
IP-Adapter
轻量级图像提示适配器提升文图生成效果
IP-Adapter是一款轻量高效的图像提示适配器,仅需22M参数即可为预训练文本到图像扩散模型提供图像提示功能。它不仅性能卓越,还可泛化到其他自定义模型,与现有控制工具兼容实现可控生成。IP-Adapter支持图像和文本提示配合使用,实现多模态图像生成,为AI图像生成领域带来新的可能性。




IP-Adapter:用于文本到图像扩散模型的文本兼容图像提示适配器
<a href='https://ip-adapter.github.io'><img src='https://img.shields.io/badge/项目-主页-green'></a>
<a href='https://arxiv.org/abs/2308.06721'><img src='https://img.shields.io/badge/技术-报告-red'></a>
<a href='https://huggingface.co/h94/IP-Adapter'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-模型-blue'></a>

介绍
我们提出了IP-Adapter,这是一个高效轻量的适配器,可为预训练的文本到图像扩散模型实现图像提示功能。一个仅有22M参数的IP-Adapter可以达到与微调图像提示模型相当甚至更好的性能。IP-Adapter不仅可以推广到从同一基础模型微调的其他自定义模型,还可以使用现有的可控工具进行可控生成。此外,图像提示还可以与文本提示很好地配合使用,实现多模态图像生成。
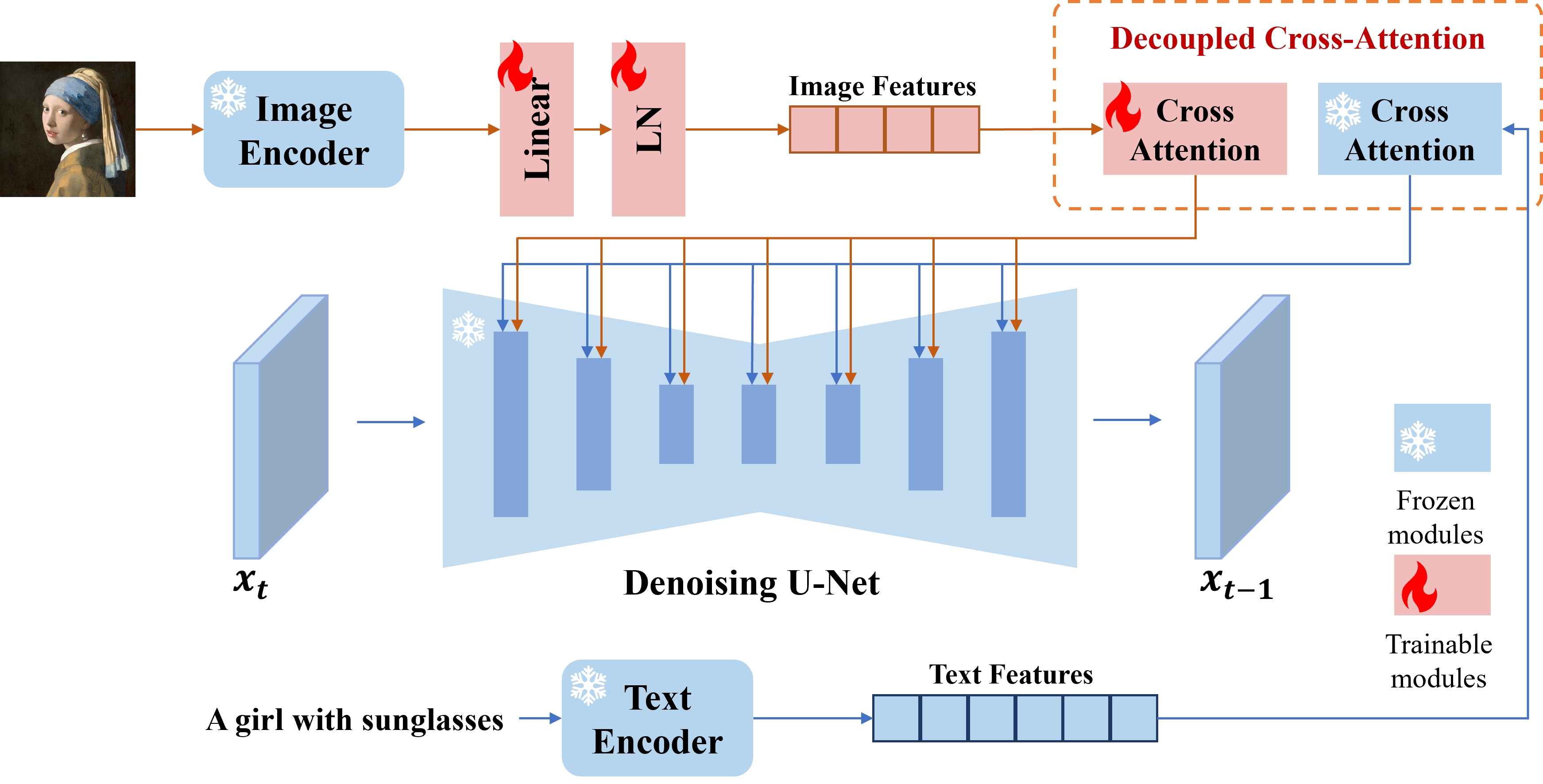
发布
- [2024/01/19] 🔥 新增IP-Adapter-FaceID-Portrait,更多信息可在此处查看。
- [2024/01/17] 🔥 新增SDXL的IP-Adapter-FaceID-PlusV2实验版本,更多信息可在此处查看。
- [2024/01/04] 🔥 新增SDXL的IP-Adapter-FaceID实验版本,更多信息可在此处查看。
- [2023/12/29] 🔥 新增IP-Adapter-FaceID-PlusV2实验版本,更多信息可在此处查看。
- [2023/12/27] 🔥 新增IP-Adapter-FaceID-Plus实验版本,更多信息可在此处查看。
