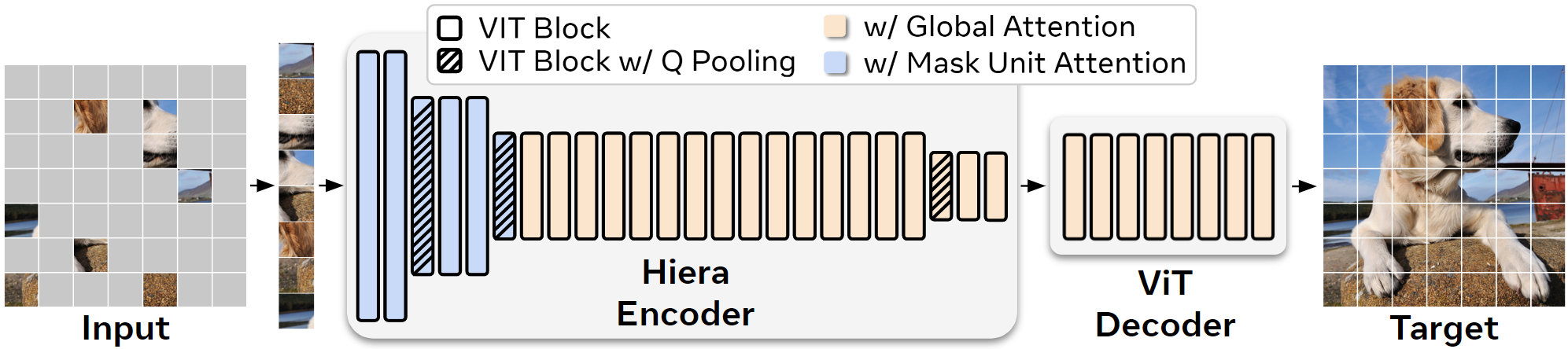
像 ViT 这样的视觉 Transformer 在整个网络中使用相同的空间分辨率和特征数量。但这是低效的:早期层不需要那么多特征,而后期层不需要那么高的空间分辨率。像 ResNet 这样的先前分层模型考虑到了这一点,在开始时使用较少的特征,在结束时使用较低的空间分辨率。
已经引入了几个采用这种分层设计的特定领域视觉 Transformer,如 Swin 或 MViT。但在追求使用 ImageNet-1K 全监督训练的最先进结果的过程中,这些模型变得越来越复杂,因为它们添加了专门的模块来弥补 ViT 缺乏的空间偏置。虽然这些变化产生了具有吸引人的 FLOP 计数的有效模型,但在底层,增加的复杂性使这些模型整体上变得更慢。
我们表明,这些庞大的结构中很多实际上是不必要的。我们选择教导模型这些偏置,而不是通过架构更改手动添加空间基础。通过使用 MAE 进行训练,我们可以简化或删除现有 Transformer 中所有这些笨重的模块,同时提高准确性。结果就是 Hiera,一个极其高效和简单的架构,在几个图像和视频识别任务中的表现优于最先进的模型。
新闻
- [2024.03.02] 代码许可变得更加宽松(Apache 2.0)!模型许可保持不变。
- [2023.06.12] 增加了更多 in1k 模型和一些视频示例,请参见 inference.ipynb(v0.1.1)。
- [2023.06.01] 初始发布。
有关更多详细信息,请参阅 changelog。
安装
Hiera 需要较新版本的 torch。 之后,你可以通过 pip 安装 hiera:
pip install hiera-transformer
本仓库 应该 支持最新版本的 timm,但 timm 是一个不断更新的包。如果你在使用较新版本的 timm 时遇到问题,请创建一个 issue。
从源代码安装
如果使用 torch hub,你不需要安装 hiera 包。但是,如果你想使用 hiera 进行开发,最好从源代码安装:
git clone https://github.com/facebookresearch/hiera.git cd hiera python setup.py build develop
模型库
注意,模型权重的发布许可与代码不同。更多详情请参阅 模型许可。
Torch Hub
这里我们提供了 Hiera 的模型检查点。即使没有安装 hiera-transformer 包,每个列出的模型也可以在 torch hub 上访问,例如,以下代码初始化一个在 ImageNet-1k 上预训练和微调的基础模型:
model = torch.hub.load("facebookresearch/hiera", model="hiera_base_224", pretrained=True, checkpoint="mae_in1k_ft_in1k")
如果你只想要 MAE 预训练的模型,可以将检查点替换为 "mae_in1k"。此外,如果你想同时加载 MAE 解码器(例如,继续预训练),请在模型名称前加上 mae_,例如:
model = torch.hub.load("facebookresearch/hiera", model="mae_hiera_base_224", pretrained=True, checkpoint="mae_in1k")
注意: 我们的 MAE 模型是使用 归一化像素损失 训练的。这意味着在网络预测补丁之前,补丁已经被归一化。如果你想可视化预测结果,你需要使用可见的补丁(这可能有效但不完美)或使用真实值来反归一化它们。有关更多模型名称和相应的检查点名称,请参见下文。
Hugging Face Hub
本仓库也支持 🤗 hub。安装 hiera-transformer 和 huggingface-hub 包后,你可以简单地运行,例如:
from hiera import Hiera model = Hiera.from_pretrained("facebook/hiera_base_224.mae_in1k_ft_in1k") # mae 预训练然后 in1k 微调的模型 model = Hiera.from_pretrained("facebook/hiera_base_224.mae_in1k") # 仅 mae 预训练,无微调
来加载模型。使用下面模型库中的 <模型名称>.<检查点名称>。
如果你想保存模型,请使用 model.config 作为配��置,例如:
model.save_pretrained("hiera-base-224", config=model.config)
图像模型
| 模型 | 模型名称 | 预训练模型<br>(IN-1K MAE) | 微调模型<br>(IN-1K 监督) | IN-1K<br>Top-1 (%) | A100 fp16<br>速度 (图像/秒) |
|---|---|---|---|---|---|
| Hiera-T | hiera_tiny_224 | mae_in1k | mae_in1k_ft_in1k | 82.8 | 2758 |
| Hiera-S | hiera_small_224 | mae_in1k | mae_in1k_ft_in1k | 83.8 | 2211 |
| Hiera-B | hiera_base_224 | mae_in1k | mae_in1k_ft_in1k | 84.5 | 1556 |
| Hiera-B+ | hiera_base_plus_224 | mae_in1k | mae_in1k_ft_in1k | 85.2 | 1247 |
| Hiera-L | hiera_large_224 | mae_in1k | mae_in1k_ft_in1k | 86.1 | 531 |
