




<img src="https://yellow-cdn.veclightyear.com/ab5030c0/72364774-a9fe-40f9-b74a-8ec1ea635c18.png?x-pxid=bc3c57b0-9a65-49fe-b8ea-f711c4d35b82" /><p align="center"> <img src="https://i.imgur.com/nv33goV.png" width="35%"/> </br>
<h1 align="center">数据日志记录的开放标准 </h1> <h3 align="center"> <a href="https://whylogs.readthedocs.io/"><b>文档</b></a> • <a href="https://bit.ly/whylogsslack"><b>Slack 社区</b></a> • <a href="https://github.com/whylabs/whylogs#python-quickstart"><b>Python 快速入门</b></a> • <a href="https://whylogs.readthedocs.io/en/latest/examples/integrations/writers/Writing_to_WhyLabs.html"><b>WhyLabs 快速入门</b></a> </h3> <p align="center"> <a href="https://github.com/whylabs/whylogs-python/blob/mainline/LICENSE" target="_blank"> <img src="https://yellow-cdn.veclightyear.com/ab5030c0/1eebe6c6-7b9e-4030-9670-9666b043d0d1.svg" alt="许可证"> </a> <a href="https://badge.fury.io/py/whylogs" target="_blank"> <img src="https://yellow-cdn.veclightyear.com/ab5030c0/299fea21-7bd8-48ef-bf3d-697636c64ed0.svg" alt="PyPi 版本"> </a> <a href="https://github.com/python/black" target="_blank"> <img src="https://yellow-cdn.veclightyear.com/ab5030c0/3e3101b8-22a6-421a-b0d5-a9e38a785afb.svg" alt="代码风格:black"> </a> <a href="https://pepy.tech/project/whylogs" target="_blank"> <img src="https://pepy.tech/badge/whylogs" alt="PyPi 下载量"> </a> <a href="bit.ly/whylogs" target="_blank"> <img src="https://yellow-cdn.veclightyear.com/ab5030c0/72ed92bc-f8c6-4dcb-bfbd-cb395a630810.svg" alt="CI"> </a> <a href="https://codeclimate.com/github/whylabs/whylogs-python/maintainability" target="_blank"> <img src="https://api.codeclimate.com/v1/badges/442f6ca3dca1e583a488/maintainability" alt="可维护性"> </a> </p>什么是 whylogs
whylogs 是一个用于记录任何类型数据的开源库。通过 whylogs,用户能够生成其数据集的摘要(称为 whylogs 概况),可用于:
- 跟踪数据集的变化
- 创建 数据约束 以了解数据是否符合预期
- 快速可视化数据集的关键统计摘要
这三个功能为数据科学家、机器学习工程师和数据工程师提供了多种用例:
- 检测模型输入特征的数据漂移
- 检测训练-服务偏差、概念漂移和模型性能下降
- 验证模型输入或数据管道中的数据质量
- 对海量数据集进行探索性数据分析
- 跟踪机器学习实验的数据分布和数据质量
- 实现组织范围内的数据审计和治理
- 标准化组织内的数据文档实践
- 等等
如果您有任何问题、评论,或只是想与我们交流,请加入我们的 Slack 社区。除了加入 Slack 社区外,您还可以通过在本页面右上角给我们一个 ⭐ 来帮助这个项目。
Python 快速入门<a name="python-quickstart" />
