
VectorDBBench
开源向量数据库基准测试工具
VectorDBBench是一个开源的向量数据库基准测试工具。它提供15个测试用例,评估容量、搜索性能和过滤搜索性能。支持多种数据库客户端,具有可视化界面,方便复现测试和评估新系统。工具还包含性能分析报告和排行榜功能,有助于比较不同向量数据库的性能。





VectorDBBench:一款面向向量数据库的基准测试工具

排行榜: https://zilliz.com/benchmark
快速开始
前置要求
python >= 3.11
安装
仅安装 PyMilvus 的 vectordb-bench
pip install vectordb-bench
安装所有数据库客户端
pip install vectordb-bench[all]
安装指定数据库客户端
pip install vectordb-bench[pinecone]
支持的所有数据库客户端及其安装命令如下:
| 可选数据库客户端 | 安装命令 |
|---|---|
| pymilvus(默认) | pip install vectordb-bench |
| all | pip install vectordb-bench[all] |
| qdrant | pip install vectordb-bench[qdrant] |
| pinecone | pip install vectordb-bench[pinecone] |
| weaviate | pip install vectordb-bench[weaviate] |
| elastic | pip install vectordb-bench[elastic] |
| pgvector | pip install vectordb-bench[pgvector] |
| pgvecto.rs | pip install vectordb-bench[pgvecto_rs] |
| pgvectorscale | pip install vectordb-bench[pgvectorscale] |
| redis | pip install vectordb-bench[redis] |
| memorydb | pip install vectordb-bench[memorydb] |
| chromadb | pip install vectordb-bench[chromadb] |
| awsopensearch | pip install vectordb-bench[awsopensearch] |
运行
init_bench
或:
从命令行运行
vectordbbench [OPTIONS] COMMAND [ARGS]...
要列出可通过命令行选项运行的客户端,请执行: vectordbbench --help
$ vectordbbench --help Usage: vectordbbench [OPTIONS] COMMAND [ARGS]... Options: --help Show this message and exit. Commands: pgvectorhnsw pgvectorivfflat test weaviate
要列出每个命令的选项,请执行 vectordbbench [command] --help
$ vectordbbench pgvectorhnsw --help Usage: vectordbbench pgvectorhnsw [OPTIONS] Options: --config-file PATH 从yaml文件读取配置 --drop-old / --skip-drop-old 删除旧有或跳过 [default: drop-old] --load / --skip-load 加载或跳过 [default: load] --search-serial / --skip-search-serial 串行搜索或跳过 [default: search-serial] --search-concurrent / --skip-search-concurrent 并发搜索或跳过 [default: search-concurrent] --case-type [CapacityDim128|CapacityDim960|Performance768D100M|Performance768D10M|Performance768D1M|Performance768D10M1P|Performance768D1M1P|Performance768D10M99P|Performance768D1M99P|Performance1536D500K|Performance1536D5M|Performance1536D500K1P|Performance1536D5M1P|Performance1536D500K99P|Performance1536D5M99P|Performance1536D50K] 测试用例类型 --db-label TEXT 数据库标签, 默认为当前日期格式 [default: 2024-05-20T20:26:31.113290] --dry-run 只打印配置并退出, 不运行任务 --k INTEGER 搜索的最近邻数量 [default: 100] --concurrency-duration INTEGER 并发搜索的持续时间(秒) [default: 30] --num-concurrency TEXT 并发搜索时的并发值, 逗号分隔 [default: 1,10,20] --user-name TEXT 数据库用户名 [required] --password TEXT 数据库密码 [required] --host TEXT 数据库主机 [required] --db-name TEXT 数据库名称 [required] --maintenance-work-mem TEXT 设置维护操作(索引创建)的最大内存使用, 可以以字符串形式指定单位如'64GB', 或直接整数KB --max-parallel-workers INTEGER 设置维护操作(索引创建)的最大并行进程数 --m INTEGER hnsw m --ef-construction INTEGER hnsw ef-construction --ef-search INTEGER hnsw ef-search --help 显示帮助信息并退出
