



FMBench是一个Python包,用于对部署在任何AWS生成式AI服务上的任何基础模型(FM)进行性能基准测试和准确性评估,无论是部署在Amazon SageMaker、Amazon Bedrock、Amazon EKS还是Amazon EC2上。这些FM可以直接通过FMbench部署,或者如果它们已经部署,也可以通过FMBench支持的"使用自己的端点"模式进行基准测试。
以下是FMBench的一些显著特点:
-
高度灵活:它允许使用任何实例类型(
g5、p4d、p5、Inf2)、推理容器(DeepSpeed、TensorRT、HuggingFace TGI等)以及张量并行、滚动批处理等参数的组合,只要这些组合受底层平台支持。 -
可对任何模型进行基准测试:它可用于对开源模型、第三方模型以及企业使用自己数据训练的专有模型进行基准测试。基准测试包括性能基准测试和模型评估(基于真实标准的准确性测量)。🚨 新功能:在2.0.0版本中添加了由LLM评估员组成的评估小组进行模型评估 🚨
-
可在任何地方运行:它可以在任何可以运行Python的AWS平台上运行,如Amazon EC2、Amazon SageMaker,甚至AWS CloudShell。重要的是要在AWS平台上运行此工具,以确保互联网往返时间不会包含在端到端响应时间延迟中。
介绍视频
为您的生成式AI工作负载确定最佳价格|性能服务堆栈
使用FMBench在任何AWS生成式AI服务上对LLM进行价格和性能(推理延迟、每分钟事务数)的基准测试。�以下是FMBench生成的一个图表,用于帮助回答在Amazon SageMaker上托管的Llama2-13b模型的价格性能问题(图例中的实例类型已故意模糊处理,您可以在运行FMBench时生成的实际图表中找到它们)。

为您的生成式AI工作负载确定最佳模型
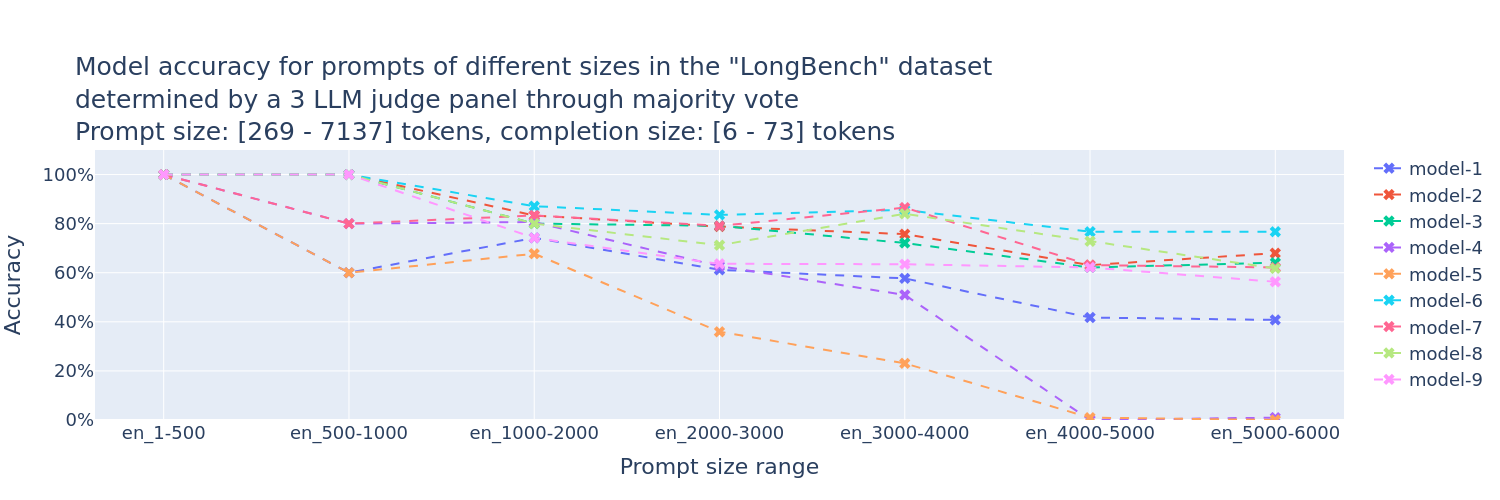
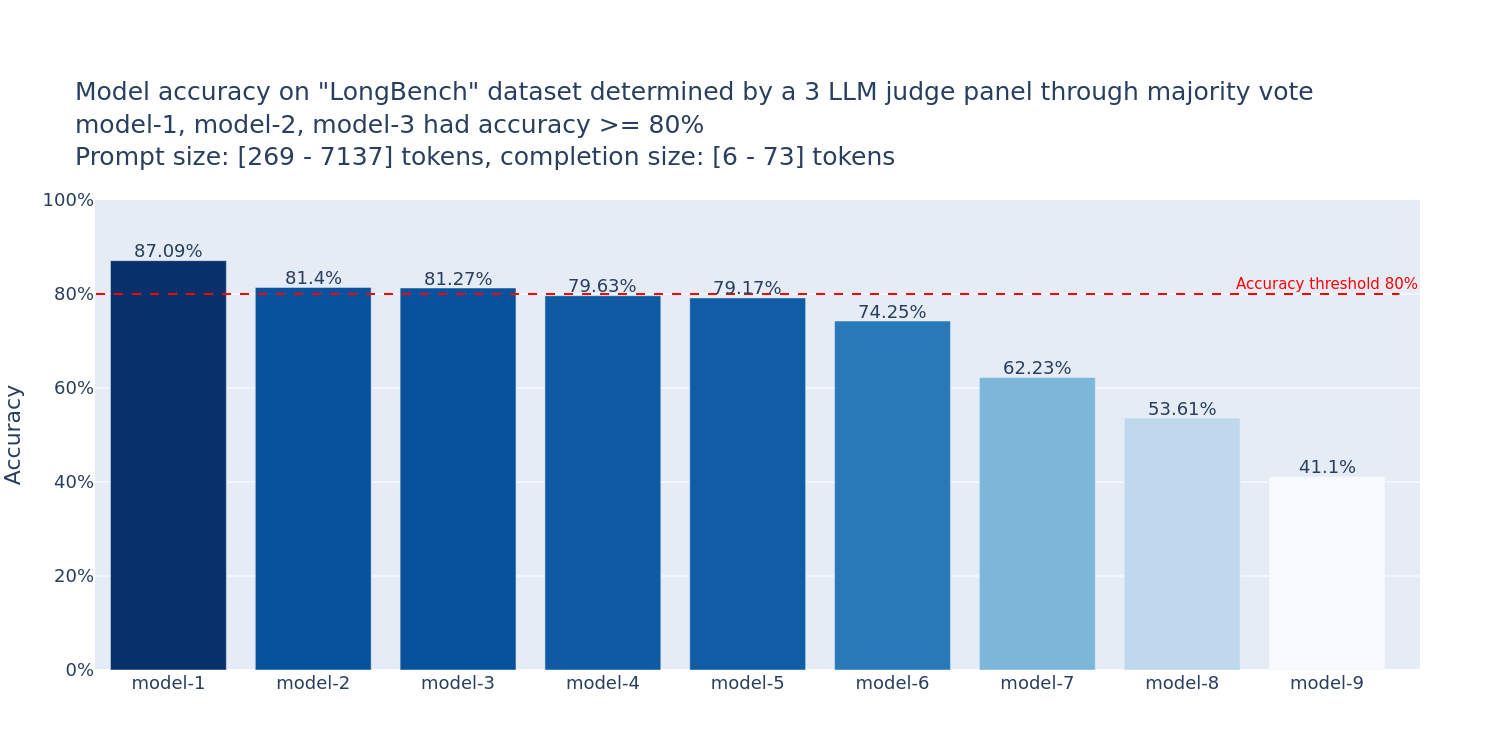
使用FMBench通过LLM评估员小组(PoLL [1])来确定模型准确性。以下是FMBench生成的一个图表,用于帮助回答Amazon Bedrock上各种FM的准确性问题(图表中的模型ID已故意模糊处理,您可以在运行FMBench时生成的实际图表中找到它们)。
已进行基准测试的模型
本仓库的configs文件夹中提供了以下模型的配置文件。
Amazon SageMaker上的Llama3
Llama3现已在SageMaker上可用(阅读博客文章),您现在可以使用FMBench对其进行基准测试。以下是在ml.p4d.24xlarge、ml.inf2.24xlarge和ml.g5.12xlarge实例上对Llama3-8b-instruct和Llama3-70b-instruct进行基准测试的配置文件。
Llama3-8b-instruct在ml.p4d.24xlarge和ml.g5.12xlarge上的配置文件。Llama3-70b-instruct在ml.p4d.24xlarge和ml.g5.48xlarge上的配置文件。Llama3-8b-instruct在ml.inf2.24xlarge和ml.g5.12xlarge上的配置文件。
所有基准测试模型完整列表
| 模型 | EC2 g5 | EC2 Inf2/Trn1 | SageMaker g4dn/g5/p3 | SageMaker Inf2/Trn1 | SageMaker P4 | SageMaker P5 | Bedrock 按需吞吐量 | Bedrock 预置吞吐量 |
