
MuseV
开源虚拟人视频生成框架支持无限长度输出
MuseV是一个基于扩散模型的开源虚拟人视频生成框架。该框架支持无限长度视频生成,采用视觉条件并行去噪方案,兼容Stable Diffusion生态系统。MuseV支持图像到视频、文本到视频、视频到视频等多种生成模式,并提供多参考图像技术。该项目还开源了训练代码,为研究人员和开发者提供了完整的虚拟人视频生成解决方案。



MuseV 英文 中文
<font size=5>MuseV: 基于视觉条件并行去噪的无限长度高保真虚拟人视频生成 </br> 夏志强 <sup>*</sup>, 陈昭康<sup>*</sup>, 吴斌<sup>†</sup>, 李超, 洪国伟, 詹超, 何颖杰, 周文江 (<sup>*</sup>共同第一作者, <sup>†</sup>通讯作者, benbinwu@tencent.com) </font>
腾讯音乐娱乐集团 Lyra 实验室
GitHub Hugging Face Hugging Face Space 项目主页 技术报告(即将发布)
我们自2023年3月起就设立了世界模拟器的愿景,相信扩散模型能够模拟世界。MuseV是我们在2023年7月左右取得的一个里程碑成果。受Sora进展的启发,我们决定开源MuseV,希望能为社区带来益处。接下来我们将继续探索有前景的扩散+Transformer方案。
更新:
- 我们已发布 <a href="https://github.com/TMElyralab/MuseTalk" style="font-size:24px; color:red;">MuseTalk</a>,这是一个实时高质量的唇形同步模型,可与MuseV结合使用,提供完整的虚拟人生成解决方案。
- :new: 我们很高兴宣布MusePose已经发布。MusePose是一个图像到视频生成框架,可以根据姿势等控制信号生成�虚拟人。结合MuseV和MuseTalk,我们希望社区能够加入我们,朝着能够端到端生成具有全身运动和交互能力的虚拟人的愿景迈进。
概述
MuseV是一个基于扩散模型的虚拟人视频生成框架,它:
- 使用新颖的视觉条件并行去噪方案支持无限长度生成。
- 提供了在人类数据集上训练的虚拟人视频生成checkpoint。
- 支持图像到视频、文本到图像到视频、视频到视频的生成。
- 兼容Stable Diffusion生态系统,包括
base_model、lora、controlnet等。 - 支持多参考图像技术,包括
IPAdapter、ReferenceOnly、ReferenceNet、IPAdapterFaceID。 - 训练代码(即将发布)。
重要bug修复
musev_referencenet_pose:命令中unet和ip_adapter的model_name不正确,请使用musev_referencenet_pose而不是musev_referencenet。
新闻
- [2024/03/27] 发布
MuseV项目和训练模型musev、muse_referencenet。 - [2024/03/30] 添加Hugging Face Space Gradio界面用于生成视频
模型
模型结构概览
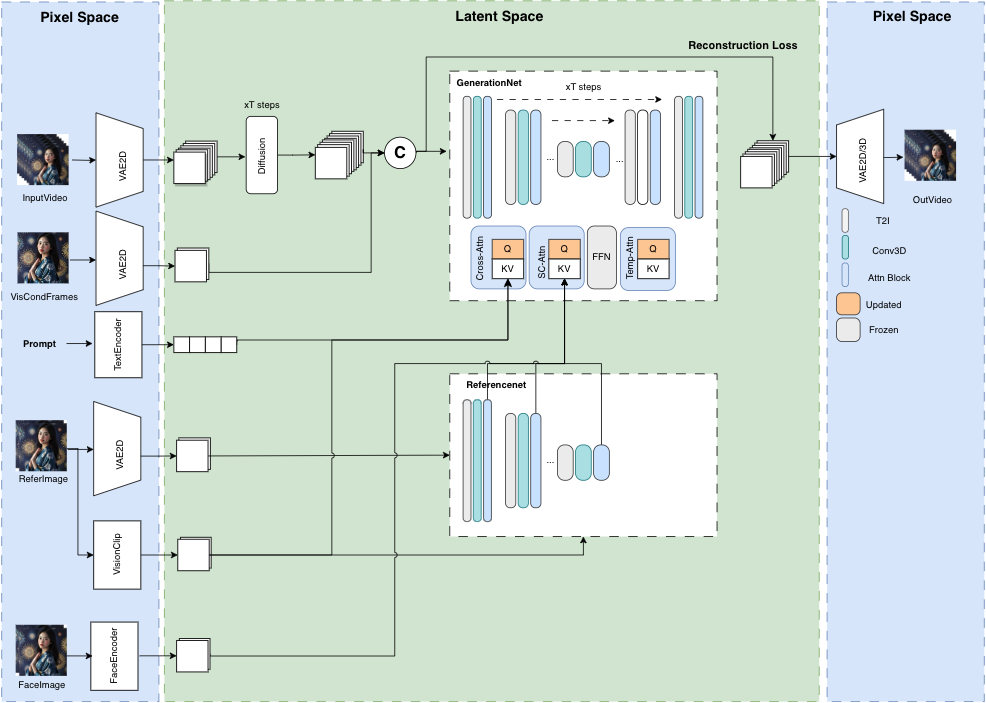
并行去噪

案例
所有帧都是直接由文本到视频模型生成,未经任何后期处理。 更多案例请查看**项目主页,包括1-2分钟的视频**。
以下示例可在configs/tasks/example.yaml中找到
文本/图像到视频
人物
<table class="center"> <tr style="font-weight: bolder;text-align:center;"> <td width="50%">图像</td> <td width="45%">视频</td> <td width="5%">提示词</td> </tr> <tr> <td> <img src=./data/images/yongen.jpeg width="400"> </td> <td > <video src="https://github.com/TMElyralab/MuseV/assets/163980830/732cf1fd-25e7-494e-b462-969c9425d277" width="100" controls preload></video> </td> <td>(杰作,最佳质量,高分辨率:1),(1个男孩,单人:1),(眨眼:1.8),(头部摇晃:1.3) </td> </tr> <tr> <td> <img src=./data/images/seaside4.jpeg width="400"> </td> <td> <video src="https://github.com/TMElyralab/MuseV/assets/163980830/9b75a46c-f4e6-45ef-ad02-05729f091c8f" width="100" controls preload></video> </td> <td> (杰作,最佳质量,高分辨率:1),平静美丽的海景 </td> </tr> <tr> <td> <img src=./data/images/seaside_girl.jpeg width="400"> </td> <td> <video src="https://github.com/TMElyralab/MuseV/assets/163980830/d0f3b401-09bf-4018-81c3-569ec24a4de9" width="100" controls preload></video> </td> <td> (杰作,最佳质量,高分辨率:1),平静美丽的海景 </td> </tr> <!