使用 pip 包管理器安装 whylogs 非常简单,只需在终端中运行 pip install whylogs 即可。
从这里开始,您可以快速记录数据集:
import whylogs as why import pandas as pd #数据框 df = pd.read_csv("path/to/file.csv") results = why.log(df)
就是这样,您现在有了一个 whylogs 概况。要了解更多关于 whylogs 概况是什么以及您可以用它做什么,请继续阅读。
目录
whylogs 概况<a name="whylogs-profiles" />
什么是概况
whylogs 概况是 whylogs 库的核心。它们捕获数据的关键统计属性,如分布(远超简单的均值、中位数和标准差测量)、缺失值的数量以及广泛的可配置自定义指标。通过捕获这些统计摘要,我们能够准确地表示数据,并实现引言中描述的所有用例。
whylogs 概况具有三个特性,使其成为理想的数据日志记录工具:它们是高效的、可定制的和可合并的。
<br /> <img align="left" src="https://yellow-cdn.veclightyear.com/ab5030c0/3d264e2e-1d93-4771-9f02-f32773526a5a.png"> **高效**: whylogs配置文件能够高效地描述它们所代表的数据集。这种对数据集的高保真表示使得whylogs配置文件成为数据的有效快照。正如我们在博文《数据日志记录:采样与分析》中所讨论的那样,它们比样本更能捕捉数据集的特征,而且非常紧凑。 <br /> <img align="left" src="https://yellow-cdn.veclightyear.com/ab5030c0/fd017af8-6d8f-4829-abf3-06a77107796e.png">可定制: whylogs配置文件收集的统计数据很容易配置和定制。这很有用,因为不同的数据类型和用例需要不同的指标,而whylogs用户需要能够轻松定义这些指标的自定义跟踪器。正是whylogs的可定制性使我们能够实现文本、图像和其他复杂数据�跟踪器。
<br /> <img align="left" src="https://yellow-cdn.veclightyear.com/ab5030c0/9cc879b6-dfc3-491f-8821-1708f754be3e.png">可合并: whylogs配置文件最强大的特性之一是它们的可合并性。可合并性意味着whylogs配置文件可以组合在一起,形成代表其组成配置文件总和的新配置文件。这使得分布式和流式系统的日志记录成为可能,并允许用户查看任何时间粒度的汇总数据。
<br />如何生成配置文件
安装whylogs后,在Python和Java环境中都可以轻松生成配置文件。
要在Python中从Pandas数据框生成配置文件,只需运行:
import whylogs as why import pandas as pd #数据框 df = pd.read_csv("path/to/file.csv") results = why.log(df)
配置文件可以做什么
生成whylogs配置文件后,可以做几件事:
在本地Python环境中,你可以设置数据约束或可视化配置文件。对配置文件设置数据约束允许你在数据不符合预期时得到通知,从而进行数据单元测试和基本的数据监控。使用Profile Visualizer,你可以直观地探索数据,了解数据并确保你的ML模型已准备好投入生产。
此外,你可以将whylogs配置文件发送到SaaS ML监控和AI可观察性平台WhyLabs。使用WhyLabs,你可以自动为机器学习模型设置监控,获得数据质量和数据变化问题(如数据漂移)的通知。如果你有兴趣尝试WhyLabs,可以查看永久免费的Starter版本,无需信用卡即可体验整个平台的功能。
WhyLabs
WhyLabs是一个托管服务,旨在帮助用户充分利用他们的whylogs配置文件。通过WhyLabs,用户可以摄取配置文件并设置自动监控,以及全面观察他们的数据和ML系统。使用WhyLabs,用户可以确保数据和模型的可靠性,并调试出现的任何问题。
将whylogs配置文件摄取到WhyLabs很简单。从平台获取��访问凭证后,你需要在Python环境中设置它们,记录数据集,并将其写入WhyLabs,如下所示:
import whylogs as why import os os.environ["WHYLABS_API_KEY"] = "YOUR-API-KEY" os.environ["WHYLABS_DEFAULT_DATASET_ID"] = "model-0" # 选定的模型项目"MODEL-NAME"为"model-0" results = why.log(df) results.writer("whylabs").write()