使用配置文件
vectordbbench 命令可以选择性地从 yaml 格式的配置文件中读取部分或全部选项。
默认情况下,配置文件预期位于 vectordb_bench/config-files/ 目录下, 可以通过设置环境变量 CONFIG_LOCAL_DIR 或传递完整路径来覆盖。
所需的格式如下:
命令名: 参数名: 参数值 参数名: 参数值
示例:
pgvectorhnsw: db_label: pgConfigTest user_name: vectordbbench password: vectordbbench db_name: vectordbbench host: localhost m: 16 ef_construction: 128 ef_search: 128 milvushnsw: skip_search_serial: True case_type: Performance1536D50K uri: http://localhost:19530 m: 16 ef_construction: 128 ef_search: 128 drop_old: False load: False
注意:
- 命令行传递的选项将覆盖配置文件*
- 参数名使用下划线 _ 而不是 -
什么是 VectorDBBench
VectorDBBench 不仅提供了主流向量数据库和云服务的基准测试结果, 更是一个帮助用户进行性能和成本效益对比的工具。它旨在让用户, 甚至非专业人士也能轻松复制结果或测试新系统, 大大简化了在众多云服务和开源向量数据库中选择最优选择的过程。
为了提升用户体验, 我们提供了一个直观的可视化界面。这不仅使用户能轻松启动基准测试, 还能查看对比报告, 轻松复制基准测试结果。
为了提高相关性和实用性, 我们提供了特别针对云服务的成本效益报告, 使基准测试过程更加切合实际。
我们设计了包括插入、搜索和过滤搜索在内的多种测试场景, 以更贴近真实生产环境。为了提供可信赖的数据, 我们使用了来自实际生产场景的公开数据集, 如 SIFT、GIST、Cohere 和由 OpenAI 从开源原始数据集生成的数据集。这让我们有机会发现一些鲜为人知的开源数据库在某些情况下可能会有出色的表现!
准备好投入 VectorDBBench 的世界吧, 让它引导你发现最适合自己的向量数据库!
排行榜
简介
为了便于展示测试结果并提供全面的性能分析报告,我们提供了排行榜页面。它允许我们选择QPS、QP$和延迟指标,并根据各种用例的测试结果和一组评分机制(稍后介绍)对系统的性能进行全面评估。在这个排行榜上,我们可以选择要比较的系统和模型,并过滤掉我们不想考虑的��用例。综合得分始终从最好到最差排序,每个查询的具体测试结果将在下面的列表中显示。
评分规则
-
对于每个用例,选择一个基准值并根据相对值对每个系统进行评分。
- 对于QPS和QP$,我们使用最高值作为参考,记为
base_QPS或base_QP$,每个系统的得分为(QPS/base_QPS) * 100或(QP$/base_QP$) * 100。 - 对于延迟,我们使用最低值作为参考,即
base_Latency,每个系统的得分为(base_Latency + 10ms)/(Latency + 10ms) * 100。
我们希望给不同用例平等的权重,而不让一个具有高绝对结果值的用例成为总体评分的唯一原因。因此,在每个用例中为不同系统评分时,我们需要使用相对值。
此外,对于延迟,我们在分子和分母中添加10毫秒,以确保如果每个系统在某个用例中都表现特别出色,其优势不会在延迟趋近于0时被无限放大。
- 对于QPS和QP$,我们使用最高值作为参考,记为
-
对于在特定用例中失败或超时的系统,我们会给它们一个得分,该得分比最差结果低两倍。例如,在QPS或QP$中,它将是最低值的一半。对于延迟,它将是最大值的两倍。
-
对于每个系统,我们将取其在所有用例中得分的几何平均值作为其在特定指标上的综合得分。
自建
安装要求
pip install -e '.[test]' pip install -e '.[pinecone]'
运行测试服务器
$ python -m vectordb_bench
或者:
$ init_bench
或者:
如果您使用了开发容器,请先创建以下数据集目录:
# 将本地 ~/vectordb_bench/dataset 挂载到容器的 /tmp/vectordb_bench/dataset。 # 如果您对路径名不太舒服,可以在 devcontainer.json 中自行更改。 mkdir -p ~/vectordb_bench/dataset
在容器的 bash 中运行 python -m vectordb_bench。
检查编码风格
$ ruff check vectordb_bench
如果要自动修复编码风格,请添加 --fix
$ ruff check vectordb_bench --fix
它是如何工作的?