-- 吉他 --> <tr> <td> <img src=./data/images/boy_play_guitar.jpeg width="400"> </td> <td> <video src="https://github.com/TMElyralab/MuseV/assets/163980830/61bf955e-7161-44c8-a498-8811c4f4eb4f" width="100" controls preload></video> </td> <td> (杰作,最佳质量,高分辨率:1),弹吉他 </td> </tr> <tr> <td> <img src=./data/images/girl_play_guitar2.jpeg width="400"> </td> <td> <video src="https://github.com/TMElyralab/MuseV/assets/163980830/40982aa7-9f6a-4e44-8ef6-3f185d284e6a" width="100" controls preload></video> </td> <td> (杰作,最佳质量,高分辨率:1),弹吉他 </td> </tr> <!-- 名人 --> <tr> <td> <img src=./data/images/dufu.jpeg width="400"> </td> <td> <video src="https://github.com/TMElyralab/MuseV/assets/163980830/28294baa-b996-420f-b1fb-046542adf87d" width="100" controls preload></video> </td> <td> (杰作,最佳质量,高分辨率:1),(1个男人,单人:1),(眨眼:1.8),(头部摇晃:1.3),中国水墨画风格 </td> </tr> <tr> <td> <img src=./data/images/Mona_Lisa.jpg width="400"> </td> <td> <video src="https://github.com/TMElyralab/MuseV/assets/163980830/1ce11da6-14c6-4dcd-b7f9-7a5f060d71fb" width="100" controls preload></video> </td> <td> (杰作,最佳质量,高分辨率:1),(1个女孩,单人:1),(美丽的脸庞, 柔软的皮肤,服装:1),(眨眼:{eye_blinks_factor}),(头部摆动:1.3) </td> </tr> </table >场景
<table class="center"> <tr style="font-weight: bolder;text-align:center;"> <td width="35%">图像</td> <td width="50%">视频</td> <td width="15%">提示词</td> </tr> <tr> <td> <img src=./data/images/waterfall4.jpeg width="400"> </td> <td> <video src="https://github.com/TMElyralab/MuseV/assets/163980830/852daeb6-6b58-4931-81f9-0dddfa1b4ea5" width="100" controls preload></video> </td> <td> (杰作,最佳质量,高分辨率:1),宁静美丽的瀑布,无尽的瀑布 </td> </tr> <tr> <td> <img src=./data/images/seaside2.jpeg width="400"> </td> <td> <video src="https://github.com/TMElyralab/MuseV/assets/163980830/4a4d527a-6203-411f-afe9-31c992d26816" width="100" controls preload></video> </td> <td>(杰作,最佳质量,高分辨率:1),宁静美丽的海景 </td> </tr> </table >视频中间帧到视频
姿势到视频 在"duffy"模式下,视觉条件帧的姿势与控制视频的第一帧不对齐。"posealign"将解决这个问题。
