



<div align="center"> <b>驱动</b>: Python • C • C++ • GoLang • Java <br/> <b>包</b>: <a href="https://pypi.org/project/ukv/">PyPI</a> • <a href="#cmake">CMake</a> • <a href="https://hub.docker.com/repository/docker/unum/ustore">Docker Hub</a>
<a href="https://www.youtube.com/watch?v=ybWeUf_hC7o">Youtube</a> 介绍 • <a href="https://discord.gg/4mxGrenbNt">Discord</a> 聊天 • 完整 <a href="https://unum-cloud.github.io/ustore">文档</a>
<a href="https://discord.gg/4mxGrenbNt"><img src="https://img.shields.io/discord/1063947616615923875?label=discord"></a> <a href="https://www.linkedin.com/company/unum-cloud/"><img src="https://yellow-cdn.veclightyear.com/835a84d5/96e30c27-b31f-4b41-9a4c-1595e56be943.svg?"/></a> <a href="https://twitter.com/unum_cloud"><img src="https://yellow-cdn.veclightyear.com/835a84d5/cadf9329-5f13-4bbe-b77d-a70ad4effe88.svg?"/></a> <a href="https://zenodo.org/badge/latestdoi/502647695"><img src="https://yellow-cdn.veclightyear.com/835a84d5/bcc86041-7307-4834-903b-0a09cfb8eec8.svg" alt="DOI"></a> <a href="https://www.github.com/unum-cloud/"><img src="https://img.shields.io/github/issues-closed-raw/unum-cloud/ustore?"/></a> <a href="https://www.github.com/unum-cloud/"><img src="https://img.shields.io/github/stars/unum-cloud/ustore?"/></a> � <a href="#"><img src="https://img.shields.io/github/workflow/status/unum-cloud/ustore/Build"/></a>
</div>快速开始
安装UStore非常简单,使用起来就像Python的dict一样简单。
$ pip install ukv $ python from ukv import umem db = umem.DataBase() db.main[42] = 'Hi'
我们刚刚创建了一个内存嵌入式事务性数据库,并在其main集合中添加了一个条目。
你想要将数据存储在磁盘上吗?
只需更改一行代码。
from ukv import rocksdb db = rocksdb.DataBase('/some-folder/')
你想要连接到远程UStore服务器吗? UStore带有Apache Arrow Flight RPC接口!
from ukv import flight_client db = flight_client.DataBase('grpc://0.0.0.0:38709')
你是否在存储类似[NetworkX][networkx]的MultiDiGraph?
或者类似[Pandas][pandas]的DataFrame?
db = rocksdb.DataBase() users_table = db['users'].table users_table.merge(pd.DataFrame([ {'id': 1, 'name': 'Lex', 'lastname': 'Fridman'}, {'id': 2, 'name': 'Joe', 'lastname': 'Rogan'}, ])) friends_graph = db['friends'].graph friends_graph.add_edge(1, 2) assert friends_graph.has_edge(1, 2) and \ friends_graph.has_node(1) and \ friends_graph.number_of_edges(1, 2) == 1
函数调用看起来可能相同,但底层实现可能涉及处理远程机器持久内存中的数百TB数据。
是否有其他人同时更新这些集合? 将操作捆绑在一起以保证一致性!
db = rocksdb.DataBase() with db.transact() as txn: txn['users'].table.merge(...) txn['friends'].graph.add_edge(1, 2)
到目前为止,我们仅涉及了UStore的冰山一角。 您可以使用它来...