结果页面
这是VectorDBBench的主页,显示了我们提供的标准基准测试结果。此外,用户自己进行的所有测试结果也将在此显示。我们还提供了同时选择和比较多个测试结果的功能。
这里显示的标准基准测试结果包括我们目前支持�的15个用例,涉及6个客户端(Milvus、Zilliz Cloud、Elastic Search、Qdrant Cloud、Weaviate Cloud和PgVector)。但是,由于一些系统可能由于内存不足(OOM)或超时等问题无法成功完成所有测试,因此并非所有客户端都包含在每个用例中。
所有标准基准测试结果都是由一台位于被测试服务器所在区域的8核心、32GB主机上运行的客户端生成的。该客户端主机配备了Intel(R) Xeon(R) Platinum 8375C CPU @ 2.90GHz处理器。同时,我们在基准测试中测试的所有开源系统的服务器都运行在相同类型的处理器上。
运行测试页面
这是运行测试的页面:
- 首先,您选择要测试的系统-允许多选。一旦选定,相应的表单就会弹出,以收集使用所选数据库所需的信息。db_label用于区分同一系统的不同实例。我们建议在此填写主机大小或实例类型(与我们的标准结果一致)。
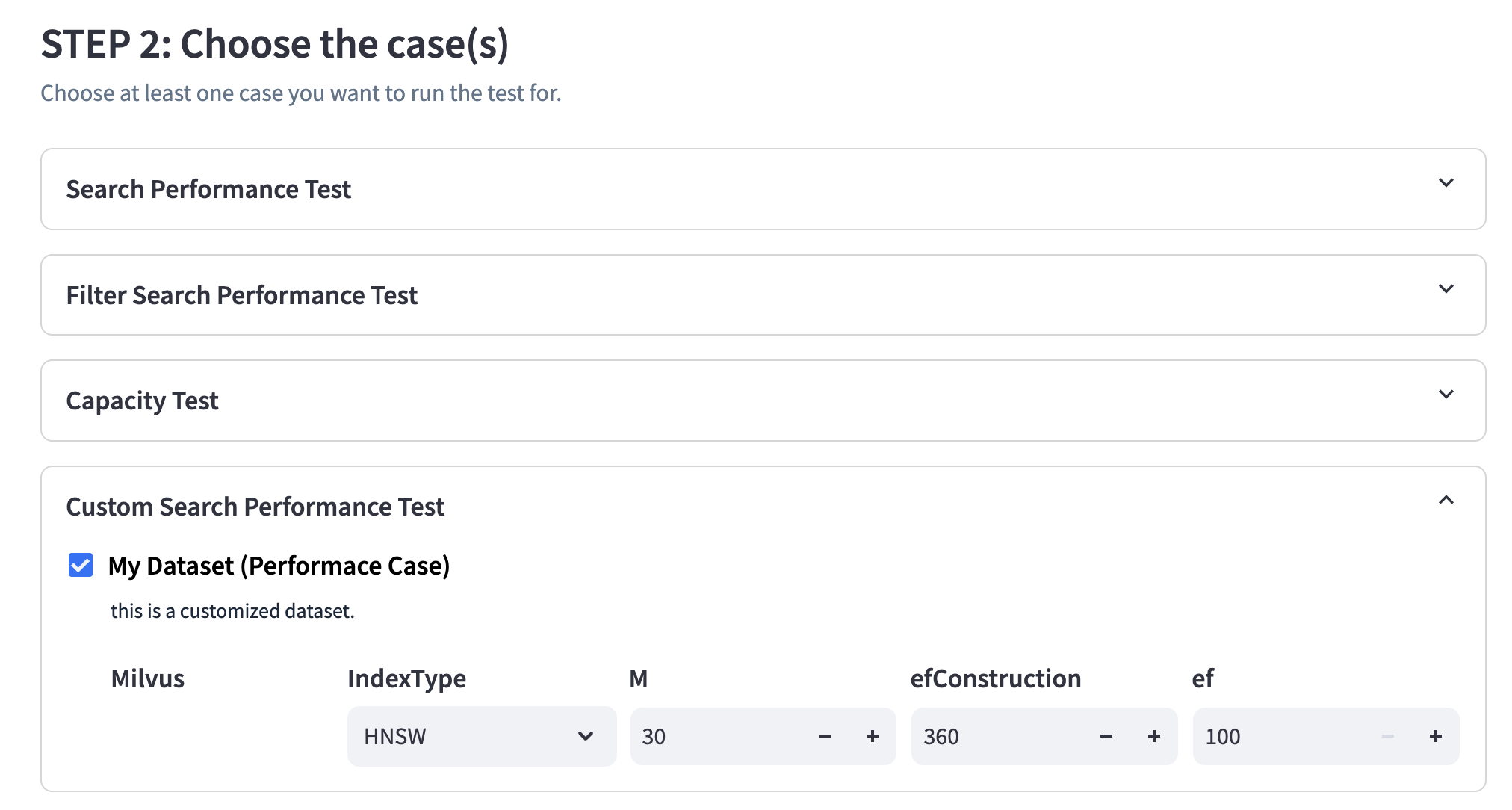
- 下一步是选择要执行的测试用例。您可以一次选择多个用例,相应的参数收集表单也会出现。
- 最后,您需要提供一个任务标签来区分不同的测试结果。使用相同的标签进行不同的测试将导致先前的结果被覆盖。 目前我们只能一次运行一个任务。
模块
代码结构
客户端
我们的客户端模块的设计以灵活性和可扩展性为目标,旨在无缝集成来自不同系统的API。目前,它支持Milvus、Zilliz Cloud、Elastic Search、Pinecone、Qdrant Cloud、Weaviate Cloud、PgVector、Redis和Chroma。敬请关注更多选择,因为我们正在不断努力扩展到其他系统。
基准测试用例
我们开发了15个全面的基准测��试用例,用于测试向量数据库的各种功能,每个都旨在为您提供问题的不同部分。这些用例分为三大类:
容量用例
- 大维度: 通过插入大维度向量(GIST 100K向量,960维)来测试数据库的加载容量,直到完全加载。报告最终插入的向量数量。
- 小维度: 类似于大维度用例,但使用小维度向量(SIFT 500K向量,128维)。
搜索性能用例
- 超大数据集: 在不同并行级别下测量使用超大数据集(LAION 100M向量,768维)的搜索性能。结果包括建立索引的时间、召回率、延迟和最大QPS。
- 大数据集: 与超大数据集用例类似,但使用稍小的数据集(10M-768维,5M-1536维)。
- 中等数据集: 使用中等数据集(1M-768维,500K-1536维)的用例。
带过滤的搜索性能用例
- 大数据集,低过滤率: 在大数据集(10M-768维,5M-1536维)下评估搜索性能,过滤率低(1%向量),并在不同并行级别下进行测试。
- 中等数据集,低过滤率: 该用例使用中等数据集(1M-768维,500K-1536维),过滤率也较低。
- 大数据集,高过滤率: 它使用大数据集(10M-768维,5M-1536维),但过滤率较高(99%向量)。
- 中等数据集,高过滤率: 该用例使用中等数据集(1M-768维,500K-1536维),过滤率较高。 快速参考,下表总结了每个用例的关键方面: 案例编号 | 案例类型 | 数据集大小 | 过滤率 | 结果 | |----------|-----------|--------------|----------------|---------| 1 | 容量案例 | SIFT 500K 向量, 128 维 | 不适用 | 插入向量数量 | 2 | 容量案例 | GIST 100K 向量, 960 维 | 不适用 | 插入向量数量 | 3 | 搜索性能案例 | LAION 100M 向量, 768 维 | 不适用 | 索引构建时间、召回率、延迟、最大 QPS | 4 | 搜索性能案例 | Cohere 10M 向量, 768 维 | 不适用 | 索引构建时间、召回率、延迟、最大 QPS | 5 | 搜索性能案例 | Cohere 1M 向量, 768 维 | 不适用 | 索引构建时间、召回率、延迟、最大 