<table class="center"> <tr style="font-weight: bolder;text-align:center;"> <td width="25%">图像</td> <td width="65%">视频</td> <td width="10%">提示词</td> </tr> <tr> <td> <img src=./data/images/spark_girl.png width="200"> <img src=./data/images/cyber_girl.png width="200"> </td> <td> <video src="https://github.com/TMElyralab/MuseV/assets/163980830/484cc69d-c316-4464-a55b-3df929780a8e" width="400" controls preload></video> </td> <td> (杰作,最佳质量,高分辨率:1),一个女孩在跳舞,动画 </td> </tr> <tr> <td> <img src=./data/images/duffy.png width="400"> </td> <td> <video src="https://github.com/TMElyralab/MuseV/assets/163980830/c44682e6-aafc-4730-8fc1-72825c1bacf2" width="400" controls preload></video> </td> <td> (杰作,最佳质量,高分辨率:1),在跳舞,动画 </td> </tr> </table >MuseTalk
对话的角色"Sun Xinying"是一位超模KOL。你可以在抖音上关注她。
<table class="center"> <tr style="font-weight: bolder;"> <td width="35%">名称</td> <td width="50%">视频</td> </tr> <tr> <td> 对话 </td> <td> <video src="https://github.com/TMElyralab/MuseV/assets/163980830/951188d1-4731-4e7f-bf40-03cacba17f2f" width="100" controls preload></video> </td> <tr> <td> 唱歌 </td> <td> <video src="https://github.com/TMElyralab/MuseV/assets/163980830/50b8ffab-9307-4836-99e5-947e6ce7d112" width="100" controls preload></video> </td> </tr> </table >待办事项:
- 技术报告(即将推出)。
- 训练代码。
- 发布预训练的unet模型,该模型使用controlnet、referencenet、IPAdapter进行训练,在姿势到视频方面表现更好。
- 支持扩散变压器生成框架。
- 发布"posealign"模块
快速开始
准备Python环境并安装额外的包,如"diffusers"、"controlnet_aux"、"mmcm"。
第三方集成
感谢第三方集成,这使得安装和使用对每个人来说都更加方便。 我们也希望您注意,我们没有验证、维护或更新第三方。具体结果请参考本项目。
ComfyUI
Windows一键集成包
网盘链接:https://www.123pan.com/s/Pf5Yjv-Bb9W3.html
提取码:glut
准备环境
我们建议您主要使用"docker"来准备Python环境。
准备Python环境
注意:我们只用docker进行了测试,使用conda或requirements可能会遇到问题。我们会尝试修复。请使用"docker"。
方法1:docker
- 拉取docker镜像
docker pull anchorxia/musev:latest
- 运行docker
docker run --gpus all -it --entrypoint /bin/bash anchorxia/musev:latest
默认的conda环境是"musev"。
方法2:conda
从environment.yaml创建conda环境
conda env create --name musev --file ./environment.yml
方法3:pip requirements
pip install -r requirements.txt
准备mmlab包
如果不使用docker,还需额外安装mmlab包。
pip install --no-cache-dir -U openmim mim install mmengine mim install "mmcv>=2.0.1" mim install "mmdet>=3.1.0" mim install "mmpose>=1.1.0"
准备自定义包/修改包
克隆
git clone --recursive https://github.com/TMElyralab/MuseV.git
准备PYTHONPATH
current_dir=$(pwd) export PYTHONPATH=${PYTHONPATH}:${current_dir}/MuseV export PYTHONPATH=${PYTHONPATH}:${current_dir}/MuseV/MMCM export PYTHONPATH=${PYTHONPATH}:${current_dir}/MuseV/diffusers/src export PYTHONPATH=${PYTHONPATH}:${current_dir}/MuseV/controlnet_aux/src cd MuseV