- 获取RocksDB或LevelDB的C99、Python、GoLang或Java包装器。
- 通过Apache Arrow Flight RPC将它们提供给Spark、Kafka或PyTorch。
- 在嵌入式数据库中存储文档和图形,避免网络开销。
- 在一个API下将DBMS分层为内存和持久化后端。
但UStore能做的更多。 以下是功能地图:
- 基�本用法:
- 高级用法 用于生产、性能调优和管理:
- 对于希望分叉、扩展、封装或分发并可能货币化UStore替代版本的贡献者和高级用户:
- [架构和依赖 ∆][ustore-architecture]
- [路线图 ∆][ustore-roadmap]
- [贡献 ∆][ustore-contributing]
基本用法
UStore不仅是一个数据库,还是一个"构建您自己的数据库"工具包和潜在事务性NoSQL数据库的开放标准,为"创建、读取、更新、删除"操作(简称CRUD)定义零拷贝二进制接口。
几个简单的C99头文件可以将几乎任何底层存储引擎链接到众多高级语言驱动程序,将其对二进制字符串值的支持扩展到图、灵活模式文档和其他模态,旨在用单一的ACID事务系统取代MongoDB、Neo4J、Pinecone和ElasticSearch。

例如,Redis提供了RediSearch、RedisJSON和RedisGraph,具有类似的目标。UStore做得更好,允许您添加您喜欢的键值存储(KVS),无论是嵌入式、独立还是分片的,如FoundationDB,从而倍增其功能。
模态
二进制大对象
二进制大对象可以放置在UStore中。性能会根据所使用的底层技术而有很大差异。内存中的UCSet将是最快的,但最不适合较大的对象。当正确配置时,持久化的UDisk可以完全绕过Linux内核,包括文件系统层,直接访问块设备。

在高端服务器上,基于用户空间驱动程序(如SPDK)构建的现代持久化IO每个套接字可以超过100 GB/s。这接近高端RAM的实际吞吐量,并解锁了数据库中不常见的新用例。现在可以将一个GB级的视频文件放入ACID事务数据库中,就在其元数据旁边,而不是使用单独的对象存储,如MinIO。
文档
JSON是当今最常用的文档格式。UStore文档集合支持JSON,以及MessagePack和MongoDB使用的BSON。

UStore目前还不支持水平扩展,但提供了更高的单节点性能,并且由于使用了开源的simdjson和yyjson库,在多核系统上几乎呈线性的垂直扩展性。
此外,与数据交互时,您不需要像MQL这样的自定义查询语言。
相反,我们优先考虑开放的RFC标准,以真正避免供应商锁定:
- JSON指针:RFC 6901用于定位嵌套字段。
- JSON补丁:RFC 6902用于字段级更新。
- JSON合并补丁:RFC 7386用于文档级更新。
图
现代图数据库,如Neo4J,在处理大型工作负载时面临挑战。 它们需要过多的RAM,并且其算法一次只能观察一个数据条目。 我们在两个方面进行了优化:
- 使用增量编码压缩倒排索引。
- 更新经典图算法以适应高延迟存储,以批处理或边缘中心的方式处理图。
向量
特征存储和向量数据库,如Pinecone、Milvus和USearch,为向量搜索提供独立的索引。 UStore将其实现为一种独立的模态,与文档和图形并列。 特性:
- 8位整数量化。
- 16位浮点数量化。
- 余弦、内积和欧几里得度量。
驱动程序
UStore的Python和C++版本看起来很不一样。 我们的Python SDK模仿了其他Python库 - [Pandas][pandas]和[NetworkX][networkx]。 同样,C++库提供了C++开发者所期望的接口。
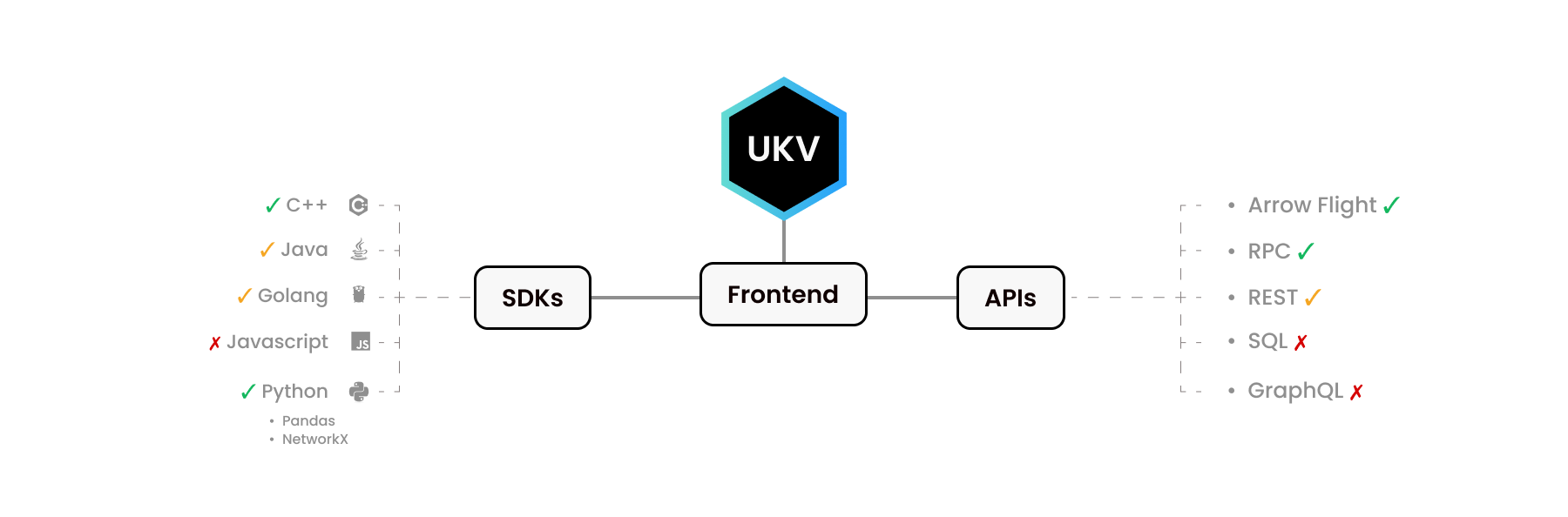
众所周知,人们使用不同的语言来满足不同的需求。 某些C级功能并未在某些语言中实现。 这或是因为没有需求,或是我们还没有来得及实现。
| 名称 | 事务 | 集合 | 批处理 | 文档 | 图 | 副本 |
|---|---|---|---|---|---|---|
| [C99标准][ustore-c] | ✓ | ✓ | ✓ | ✓ | ✓ | 0 |
| [C++ SDK][ustore-cpp] | ✓ | ✓ | ✓ | ✓ | ✓ | 0 |