| Hiera-H | hiera_huge_224 | mae_in1k | mae_in1k_ft_in1k | 86.9 | 274 |
| 每个模型输入一个224x224的图像。 |
视频模型
| 模型 | 模型名称 | 预训练模型<br>(K400 MAE) | 微调模型<br>(K400) | K400 (3x5 views)<br>Top-1 (%) | A100 fp16<br>速度 (clip/s) |
|---|---|---|---|---|---|
| Hiera-B | hiera_base_16x224 | mae_k400 | mae_k400_ft_k400 | 84.0 | 133.6 |
| Hiera-B+ | hiera_base_plus_16x224 | mae_k400 | mae_k400_ft_k400 | 85.0 | 84.1 |
| Hiera-L | hiera_large_16x224 | mae_k400 | mae_k400_ft_k400 | 87.3 | 40.8 |
| Hiera-H | hiera_huge_16x224 | mae_k400 | mae_k400_ft_k400 | 87.8 | 20.9 |
每个模型输入16个224x224的帧,时间步长为4。
**注意:**这里列出的速度是在不使用PyTorch优化的缩放点积注意力的情况下进行基准测试的。如果使用PyTorch 2.0或更高版本,你的推理速度可能会比这里列出的更快。
使用方法
这个仓库实现了用于推理的Hiera模型代码。这个仓库仍在进行中。以下是我们目前已经完成的和计划做的:
- 图像推理
- MAE实现
- 视频推理
- MAE实现
- 完整模型库
- 训练脚本
查看示例了解如何使用Hiera。
推理
查看examples/inference了解如何准备推理数据的示例。
使用torch hub或🤗 hub实例化模型,或者从源代码安装hiera并运行:
import hiera model = hiera.hiera_base_224(pretrained=True, checkpoint="mae_in1k_ft_in1k")
然后你可以像其他模型一样进行推理:
output = model(x)
视频推理的工作方式相同,只需使用16x224模型即可。
注意:为了提高效率,Hiera在网络开始时重新排序其tokens(参见hiera_utils.py中的Roll和Unroll模块)。因此,tokens在默认情况下不是按空间顺序排列的。如果你想使用中间特征图进行下游任务,在运行模型时传递return_intermediates标志:
output, intermediates = model(x, return_intermediates=True)
MAE推理
默认情况下,模型不包括MAE解码器。如果你想使用解码器或计算MAE损失,你可以通过运行以下代码实例化一个mae版本:
import hiera model = hiera.mae_hiera_base_224(pretrained=True, checkpoint="mae_in1k")
然后当你对模型进行推理时,它将返回一个包含(loss, predictions, labels, mask)的4元组,其中predictions和labels仅针对被删除的tokens。返回的mask如果token可见则为True,如果被删除则为False。你可以在推理过程中传递参数来改变掩码比例:
loss, preds, labels, mask = model(x, mask_ratio=0.6)
图像的默认掩码比例是0.6,但对于视频你应该传入0.9。详情请参阅论文。
**注意:**我们对MAE预训练使用归一化像素目标,这意味着在模型预测之前,每个patch都单独进行了归一化。因此,在可视化之前,你需要使用真实值对它们进行反归一化。详情请参见hiera_mae.py中的get_pixel_label_2d。
基准测试
我们提供了一个便于基准测试的脚本。查看examples/benchmark了解如何使用它。
缩放点积注意力
PyTorch 2.0引入了优化的缩放点积注意力,这可以大大加速transformer。我们在原始基准测试中没有使用它,但由于它是免费的速度提升,如果可用,这个仓库将自动使用它。要获得其好处,请确保你的torch版本是2.0或更高。
训练
即将推出。
引用
如果你在工作中使用了Hiera或这段代码,请引用:
@article{ryali2023hiera,
title={Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles},
author={Ryali, Chaitanya and Hu, Yuan-Ting and Bolya, Daniel and Wei, Chen and Fan, Haoqi and Huang, Po-Yao and Aggarwal, Vaibhav and Chowdhury, Arkabandhu and Poursaeed, Omid and Hoffman, Judy and Malik, Jitendra and Li, Yanghao and Feichtenhofer, Christoph},
journal={ICML},
year={2023}
}
许可证
本项目的代码根据Apache许可证2.0版授权,而模型权重则根据知识共享署名-非商业性使用4.0国际许可协议授权。
有关代码许可的更多详情,请参阅LICENSE文件;有关模型权重许可的更多详情,请参阅LICENSE.models文件。
贡献
编辑推荐精选