QPS | 6 | 过滤搜索性能案例 | Cohere 10M 向量, 768 维 | 1% 向量 | 索引构建时间、召回率、延迟、最大 QPS | 7 | 过滤搜索性能案例 | Cohere 1M 向量, 768 维 | 1% 向量 | 索引构建时间、召回率、延迟、最大 QPS | 8 | 过滤搜索性能案例 | Cohere 10M 向量, 768 维 | 99% 向量 | 索引构建时间、召回率、延迟、最大 QPS | 9 | 过滤搜索性能案例 | Cohere 1M 向量, 768 维 | 99% 向量 | 索引构建时间、召回率、延迟、最大 QPS | 10 | 搜索性能案例 | OpenAI 生成 500K 向量, 1536 维 | 不适用 | 索引构建时间、召回率、延迟、最大 QPS | 11 | 搜索性能案例 | OpenAI 生成 5M 向量, 1536 维 | 不适用 | 索引构建时间、召回率、延迟、最大 QPS | 12 | 过滤搜索性能案例 | OpenAI 生成 500K 向量, 1536 维 | 1% 向量 | 索引构建时间、召回率、延迟、最大 QPS | 13 | 过滤搜索性能案例 | OpenAI 生成 5M 向量, 1536 维 | 1% 向量 | 索引构建时间、召回率、延迟、最大 QPS | 14 | 过滤搜索性能案例 | OpenAI 生成 500K 向量, 1536 维 | 99% 向量 | 索引构建时间、召回率、延迟、最大 QPS | 15 | 过滤搜索性能案例 | OpenAI 生成 5M 向量, 1536 维 | 99% 向量 | 索引构建时间、召回率、延迟、最大 QPS |
每个案例都对矢量数据库的功能进行了深入的检查,为您提供了对数据库性能的全面了解。
自定义性能案例数据集
通过 /custom 页面,用户可以使用本地数据集自定义性能案例。保存后,可以从 /run_test 页面选择相应的案例进行测试。
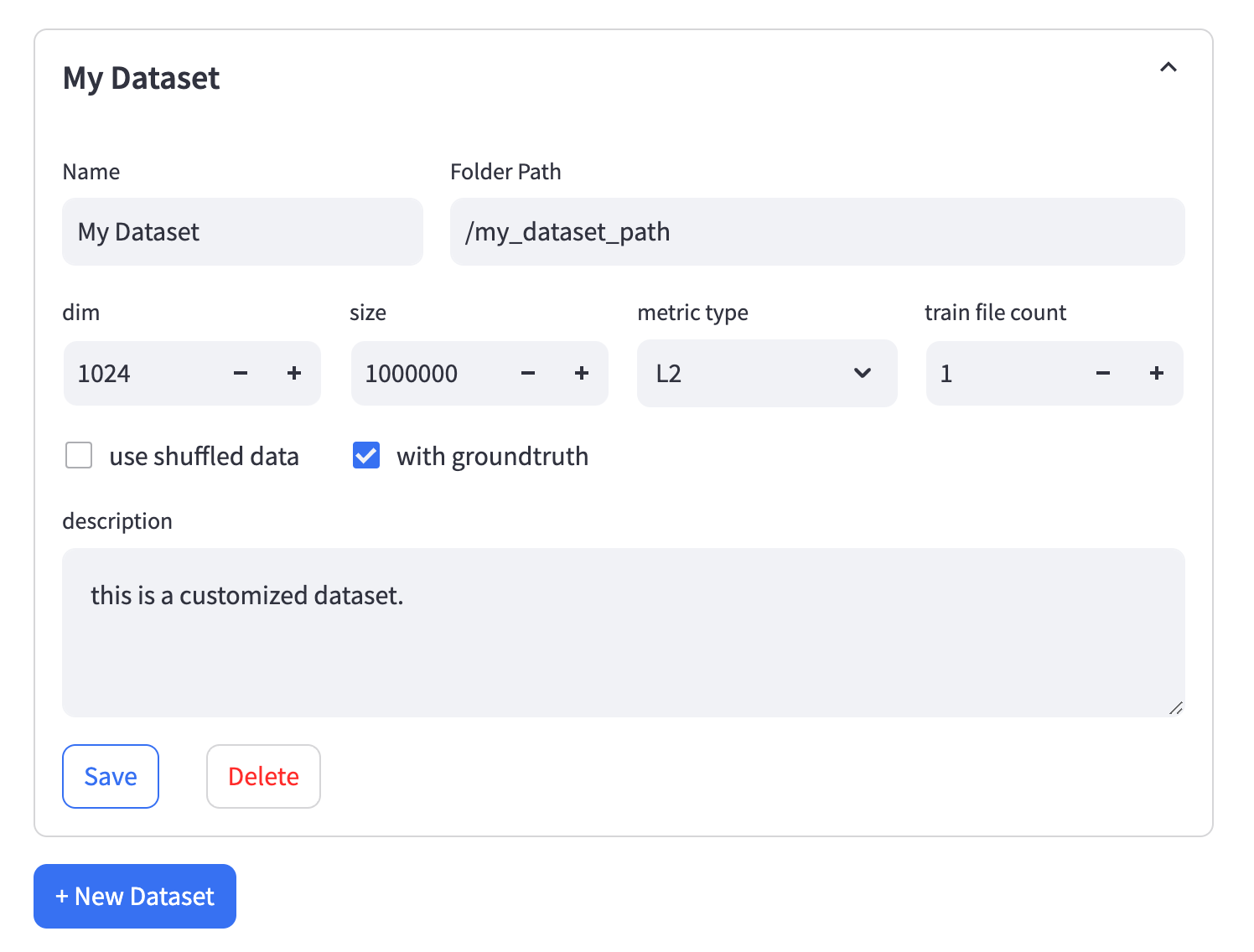
我们对数据集格式有严格要求,请遵循以下要求:
-