|---|---|---|---|---|---|---|---|---|
| Anthropic Claude-3 Sonnet | ✅ | ✅ | ||||||
| Anthropic Claude-3 Haiku | ✅ | |||||||
| Mistral-7b-instruct | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| Mistral-7b-AWQ | ✅ | |||||||
| Mixtral-8x7b-instruct | ✅ | |||||||
| Llama3.1-8b instruct | ✅ | ✅ | ✅ | ✅ | ||||
| Llama3.1-70b instruct | ✅ | ✅ | ✅ | |||||
| Llama3-8b instruct | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| Llama3-70b instruct | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| Llama2-13b chat | ✅ | ✅ | ✅ | ✅ | ||||
| Llama2-70b chat | ✅ | ✅ | ✅ | ✅ | ||||
| Amazon Titan text lite | ✅ | |||||||
| Amazon Titan text express | ✅ | |||||||
| Cohere Command text | ✅ | |||||||
| Cohere Command light text | ✅ | |||||||
| AI21 J2 Mid | ✅ | |||||||
| AI21 J2 Ultra | ✅ | |||||||
| Gemma-2b | ✅ | |||||||
| Phi-3-mini-4k-instruct | ✅ | |||||||
| distilbert-base-uncased | ✅ |
本�次发布的新功能
2.0.3
- 支持在EC2上进行基准测试的EFA目录。
2.0.2
- 代码清理、小bug修复和报告改进。
2.0.0
- 🚨 模型评估由**LLM评估员小组[1]**完成 🚨
入门
FMBench作为Python包在PyPi上提供,安装后可作为命令行工具运行。所有包括指标、报告和结果在内的数据都存储在Amazon S3存储桶中。
[!重要] 💡
FMBench的所有文档都可在FMBench网站上获取 您可以在 SageMaker 笔记本或 EC2 虚拟机上运行FMBench。这两种选择在文档中都有详细说明。您甚至可以将FMBench作为Docker 容器运行。以下还提供了 SageMaker 的快速入门指南。
👉 以下部分讨论的是运行 FMBench 工具,与基础模型实际部署的位置不同。例如,我们可以在 EC2 上运行 FMBench,但被测试的模型可能部署在 SageMaker 或 Bedrock 上。
快速入门
在 SageMaker 笔记本上运行 FMBench
-
每次运行
FMBench都需要一个配置文件,其中包含有关模型、部署步骤和要运行的测试的信息。典型的FMBench工作流程包括直接使用FMBenchGitHub 仓库中configs文件夹中已提供的配置文件,或根据您自己的需求编辑已提供的配置文件(比如您想在不同的实例类型或使用不同的推理容器进行基准测试等)。👉 本仓库中包含一个简单的配置文件,其中标注了关键参数,请参见