- [2023/12/20] 🔥 新增IP-Adapter-FaceID实验版本,更多信息可在此处查看。
- [2023/11/22] 感谢Diffusers团队,IP-Adapter现已在Diffusers中可用。
- [2023/11/10] 🔥 新增更新版本的IP-Adapter-Face。演示在此处。
- [2023/11/05] 🔥 新增使用IP-Adapter和Kandinsky 2.2 Prior的文本到图像演示
- [2023/11/02] 支持safetensors
- [2023/9/08] 🔥 更新SDXL_1.0的IP-Adapter新版本。更多信息可在此处查看。
- [2023/9/05] 🔥🔥🔥 IP-Adapter现已在WebUI和ComfyUI(或ComfyUI_IPAdapter_plus)中得到支持。
- [2023/8/30] 🔥 新增以人脸图像为提示的IP-Adapter。演示在此处。
- [2023/8/29] 🔥 发布训练代码。
- [2023/8/23] 🔥 新增具有细粒度特征的IP-Adapter代码和模型。演示在此处。
- [2023/8/18] 🔥 为SDXL 1.0新增代码和模型。演示在此处。
- [2023/8/16] 🔥 我们发布了代��码和模型。
安装
# 安装最新的diffusers
pip install diffusers==0.22.1
# 安装ip-adapter
pip install git+https://github.com/tencent-ailab/IP-Adapter.git
# 下载模型
cd IP-Adapter
git lfs install
git clone https://huggingface.co/h94/IP-Adapter
mv IP-Adapter/models models
mv IP-Adapter/sdxl_models sdxl_models
# 然后您可以使用notebook
下载模型
您可以从这里下载模型。要运行演示,您还应下载以下模型:
- runwayml/stable-diffusion-v1-5
- stabilityai/sd-vae-ft-mse
- SG161222/Realistic_Vision_V4.0_noVAE
- ControlNet模型
使用方法
SD_1.5
- ip_adapter_demo:使用图像提示进行图像变体、图像到图像和修复。