Folder Path- 包含所有文件的文件夹路径。请确保文件夹中的所有文件均为Parquet格式。- 向量数据文件: 文件必须命名为
train.parquet,应包含两列:id作为递增的int和emb作为float32数组。 - 查询测试向量: 文件必须命名为
test.parquet,应包含两列:id作为递增的int和emb作为float32数组。 - 真实标签文件: 文件必须命名为
neighbors.parquet,应包含两列:id对应查询向量和neighbors_id作为int数组。
- 向量数据文件: 文件必须命名为
-
Train File Count- 如果向量文件过大,您可以考虑将其拆分为多个文件。拆分文件的命名格式应为train-[index]-of-[file_count].parquet。例如,train-01-of-10.parquet表示 10 个拆分文件中的第二个(0 索引)。 -
Use Shuffled Data- 如果选中此选项,需要修改向量数据文件。VectorDBBench 将加载标记为shuffle的数据。例如,使用shuffle_train.parquet而不是train.parquet,以及shuffle_train-04-of-10.parquet而不是train-04-of-10.parquet。在乱序数据中,id列可以是任意顺序。
目标
我们的基准测试目标如下:
可复制性和可用性
VectorDBBench 的主要目标之一是使用户能够快速轻松地复制基准测试结果,或测试自定义场景。我们相信降低进行这些测试的障碍将增强社区对向量数据库的理解和改进。我们的目标是创造一个环境,任何用户,无论其技术专长如何,都可以快速设置和运行基准测试,并以直观的方式查看和分析结果。
代表性和现实性
VectorDBBench 旨在提供更全面、多方面的测试环境,以准确反映向量数据库的复杂性。通过超越简单的算法速度测试,我们希望为更好地理解向量数据库在现实场景中的表现做出贡献。通过尽可能包含更多复杂场景,包括各种测试用例和数据集,我们旨在反映现实条件,并为我们的社区提供有形的意义。我们的目标是提供可以推动向量数据库开发和使用的切实改进的基准测试结果。