config-llama2-7b-g5-quick.yml。该文件在ml.g5.xlarge实例和ml.g5.2xlarge实例上对 Llama2-7b 的性能进行基准测试。您可以按原样使用此配置文件进行快速入门。 -
使用下表中的按钮之一启动本仓库中包含的 AWS CloudFormation 模板。CloudFormation 模板在您的 AWS 账户中创建以下资源:Amazon S3 存储桶、Amazon IAM 角色和一个克隆了此仓库的 Amazon SageMaker 笔记本。创建的读取 S3 存储桶包含运行
FMBench所需的所有文件(配置文件、数据集),而创建的写入 S3 存储桶将存储FMBench生成的指标和报告。CloudFormation 堆栈创建大约需要 5 分钟。 -
CloudFormation 堆栈创建完成后,导航到 SageMaker 笔记本并打开
fmbench-notebook。 -
在
fmbench-notebook中打开终端并运行以下命令。conda create --name fmbench_python311 -y python=3.11 ipykernel source activate fmbench_python311; pip install -U fmbench -
现在您可以使用以下命令行运行
fmbench。我们将使用 CloudFormation 堆栈放置在 S3 存储桶中的示例配置文件进行快速首次运行。-
我们使用
huggingface-pytorch-tgi-inference推理容器,在ml.g5.xlarge和ml.g5.2xlarge实例类型上对Llama2-7b模型的性能进行基准测试。这个测试大约需要 30 分钟完成,花费约 0.20 美元。 -
它使用简单的 750 字等于 1000 个词元的关系来获得更准确的词元计数表示,要获得更准确的词元计数,请使用
Llama2 分词器(下一节提供了说明)。强烈建议为了获得更准确的词元吞吐量结果,您应该使用特定于正在测试的模型的分词器,而不是默认分词器。本文档后面提供了有关如何使用自定义分词器的说明。
-
account=`aws sts get-caller-identity | jq .Account | tr -d '"'`
region=`aws configure get region`
fmbench --config-file s3://sagemaker-fmbench-read-${region}-${account}/configs/llama2/7b/config-llama2-7b-g5-quick.yml > fmbench.log 2>&1
-
打开另一个终端窗口,对
fmbench.log文件执行tail -f命令,以查看运行时生成的所有跟踪信息。tail -f fmbench.log -
👉 查看这些配置文件以了解SageMaker和Bedrock的流式支持:
- [config-llama3-8b-g5-streaming.yml](https://github.com/aws-samples/foundation-model-benchmarking-tool/blob/main/src/configs/llama3/8b/config-llama3-8b-g5-streaming.yml
- [config-bedrock-llama3-streaming.yml](https://github.com/aws-samples/foundation-model-benchmarking-tool/blob/main/src/configs/bedrock/config-bedrock-llama3-streaming.yml