MMCM: 多媒体跨模态处理包。diffusers: 基于diffusers修改的diffusers包。controlnet_aux: 基于controlnet_aux修改。
下载模型
git clone https://huggingface.co/TMElyralab/MuseV ./checkpoints
motion: 文本到视频模型,在微小的ucf101和webvid数据集上训练,大约60K个视频文本对。GPU内存消耗测试基于分辨率$=512*512$,time_size=12。musev/unet: 仅包含并训练unet运动模块。GPU内存消耗$\approx 8G$。musev_referencenet: 训练unet模块、referencenet和IPAdapter。GPU内存消耗$\approx 12G$。unet:运动模块,在Attention层中有to_k、to_v,参考IPAdapter。referencenet: 类似于AnimateAnyone。ip_adapter_image_proj.bin: 图像clip嵌入投影层,参考IPAdapter。
musev_referencenet_pose: 基于musev_referencenet,固定referencenet和controlnet_pose,训练unet motion和IPAdapter。GPU内存消耗$\approx 12G$。
t2i/sd1.5: 文本到图像模型,在训练运动模块时参数被冻结。不同的t2i基础模型有显著影响,可以替换为其他t2i基础模型。majicmixRealv6Fp16: 示例,从majicmixRealv6Fp16下载。fantasticmix_v10: 示例,从fantasticmix_v10下载。
IP-Adapter/models: 从IPAdapter下载。image_encoder: 视觉clip模型。ip-adapter_sd15.bin: 原始IPAdapter模型检查点。ip-adapter-faceid_sd15.bin: 原始IPAdapter模型检查点。
推理
准备模型路径
使用示例任务和示例推理命令运行时可以跳过此步骤。 在配置中设置模型路径和缩写,以便在推理脚本中使用缩写。
- T2I SD:参考
musev/configs/model/T2I_all_model.py - Motion Unet: 参考
musev/configs/model/motion_model.py - 任务: 参考
musev/configs/tasks/example.yaml
musev_referencenet
文本到视频
python scripts/inference/text2video.py --sd_model_name majicmixRealv6Fp16 --unet_model_name musev_referencenet --referencenet_model_name musev_referencenet --ip_adapter_model_name musev_referencenet -test_data_path ./configs/tasks/example.yaml --output_dir ./output --n_batch 1 --target_datas yongen --vision_clip_extractor_class_name ImageClipVisionFeatureExtractor --vision_clip_model_path ./checkpoints/IP-Adapter/models/image_encoder --time_size 12 --fps 12
常用参数:
test_data_path: yaml扩展中的任务路径。target_datas: 分隔符为,,如果test_data_path中的name在target_datas中,则采样子任务。sd_model_cfg_path: T2I sd模型路径,模型配置路径或模型路径。sd_model_name: sd模型名称,用于在sd_model_cfg_path中选择完整模型路径。多个模型名称以,分隔,或使用all。unet_model_cfg_path: 运动unet模型配置路径或模型路径。unet_model_name: unet模型名称,用于在unet_model_cfg_path中获取模型路径,并在musev/models/unet_loader.py中初始化unet类实例。多个模型名称以,分隔,或使用all。如果unet_model_cfg_path是模型路径,unet_name必须在musev/models/unet_loader.py中受支持。time_size: 每次扩散去噪生成的帧数。默认为12。n_batch: 生成镜头的数量,$总帧数=n_batch * time_size + n_viscond$,默认为1。context_frames: 上下文帧数。如果time_size>context_frame,time_size窗口将被分成多个子窗口进行并行去噪。默认为12。
生成长视频有两种方式:
视觉条件并行去噪: 设置n_batch=1,time_size=你想要的所有帧数。传统端到端: 设置time_size=context_frames= 一个镜头的帧数(12),context_overlap= 0;
模型参数:
支持referencenet、IPAdapter、IPAdapterFaceID、Facein。
- referencenet_model_name:
referencenet模型名称。 - ImageClipVisionFeatureExtractor:
ImageEmbExtractor名称,用于提取IPAdapter中使用的视觉clip嵌入。 - vision_clip_model_path:
ImageClipVisionFeatureExtractor模型路径。 - ip_adapter_model_name: 来自
IPAdapter,它是ImagePromptEmbProj,与ImageEmbExtractor一起使用。 - ip_adapter_face_model_name:
IPAdapterFaceID,来自IPAdapter以保持面部ID,应设置face_image_path。
一些影响运动范围和生成结果的参数:
video_guidance_scale: 类似于文本到图像,控制条件和无条件之间的影响,默认为3.5。use_condition_image: 是否使用给定的第一帧进行视频生成,如果不使用则先生成视觉条件帧。默认为True。redraw_condition_image: 是否重绘给定的第一帧图像。video_negative_prompt: 配置路径中完整negative_prompt的缩写。默认为V2。
视频到视频
t2i基础模型有显著影响。在这种情况下,fantasticmix_v10比majicmixRealv6Fp16表现更好。
python scripts/inference/video2video.py --sd_model_name fantasticmix_v10 --unet_model_name musev_referencenet --referencenet_model_name musev_referencenet --ip_adapter_model_name musev_referencenet -test_data_path ./configs/tasks/example.yaml --vision_clip_extractor_class_name ImageClipVisionFeatureExtractor --vision_clip_model_path ./checkpoints/IP-Adapter/models/image_encoder --output_dir ./output --n_batch 1 --controlnet_name dwpose_body_hand --which2video "video_middle" --target_datas dance1 --fps 12 --time_size 12
重要参数
大多数参数与musev_text2video相同。video2video的特殊参数有:
- 需要在
test_data中设置video_path作为参考视频。现在参考视频支持rgb视频和controlnet_middle_video。
which2video: 是否rgb视频影响初始噪声,rgb的影响强于controlnet条件。controlnet_name:是否使用controlnet条件,如dwpose,depth。video_is_middle:video_path是rgb视频还是controlnet_middle_video。可以为test_data_path中的每个test_data设置。video_has_condition: 条件图像是否与video_path的第一帧对齐。如果不是,首先提取condition_images的条件生成,然后与连接对齐。在test_data中设置。 所有controlnet_names指的是mmcm
['pose', 'pose_body', 'pose_hand', 'pose_face', 'pose_hand_body', 'pose_hand_face', 'dwpose', 'dwpose_face', 'dwpose_hand', 'dwpose_body', 'dwpose_body_hand', 'canny', 'tile', 'hed', 'hed_scribble', 'depth', 'pidi', 'normal_bae', 'lineart', 'lineart_anime', 'zoe', 'sam', 'mobile_sam', 'leres', 'content', 'face_detector']
musev_referencenet_pose
仅用于pose2video
基于musev_referencenet训练,固定referencenet、pose-controlnet和T2I,训练motion模块和IPAdapter。
t2i基础模型有显著影响。在这种情况下,fantasticmix_v10表现优于majicmixRealv6Fp16。