GPT Plus|Pro充值
GPT充值
支持 ChatGPT Plus / Pro 充值服务,支付便捷,自动发货,售后可查。


GPT Image 2中文站
AI 图片生成平台
GPT Image 2 是面向用户的 AI 图片生成平台,支持文生图、图生图及多模型创意工作流。


Vecbase
你的AI Agent团队
Vecbase 是专为 AI 团队打造的智能工作空间,将数据管理、模型协作与知识沉淀整合于一处。算法、产品与业务在同一平台无缝协同,让从数据到 AI 应用的落地更快一步。


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的�语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


QoderWork
阿里Qoder团队推出的桌面端AI智能体
QoderWork 是阿里推出的本地优先桌面 AI 智能体,适配 macOS14+/Windows10+,以自然语言交互实现文件管理、数据分析、AI 视觉生成、浏览器自动化等办公任务,自主拆解执行复杂工作流,数据本地运行零上传,技能市场可无限扩展,是高效的 Agentic 生产力办公助手。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。


seedancetwo2.0
能听懂你表达的视频模型
Seedance two是基于seedance2.0的中国大模型,支持图像、视频、音频、文本四�种模态输入,表达方式更丰富,生成也更可控。


nano-banana纳米香蕉中文站
国内直接访问,限时3折
输入简单文字,生成想要的图片,纳米香蕉中文站基于 Google 模型的 AI 图片生成网站,支持文字生图、图生图。官网价格限时3折活动


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!
推荐工具精选





AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号