| [Python SDK][ustore-python] | ✓ | ✓ | ✓ | ✓ | ✓ | 0-1 |
| [GoLang SDK][ustore-golang] | ✓ | ✓ | ✓ | ✗ | ✗ | 1 |
| [Java SDK][ustore-java] | ✓ | ✓ | ✗ | ✗ | ✗ | 1 |
| Arrow Flight API | ✓ | ✓ | ✓ | ✓ | ✓ | 0-2 |
这里的一些前端有其自己的完整生态系统! 例如,[Apache Arrow Flight][flight] API拥有自己的C、C++、C#、Go、Java、JavaScript、Julia、MATLAB、Python、R、Ruby和Rust驱动程序。
常见问题解答
常见问题
- 事务默认是ACI(D)的。这意味着什么?
- 为什么不使用LevelDB或RocksDB接口?已回答
- 为什么不使用SQL、MQL或CYPHER?已回答
- UStore是否支持生存时间(TTL)?已回答
- UStore是否支持压缩?已回答
- UStore是否支持队列?已回答
- 如何为语言X添加驱动程序?[已回答][ustore-new-drivers]
- 如何将数据库X添加为引擎?[已回答][ustore-new-engine]
高级用法
引擎
以下引擎几乎可以互换使用。 从历史上看,LevelDB是第一个。 然后RocksDB在功能和性能上进行了改进。 现在它成为了一半DBMS创业公司的基础。
| LevelDB | RocksDB | UDisk | UCSet | |
|---|---|---|---|---|
| 速度 | 1x | 2x | 10x | 30x |
| 持久化 | ✓ | ✓ | ✓ | ✗ |
| 事务支持 | ✗ | ✓ | ✓ | ✓ |
| 块设备支持 | ✗ | ✗ | ✓ | ✗ |
| 加密 | ✗ | ✗ | ✓ | ✗ |
| [监视][watch] | ✗ | ✓ | ✓ | ✓ |
| 快照 | ✓ | ✓ | ✓ | ✗ |
| 随机采样 | ✗ | ✗ | ✓ | ✓ |
| 批量枚举 | ✗ | ✗ | ✓ | ✓ |
| 命名集合 | ✗ | ✓ | ✓ | ✓ |
| 开源 | ✓ | ✓ | ✗ | ✓ |
| 兼容性 | 任何 | 任何 | Linux | 任何 |
| 维护者 | Unum | Unum |
UCSet和UDisk都由Unum设计和维护。 两者都功能完备,但我们的替代方案提供的最关键特性是性能。 在内存中实现高速很容易。 UCSet的核心逻辑可以在模板化的仅头文件<code class="docutils literal notranslate"><a href="https://github.com/unum-cloud/ucset" class="pre">ucset</a></code>库中找到。
设计UDisk是一项更具挑战性的7年长期努力。
它包括发明新的树状结构、实现使用io_uring的部分内核旁路、使用SPDK的完全旁路、CUDA GPU加速,甚至自定义内部文件系统。
UDisk是第一个从头开始设计时就考虑并行架构和内核旁路的引擎。
事务
原子性
始终保证原子性。 即使在非事务性写入中 - 要么所有更新都通过,要么全部失败。
一致性
一致性以最严格的形式实现 - "严格可串行化",意味着:
然而,默认行为可以在特定操作级别进行调整。
为此,可以将::ustore_option_transaction_dont_watch_k传递给ustore_transaction_init()或任何事务性读/写操作,以控制暂存期间的一致性检查。
| 读取 | 写入 | |
|---|---|---|
| 头部 | 严格可串行化 | 严格可串行化 |
| 基于快照的事务 | 可串行化 | 严格可串行化 |
| 不带快照的事务 | 严格可串行化 | 严格可串行化 |
| 不带监视的事务 | 严格可串行化 | 顺序性 |
如果你对这个主题不熟悉,请查看Jepsen.io关于一致性的博客。
隔离性
| 读取 | 写入 | |
|---|---|---|
| 基于快照的事务 | ✓ | ✓ |
| 不带快照的事务 | ✗ | ✓ |
持久性