.gif%3E)
如果你有兴趣尝试WhyLabs,可以查看永久免费的Starter版本,无需信用卡即可体验整个平台的功能。
数据约束
约束是基于whylogs配置文件构建的一个强大功能,使你能够快速轻松地验证数据是否符合预期。你可以对数据设置多种类型的约束(例如,数值数据始终在特定范围内,文本数据始终为JSON格式等),如果数据集未能满足约束,你可以使单元测试或CI/CD管道失败。
设置和测试约束的简单示例如下:
import whylogs as why from whylogs.core.constraints import Constraints, ConstraintsBuilder from whylogs.core.constraints.factories import greater_than_number profile_view = why.log(df).view() builder = ConstraintsBuilder(profile_view) builder.add_constraint(greater_than_number(column_name="col_name", number=0.15)) constraints = builder.build() constraints.report()
要了解更多关于约束的信息,请查看: 约束示例。
配置文件可视化
除了能够自动获得关于数据潜在问题的通知外,手动检查数据也很有用。使用配置文件可视化工具,你可以在Jupyter笔记本环境中直接生成关于配置文件的交互式报告(单个配置文件或比较配置文件)。这使得探索性数据分析、数据漂移检测和数据可观察性成为可能。
要访问配置文件可视化工具,请在终端中运行pip install "whylogs[viz]"安装whylogs的[viz]模块。我们可以创建的一种配置文件可视化是漂移报告;以下是分析两个配置文件之间漂移的简单示例:
import whylogs as why from whylogs.viz import NotebookProfileVisualizer result = why.log(pandas=df_target) prof_view = result.view() result_ref = why.log(pandas=df_reference) prof_view_ref = result_ref.view()
visualization = NotebookProfileVisualizer() visualization.set_profiles(目标_profile_view=prof_view, 参考_profile_view=prof_view_ref)
visualization.summary_drift_report()
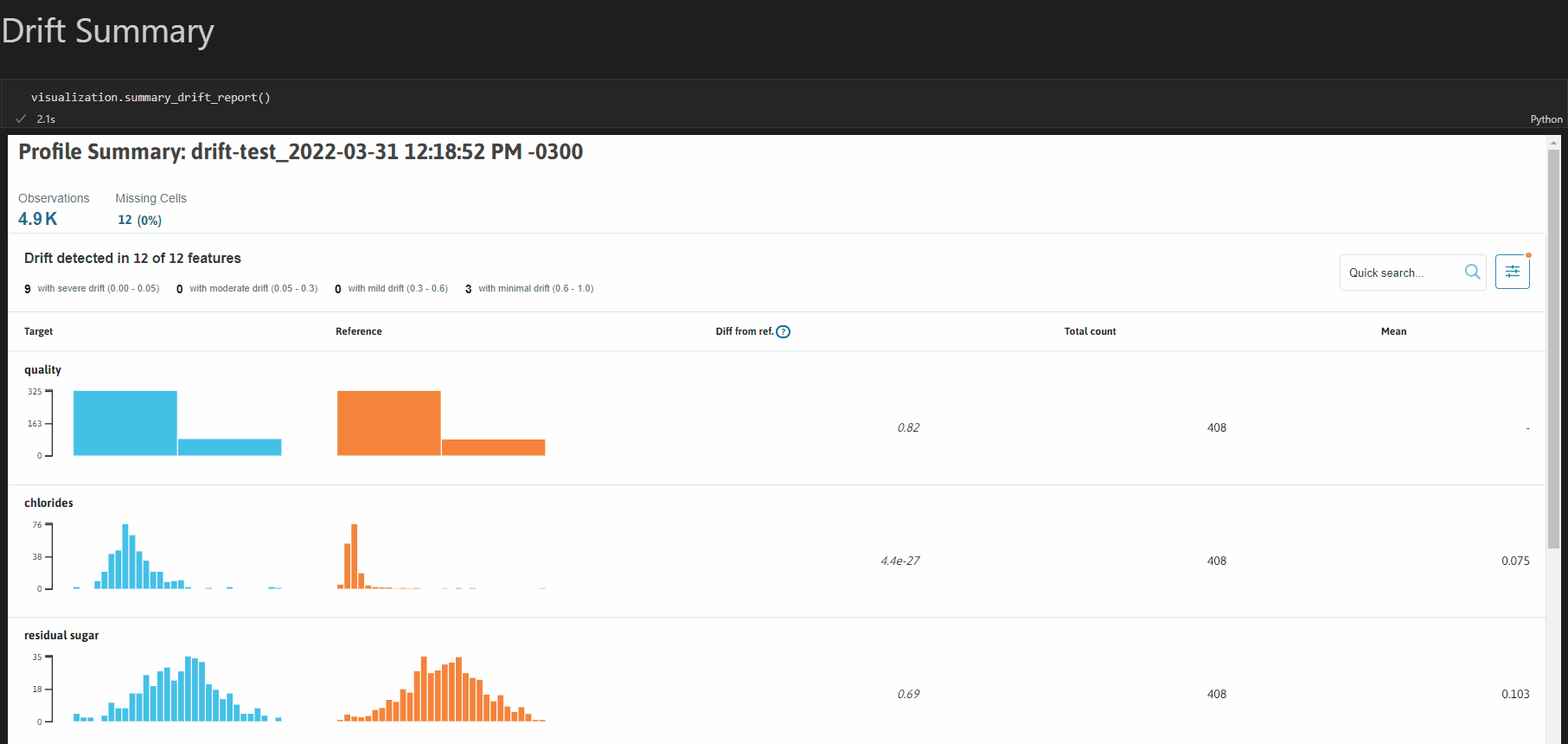
要了解更多关于可视化配置文件的信息,请查看:[可视化器示例](https://bit.ly/whylogsvisualizerexample)
## 数据类型<a name="data-types" />
whylogs 支持结构化和非结构化数据,具体包括:
| 数据类型 | 功能 | Notebook 示例 |
| -------- | ---- | ------------- |
| 表格数据 | ✅ | [结构化数据入门](https://github.com/whylabs/whylogs/blob/mainline/python/examples/basic/Getting_Started.ipynb) |
| 图像数据 | ✅ | [图像入门](https://github.com/whylabs/whylogs/blob/mainline/python/examples/advanced/Image_Logging.ipynb) |
| 文本数据 | ✅ | [字符串特征](https://github.com/whylabs/whylogs/blob/maintenance/0.7.x/examples/String_Features.ipynb) |
| 嵌入 | ✅ | [嵌入距离记录](https://github.com/whylabs/whylogs/blob/mainline/python/examples/experimental/embeddings/Embeddings_Distance_Logging.ipynb) |
| 其他数据类型 | ✋ | 您是否有未在此列出的数据类型请求?提出问题或加入我们的 Slack 社区并提出请求!我们随时乐意帮助 |
## 集成

whylogs 可以无缝地与数据和 ML 管道中的不同工具交互。我们目前已经与以下工具集成:
- AWS S3
- Apache Airflow
- Apache Spark
- Mlflow
- GCS
以及更多!