贡献
一般指南
- Fork 存储库并为您的更改创建一个新分支。
- 遵守编码约定和格式化准则。
- 使用清晰的提交消息来记录您更改的目的。
添加新客户端
步骤 1: 创建新客户端文件
- 导航到 vectordb_bench/backend/clients 目录。
- 为您的客户端创建一个新文件夹,例如 "new_client"。
- 在 "new_client" 文件夹中创建两个文件: new_client.py 和 config.py。
步骤 2: 实现 new_client.py 和 config.py
- 打开 new_client.py 并定义 NewClient 类,该类应继承来自 clients/api.py 文件的 VectorDB 抽象类。VectorDB 类充当基准测试的 API,所有 DB 客户端都必须实现此抽象类。 在 new_client.py 中的示例实现:
from ..api import VectorDB class NewClient(VectorDB): # 实现 VectorDB 类中定义的抽象方法 # ...
- 打开 config.py 并实现 DBConfig 和可选的 DBCaseConfig 类。
- DBConfig 类应该是一个抽象类,提供建立��与数据库连接所需的信息。建议使用 pydantic.SecretStr 数据类型处理令牌、URI 或密码等敏感数据。
- DBCaseConfig 类是可选的,允许提供特定于案例的数据库配置。如果未提供,它将默认为 EmptyDBCaseConfig。 在 config.py 中的示例实现:
from pydantic import SecretStr from clients.api import DBConfig, DBCaseConfig class NewDBConfig(DBConfig): # 实现数据库连接所需的必填配置字段 # ... token: SecretStr uri: str class NewDBCaseConfig(DBCaseConfig): # 实现可选的特定于案例的配置字段 # ...