持久性在定义上不适用于内存系统。 在混合或持久系统中,我们倾向于默认禁用它。 几乎每个构建在KVS之上的DBMS都倾向于实现自己的持久性机制。 在分布式数据库中更是如此,可能存在三个独立的预写日志:
- 在KVS中,
- 在DBMS中,
- 在分布式共识实现中。
如果你仍然需要持久性,可以在提交时使用可选标志刷新写入。
在[C驱动][ustore-c]中,你可以使用::ustore_option_write_flush_k标志调用ustore_transaction_commit()。
容器和云部署
整个DBMS适合放入一个不到100 MB的Docker镜像中。
运行以下脚本来拉取和运行容器,在端口38709上暴露[Apache Arrow Flight][flight]服务器。
客户端SDK默认也将通过该端口通信。
docker run -d --rm --name ustore-test -p 38709:38709 unum/ustore
可以通过以下命令获取默认配置文件:
cat /var/lib/ustore/config.json
最简单的连接和测试方法是以下命令:
python ...
UStore的预打包镜像在多个平台上可用:
不要hesitate商业化和重新分发UStore。
配置
调优数据库既是艺术也是科学。 像RocksDB这样的项目提供了数十个旋钮来优化行为。 我们允许将专门的配置文件转发给底层引擎。
{ "version": "1.0", "directory": "./tmp/" }
我们还有一个更简单的过程,对80%的用户来说已经足够。 这可以扩展到利用多个设备或目录,或转发专门的引擎配置。
{ "version": "1.0", "directory": "/var/lib/ustore", "data_directories": [ { "path": "/dev/nvme0p0/", "max_size": "100GB" }, { "path": "/dev/nvme1p0/", "max_size": "100GB" } ], "engine": { "config_file_path": "./engine_rocksdb.ini", } }
数据库集合也可以用JSON文件配置。
键大小
在当前版本中,使用64位有符号整数。
它允许在[0, 2^63)范围内的唯一键。
支持128位构建和UUID的版本即将推出,但强烈不建议使用可变长度键。
为什么呢?
使用可变长度的键会给键值存储的设计带来诸多限制。
首先,这意味着需要进行缓慢的逐字符比较——这在现代超标量CPU上会严重影响性能。
其次,它迫使键和值必须在磁盘上相邻存储,以最小化导航所需的元数据。
最后,它违背了我们对KVS作为"持久内存分配器"的简单逻辑视图,给它增加了更多责任。
处理字符串键的推荐方法是:
- 选择一种机制来生成唯一的整数键(UID)。例如:单调递增的值。
- 使用"路径"模式构建一个字符串到UID的持久哈希映射。
- 使用这些UID在二进制、文档和图形模式中处理其余数据。
这将导致从字符串到整数表示的单一转换点,并使系统大部分保持快速响应,同时使C级接口比原本可能的更简单。
值大小
目前我们只能处理4 GB或更小的值。 为什么? 键值存储通常用于高频操作。 在现代硬件上,频繁(每秒数千次)访问和修改4 GB及更大的文件是不可能的。 因此我们坚持使用较小的长度类型,这使得使用Apache Arrow表示稍微容易一些,并允许KVS更好地压缩索引。
路线图
我们的[开发路线图][ustore-roadmap]是公开的,托管在GitHub仓库中。 即将进行的任务包括:
- 为Arm、MacOS构建。
- 持久性快照。
- 连续复制。
- 文档模式验证。
- 更丰富的GoLang、Java、JavaScript驱动程序。
- 改进的向量搜索。
- 集合级配置。
- 拥有所有权和非拥有所有权的C++封装器。
- 水平扩展。
[在我们的文档中阅读完整路线图][ustore-architecture]。
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好�的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐�工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号