如果您想查看我们的完整列表,请参阅我们的[集成示例](https://github.com/whylabs/whylogs/tree/mainline/python/examples/integrations)页面。
## 示例
有关我们示例的完整集合,请查看[示例文件夹](https://github.com/whylabs/whylogs/tree/mainline/python/examples)。
## whylogs 的基准测试
根据设计,whylogs 直接在数据管道中或在边车容器中运行,并使用高度可扩展的流式算法来计算统计数据。由于使用 whylogs 进行数据记录发生在处理原始数据的相同基础设施中,因此考虑计算开销很重要。对于大多数用例,开销是最小的,通常低于 1%。对于具有数千个特征和 10M+ QPS 的非常大的数据量,它可能会增加约 5% 的开销。然而,对于大数据量,客户通常处于分布式环境中,如 Ray 或 Apache Spark。这意味着他们受益于 whylogs 的并行化——以及 whylogs 配置文件的可映射可归约属性,将计算开销保持在最低水平。
以下是基准测试,以演示 whylogs 在使用默认配置(跟踪分布、缺失值、计数、基数和模式)处理表格数据时的效率。这种方法的两个重要优势是并行化加快了计算速度,并且 whylogs 随特征数量而不是行数而扩展。在[这里](https://docs.whylabs.ai/docs/scaling)了解更多关于 whylogs 如何扩展的信息。
| 数据量 | 运行 whylogs 的总成本 | 实例类型 | 集群大小 | 处理时间 |
| ---------------------------- | :--------------------------------: | :-------------------------------------------: | -------: | ---------------------------------------------: |
| 10 GB ~34M 行 x 43 列 | ~ $ 0.026 每 10 GB,或 $2.45 每 TB | c5a.2xlarge,8 CPU 16GB RAM,每小时 $0.308 按需价格 | 2 个实例 | 每个实例 2.6 分钟配置时间(并行运行) |
| 10 GB,~34M 行 x 43 列 | ~ $0.016 每 10 GB,估计 $1.60 每 TB | c6g.2xlarge,8 CPU 16GB RAM,每小时 $0.272 按需价格 | 2 个实例 | 每个实例 1.7 分钟配置时间(并行运行) |
| 10 GB ~34M 行 x 43 列 | ~ $ 0.045 每 10 GB | c5a.2xlarge,8 CPU 16GB RAM,每小时 $0.308 按需价格 | 16 个实例 | 每个实例 33 秒配置时间(并行运行) |
| 80 GB,83M 行 x 119 列 | ~ $0.139 每 80 GB | c5a.2xlarge,8 CPU 16GB RAM,每小时 $0.308 按需价格 | 16 个实例 | 每个实例 1.7 分钟配置时间(并行运行) |
| 100 GB,290M 行 x 43 列 | ~ $0.221 每 100 GB | c5a.2xlarge,8 CPU 16GB RAM,每小时 $0.308 按需价格 | 16 个实例 | 每个实例 2.7 分钟配置时间(并行运行) |
## 使用统计<a name="whylogs-profiles" />
从 whylogs v1.0.0 开始,whylogs 默认收集有关用户环境的匿名信息。这些使用统计不包括有关用户或他们正在分析的数据的任何信息,仅包括用户运行 whylogs 的环境。
要了解更多关于 whylogs 收集的使用统计信息,请查看相关[文档](https://docs.whylabs.ai/docs/usage-statistics/)。
要关闭使用统计,只需将 `WHYLOGS_NO_ANALYTICS` 环境变量设置为 True,如下所示:
```python
import os
os.environ['WHYLOGS_NO_ANALYTICS']='True'
社区
如果您有任何问题、评论或只是想与我们交流,请加入我们的 Slack 频道。
贡献
如何贡献
我们欢迎对whylogs的贡献。请查看我们的贡献指南和开发指南以了解详情。
贡献者
<a href="https://github.com/whylabs/whylogs/graphs/contributors"> <img src="https://contrib.rocks/image?repo=whylabs/whylogs" /> </a>使用contrib.rocks制作。
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号