步骤 3: 导入 DB 客户端并更新初始化
在最后一步中,您将导入 DB 客户端到 clients/init.py 并更新初始化过程。
- 打开 clients/init.py 并从 new_client.py 导入您的 NewClient。
- 将您的 NewClient 添加到 DB 枚举中。
- 更新 db2client 字典,为您的 NewClient 添加一个条目。 在 clients/init.py 中的示例实现:
#clients/__init__.py # 将 NewClient 添加到 DB 枚举 class DB(Enum): ... DB.NewClient = "NewClient" @property def init_cls(self) -> Type[VectorDB]: ... if self == DB.NewClient: from .new_client.new_client import NewClient return NewClient ... @property def config_cls(self) -> Type[DBConfig]: ... if self == DB.NewClient: from .new_client.config import NewClientConfig return NewClientConfig ... def case_config_cls(self, ...) if self == DB.NewClient: from .new_client.config import NewClientCaseConfig return NewClientCaseConfig
步骤 4: 实现 new_client/cli.py 和 vectordb_bench/cli/vectordbbench.py 在这个(可选的,但建议添加的)步骤中,您将能够从命令行运行测试。
- 导航到 vectordb_bench/backend/clients/"客户端"目录。
- 在"客户端"文件夹中,创建一个 cli.py 文件。 以 Zilliz 为例,cli.py 如下:
from typing import Annotated, Unpack import click import os from pydantic import SecretStr from vectordb_bench.cli.cli import ( CommonTypedDict, cli, click_parameter_decorators_from_typed_dict, run, ) from vectordb_bench.backend.clients import DB class ZillizTypedDict(CommonTypedDict): uri: Annotated[ str, click.option("--uri", type=str, help="uri 连接字符串", required=True) ] user_name: Annotated[ str, click.option("--user-name", type=str, help="数据库用户名", required=True) ] password: Annotated[ str, click.option("--password", type=str, help="Zilliz 密码", default=lambda: os.environ.get("ZILLIZ_PASSWORD", ""), show_default="$ZILLIZ_PASSWORD", ), ] level: Annotated[ str, click.option("--level", type=str, help="Zilliz 索引级别", required=False), ] @cli.command() @click_parameter_decorators_from_typed_dict(ZillizTypedDict) def ZillizAutoIndex(**parameters: Unpack[ZillizTypedDict]): from .config import ZillizCloudConfig, AutoIndexConfig run( db=DB.ZillizCloud, db_config=ZillizCloudConfig( db_label=parameters["db_label"], uri=SecretStr(parameters["uri"]), user=parameters["user_name"], password=SecretStr(parameters["password"]), ), db_case_config=AutoIndexConfig( params={parameters["level"]}, ), **parameters, )
- 更新 cli 的以下部分:
- 添加数据库特定选项作为 Annotated TypedDict,参见上面的 ZillizTypedDict。
- 添加索引配置特定选项作为 Annotated TypedDict。(示例:vectordb_bench/backend/clients/pgvector/cli.py)
- 如果只有一种索引配置,则可能不需要。
- 对于每种索引配置重复此步骤,并在可能的情况下进行嵌套。
- 添加每种索引类型的索引配置特定函数,参见上面的 Zilliz。 函数名(小写)将是传递给 vectordbbench 命令的命令名。
- 更新 db_config 和 db_case_config 以匹配客户端要求
- 继续为每种索引配置添加新函数。
- 将客户端 cli 模块和命令导入 vectordb_bench/cli/vectordbbench.py(对于有多个命令(索引配置)的数��据库,只需要为一个命令执行此操作)
具有多个索引配置的 cli 模块:
- pgvector: vectordb_bench/backend/clients/pgvector/cli.py
- milvus: vectordb_bench/backend/clients/milvus/cli.py
就这样!您已成功将新的 DB 客户端添加到 vectordb_bench 项目中。
规则: 安装:测试系统可以以任何形式进行安装以实现最佳性能,包括但不限于二进制部署、Docker和云服务。 微调:对于被测系统,我们使用默认的服务器端配置以保持结果的真实性和代表性。对于客户端,我们欢迎任何参数调优以获得更好的结果。 不完整的结果:许多数据库可能由于内存不足、崩溃或超时等问题无法完成所有测试用例。在这些情况下,我们将明确说明这些情况。 错误或失实:我们努力确保准确地了解和支持各种向量数据库,但可能会存在疏忽或误用的情况。对于任何此类情况,欢迎您在我们的 GitHub 页面上提出问题或进行修订。 超时:
- 容量案例:我们为容量案例设置了总体超时时间。
- 其他案例:
- 数据加载超时:这个超时旨在过滤掉插入数据太慢的系统,从而确保我们只考虑能够应对真实生产环境需求的系统。
- 优化准备超时:这个超时是为了避免过度的优化策略,这些策略可能适用于基准测试,但在实际生产环境中失效。通过这样做,我们确保考虑的系统不仅适合测试环境,而且在生产场景中也具有适用性和效率。
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号