python scripts/inference/video2video.py --sd_model_name fantasticmix_v10 --unet_model_name musev_referencenet_pose --referencenet_model_name musev_referencenet --ip_adapter_model_name musev_referencenet_pose -test_data_path ./configs/tasks/example.yaml --vision_clip_extractor_class_name ImageClipVisionFeatureExtractor --vision_clip_model_path ./checkpoints/IP-Adapter/models/image_encoder --output_dir ./output --n_batch 1 --controlnet_name dwpose_body_hand --which2video "video_middle" --target_datas dance1 --fps 12 --time_size 12
musev
仅有motion模块,没有referencenet,需要更少的GPU内存。
text2video
python scripts/inference/text2video.py --sd_model_name majicmixRealv6Fp16 --unet_model_name musev -test_data_path ./configs/tasks/example.yaml --output_dir ./output --n_batch 1 --target_datas yongen --time_size 12 --fps 12
video2video
python scripts/inference/video2video.py --sd_model_name fantasticmix_v10 --unet_model_name musev -test_data_path ./configs/tasks/example.yaml --output_dir ./output --n_batch 1 --controlnet_name dwpose_body_hand --which2video "video_middle" --target_datas dance1 --fps 12 --time_size 12
Gradio演示
MuseV提供了gradio脚本,可以在本地机器上生成GUI界面,方便地生成视频。
cd scripts/gradio python app.py
致谢
- MuseV参考了很多TuneAVideo、diffusers、Moore-AnimateAnyone、animatediff、IP-Adapter、AnimateAnyone、VideoFusion、insightface的内容。
- MuseV基于
ucf101和webvid数据集构建。
感谢开源!
局限性
仍然存在许多局限性,包括:
- 缺乏泛化能力。一些视觉条件图像表现良好,一些表现不佳。一些t2i预训练模型表现良好,一些表现不佳。
- 视频生成类型有限,动作范围有限,部分原因是训练数据类型有限。发布的
MuseV已经在约60K个人类文本-视频对上进行了训练,分辨率为512*320。MuseV在较低分辨率下具有更大的动作范围但视频质量较低。MuseV倾向于在高视频质量下生成较少的动作范围。在更大、更高分辨率、更高质量的�文本-视频数据集上训练可能会使MuseV表现更好。 - 可能出现水印,这是因为使用了
webvid。使用更干净的无水印数据集可能会解决这个问题。 - 长视频生成类型有限。视觉条件并行去噪可以解决视频生成的累积错误,但当前方法仅适用于相对固定摄像机场景。
- referencenet和IP-Adapter训练不足,这是由于时间和资源有限。
- 代码结构不够完善。
MuseV支持丰富和动态的功能,但代码复杂且未经重构。需要时间来熟悉。
引用
@article{musev, title={MuseV: Infinite-length and High Fidelity Virtual Human Video Generation with Visual Conditioned Parallel Denoising}, author={Xia, Zhiqiang and Chen, Zhaokang and Wu, Bin and Li, Chao and Hung, Kwok-Wai and Zhan, Chao and He, Yingjie and Zhou, Wenjiang}, journal={arxiv}, year={2024} }
免责声明/许可
代码:MuseV的代码根据MIT许可发布。对学术和商业用途都没有限制。模型:训练好的模型仅供非商业研究目的使用。其他开源模型:使用的其他开源模型必须遵守它们的许可,如insightface、IP-Adapter、ft-mse-vae等。- 测试数据从互联网收集,仅供非商业研究目的使用。
AIGC:本项目致力于积极影响AI驱动的视频生成领域。用户可以自由使用此工具创建视频,但预期他们会遵守当地法律并负责任地使用它。开发者不对用户可能的滥用承担任何责任。
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导��入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改�变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号