-
生成的报告和指标可在
sagemaker-fmbench-write-<替换为你的aws区域>-<替换为你的aws账户id>存储桶中找到。指标和报告文件也会下载到本地的results目录(由FMBench创建),基准测试报告以markdown文件形式保存为results目录中的report.md。你可以直接在SageMaker笔记本中查看渲染后的Markdown报告,或将指标和报告文件下载到你的机器上进行离线分析。
如果你想了解CloudFormation模板在幕后做了什么,请参阅带有详细说明的DIY版本
在GovCloud的SageMaker上运行FMBench
在GovCloud上运行FMBench不需要特殊步骤。上面的部分已提供了us-gov-west-1的CloudFormation链接。
- 通过Bedrock或其他服务提供的并非所有模型都在GovCloud中可用。以下命令展示了如何运行
FMBench来对GovCloud中的Amazon Titan Text Express模型进行基准测试。更多详情请参阅Amazon Bedrock GovCloud页面。
account=`aws sts get-caller-identity | jq .Account | tr -d '"'`
region=`aws configure get region`
fmbench --config-file s3://sagemaker-fmbench-read-${region}-${account}/configs/bedrock/config-bedrock-titan-text-express.yml > fmbench.log 2>&1
结果
根据配置文件中的实验,FMBench运行可能需要几分钟到几小时不等。运行完成后,你可以在运行FMBench的目录中的本地results-*文件夹中找到报告和指标。报告和指标也会写入配置文件中设置的写入S3存储桶。
以下是FMBench生成的report.md文件的截图。

对部署在不同AWS生成式AI服务上的模型进行基准测试(文档)
FMBench附带了用于对不同AWS生成式AI服务(如Bedrock、SageMaker、EKS和EC2,甚至你自己的端点)上的模型进行基准测试的配置文件。
改进
查看GitHub上的问题,并添加你认为可能对这个基准测试工具有益的迭代。
安全
有关更多信息,请参阅CONTRIBUTING。
许可
该库采用MIT-0许可。请查看LICENSE文件。
Star历史
支持
- 安排演示 👋 - 给我们发邮件 🙂
- 社区Discord 💭
- 我们的邮箱 ✉️ aroraai@amazon.com / madhurpt@amazon.com
贡献者
<a href="https://github.com/aws-samples/foundation-model-benchmarking-tool/graphs/contributors"> <img src="https://contrib.rocks/image?repo=aws-samples/foundation-model-benchmarking-tool" /> </a>参考文献
<a id="1">[1]</a> Pat Verga等,"用陪审团替代法官:利用多样化模型小组评估LLM生成内容",arXiv:2404.18796,2024年。
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号