- ip_adapter_controlnet_demo, ip_adapter_t2i-adapter:使用图像提示进行结构化生成。


- ip_adapter_multimodal_prompts_demo:使用多模态提示进行生成。

- ip_adapter-plus_demo:具有细粒度特征的IP-Adapter演示。


- ip_adapter-plus-face_demo:使用人脸图像作为提示进行生成。
 最佳实践
最佳实践
- 如果您只使用图像提示,可以将
scale设置为1.0,并将text_prompt设置为""(或一些通用的文本提示,如"最佳质量",您也可以使用任何负面文本提示)。如果降低scale,可以生成更多样化的图像,但可能与图像提示的一致性较差。 - 对于多模态提示,您可以调整
scale以获得最佳结果。在大多数情况下,设置scale=0.5可以获得良好的效果。对于SD 1.5版本,我们建议使用社区模型来生成优质图像。
非方形图像的IP-Adapter
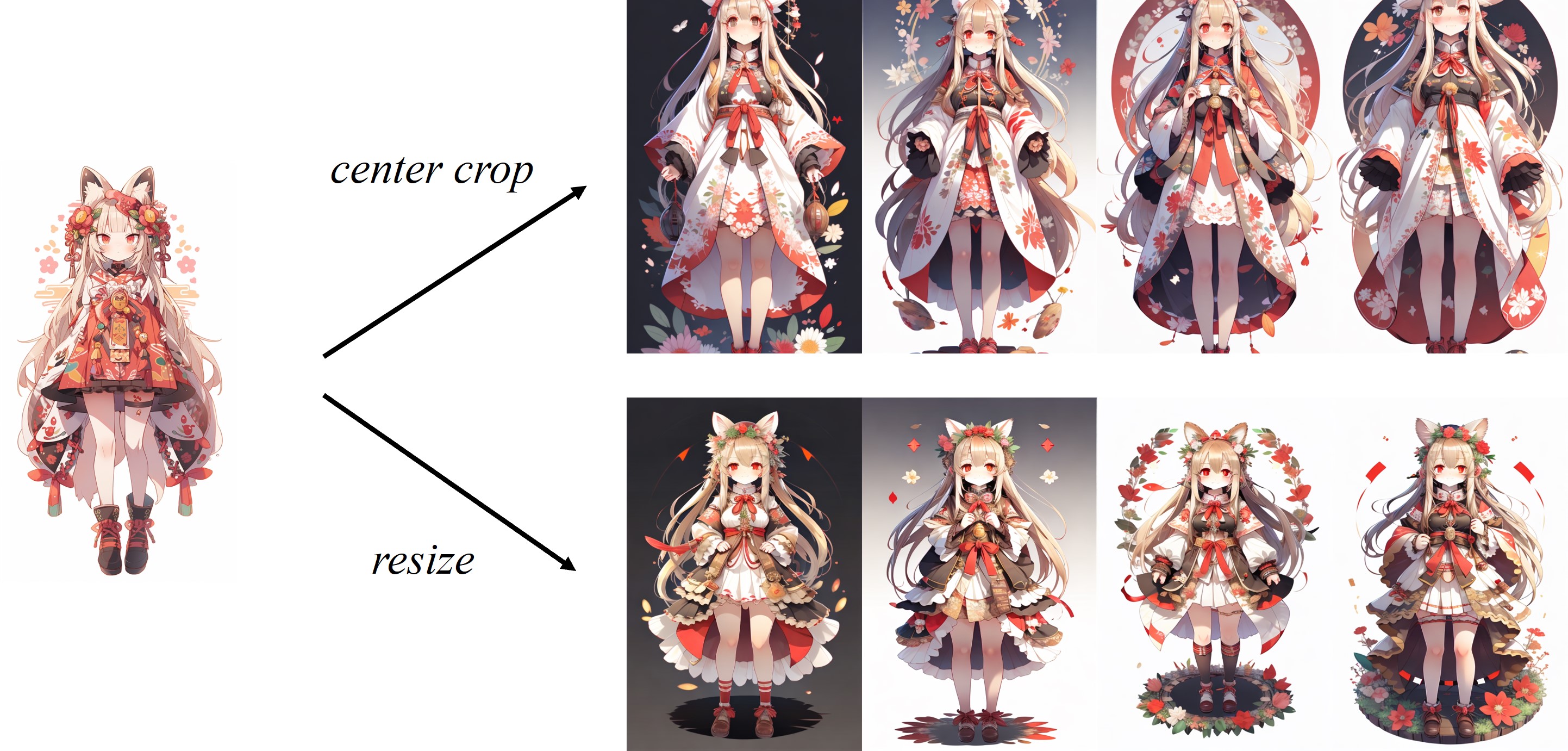
由于CLIP默认的图像处理器会对图像进行中心裁剪,IP-Adapter对方形图像效果最佳。对于非方形图像,它会丢失中心以外的信息。但您可以直接将非方形图像调整为224x224,对比如下:
SDXL_1.0
- ip_adapter_sdxl_demo:使用图像提示的图像变体。
- ip_adapter_sdxl_controlnet_demo:使用图像提示的结构化生成。
IP-Adapter_XL与Reimagine XL的对比如下:

新版本的改进(2023.9.8):
- 切换到CLIP-ViT-H:我们使用OpenCLIP-ViT-H-14而不是OpenCLIP-ViT-bigG-14训练了新的IP-Adapter。尽管ViT-bigG比ViT-H大得多,但我们的实验结果并未发现显著差异,较小的模型可以减少推理阶段的内存使用。
- 更快更好的训练方法:在之前的版本中,直接在1024x1024分辨率下训练效率极低。然而,在新版本中,我们实施了更有效的两阶段训练策略。首先,我们在512x512分辨率下进行预训��练。然后,我们采用多尺度策略进行微调。(也许这种训练策略也可以用来加速controlnet的训练)。
如何训练
要进行训练,您需要安装accelerate并将您自己的数据集制作成json文件。
accelerate launch --num_processes 8 --multi_gpu --mixed_precision "fp16" \
tutorial_train.py \
--pretrained_model_name_or_path="runwayml/stable-diffusion-v1-5/" \
--image_encoder_path="{image_encoder_path}" \
--data_json_file="{data.json}" \
--data_root_path="{image_path}" \
--mixed_precision="fp16" \
--resolution=512 \
--train_batch_size=8 \
--dataloader_num_workers=4 \
--learning_rate=1e-04 \
--weight_decay=0.01 \
--output_dir="{output_dir}" \
--save_steps=10000
训练完成后,您可以使用以下代码转换权重:
import torch ckpt = "checkpoint-50000/pytorch_model.bin" sd = torch.load(ckpt, map_location="cpu") image_proj_sd = {} ip_sd = {} for k in sd: if k.startswith("unet"): pass elif k.startswith("image_proj_model"): image_proj_sd[k.replace("image_proj_model.", "")] = sd[k] elif k.startswith("adapter_modules"): ip_sd[k.replace("adapter_modules.", "")] = sd[k] torch.save({"image_proj": image_proj_sd, "ip_adapter": ip_sd}, "ip_adapter.bin")
第三方使用
- WebUI的IP-Adapter [发布说明]
- ComfyUI的IP-Adapter [IPAdapter-ComfyUI 或 ComfyUI_IPAdapter_plus]
- InvokeAI的IP-Adapter [发布说明]
- AnimateDiff提示旅行的IP-Adapter
- Diffusers_IPAdapter:更多功能,如支持多个输入图像
- 官方Diffusers
- InstantStyle:基于IP-Adapter的风格迁移
免责声明
本项目致力于为AI驱动的图像生成领域带来积极影响。用户可以自由使用此工具创建图像,但需遵守当地法律并负责任地使用。开发者不对用户可能的滥用行为承担任何责任。
引用
如果您发现IP-Adapter对您的研究和应用有用,请使用以下BibTeX进行引用:
@article{ye2023ip-adapter, title={IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models}, author={Ye, Hu and Zhang, Jun and Liu, Sibo and Han, Xiao and Yang, Wei}, booktitle={arXiv preprint arxiv:2308.06721}, year={2023} }
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号