



dockprom
A monitoring solution for Docker hosts and containers with Prometheus, Grafana, cAdvisor, NodeExporter and alerting with AlertManager.
Install
Clone this repository on your Docker host, cd into dockprom directory and run compose up:
git clone https://github.com/stefanprodan/dockprom cd dockprom ADMIN_USER='admin' ADMIN_PASSWORD='admin' ADMIN_PASSWORD_HASH='$2a$14$1l.IozJx7xQRVmlkEQ32OeEEfP5mRxTpbDTCTcXRqn19gXD8YK1pO' docker-compose up -d
Caddy v2 does not accept plaintext passwords. It MUST be provided as a hash value. The above password hash corresponds to ADMIN_PASSWORD 'admin'. To know how to generate hash password, refer Updating Caddy to v2
Prerequisites:
- Docker Engine >= 1.13
- Docker Compose >= 1.11
Updating Caddy to v2
Perform a docker run --rm caddy caddy hash-password --plaintext 'ADMIN_PASSWORD' in order to generate a hash for your new password.
ENSURE that you replace ADMIN_PASSWORD with new plain text password and ADMIN_PASSWORD_HASH with the hashed password references in docker-compose.yml for the caddy container.
Containers:
- Prometheus (metrics database)
http://<host-ip>:9090 - Prometheus-Pushgateway (push acceptor for ephemeral and batch jobs)
http://<host-ip>:9091 - AlertManager (alerts management)
http://<host-ip>:9093 - Grafana (visualize metrics)
http://<host-ip>:3000 - NodeExporter (host metrics collector)
- cAdvisor (containers metrics collector)
- Caddy (reverse proxy and basic auth provider for prometheus and alertmanager)
Setup Grafana
Navigate to http://<host-ip>:3000 and login with user admin password admin. You can change the credentials in the compose file or by supplying the ADMIN_USER and ADMIN_PASSWORD environment variables on compose up. The config file can be added directly in grafana part like this
grafana: image: grafana/grafana:7.2.0 env_file: - config
and the config file format should have this content
GF_SECURITY_ADMIN_USER=admin GF_SECURITY_ADMIN_PASSWORD=changeme GF_USERS_ALLOW_SIGN_UP=false
If you want to change the password, you have to remove this entry, otherwise the change will not take effect
- grafana_data:/var/lib/grafana
Grafana is preconfigured with dashboards and Prometheus as the default data source:
- Name: Prometheus
- Type: Prometheus
- Url: http://prometheus:9090
- Access: proxy
Docker Host Dashboard
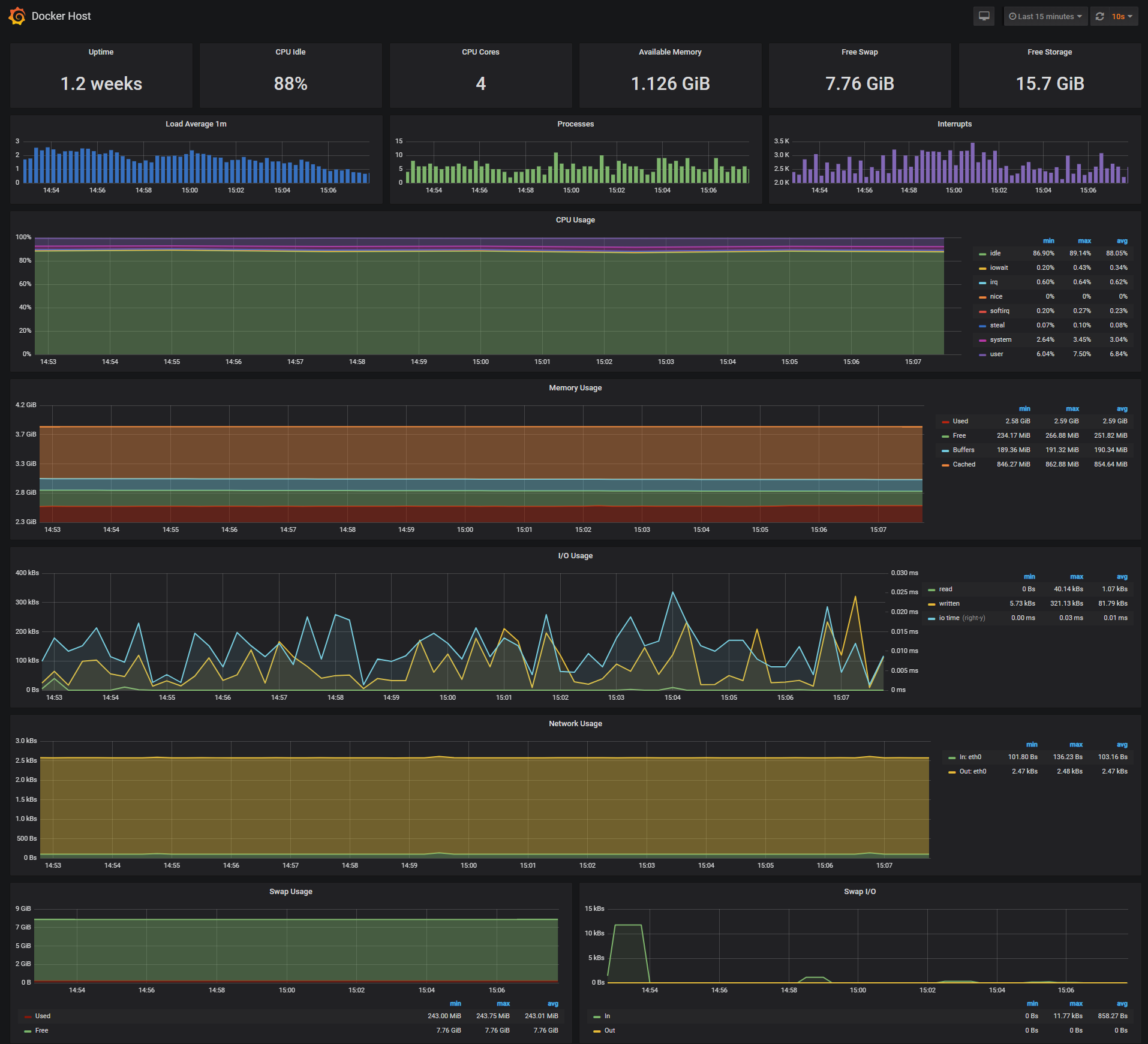
The Docker Host Dashboard shows key metrics for monitoring the resource usage of your server:
- Server uptime, CPU idle percent, number of CPU cores, available memory, swap and storage
- System load average graph, running and blocked by IO processes graph, interrupts graph
- CPU usage graph by mode (guest, idle, iowait, irq, nice, softirq, steal, system, user)
- Memory usage graph by distribution (used, free, buffers, cached)
- IO usage graph (read Bps, read Bps and IO time)
- Network usage graph by device (inbound Bps, Outbound Bps)
- Swap usage and activity graphs
For storage and particularly Free Storage graph, you have to specify the fstype in grafana graph request.
You can find it in grafana/provisioning/dashboards/docker_host.json, at line 480 :
"expr": "sum(node_filesystem_free_bytes{fstype=\"btrfs\"})",
I work on BTRFS, so i need to change aufs to btrfs.
You can find right value for your system in Prometheus http://<host-ip>:9090 launching this request :
node_filesystem_free_bytes
Docker Containers Dashboard
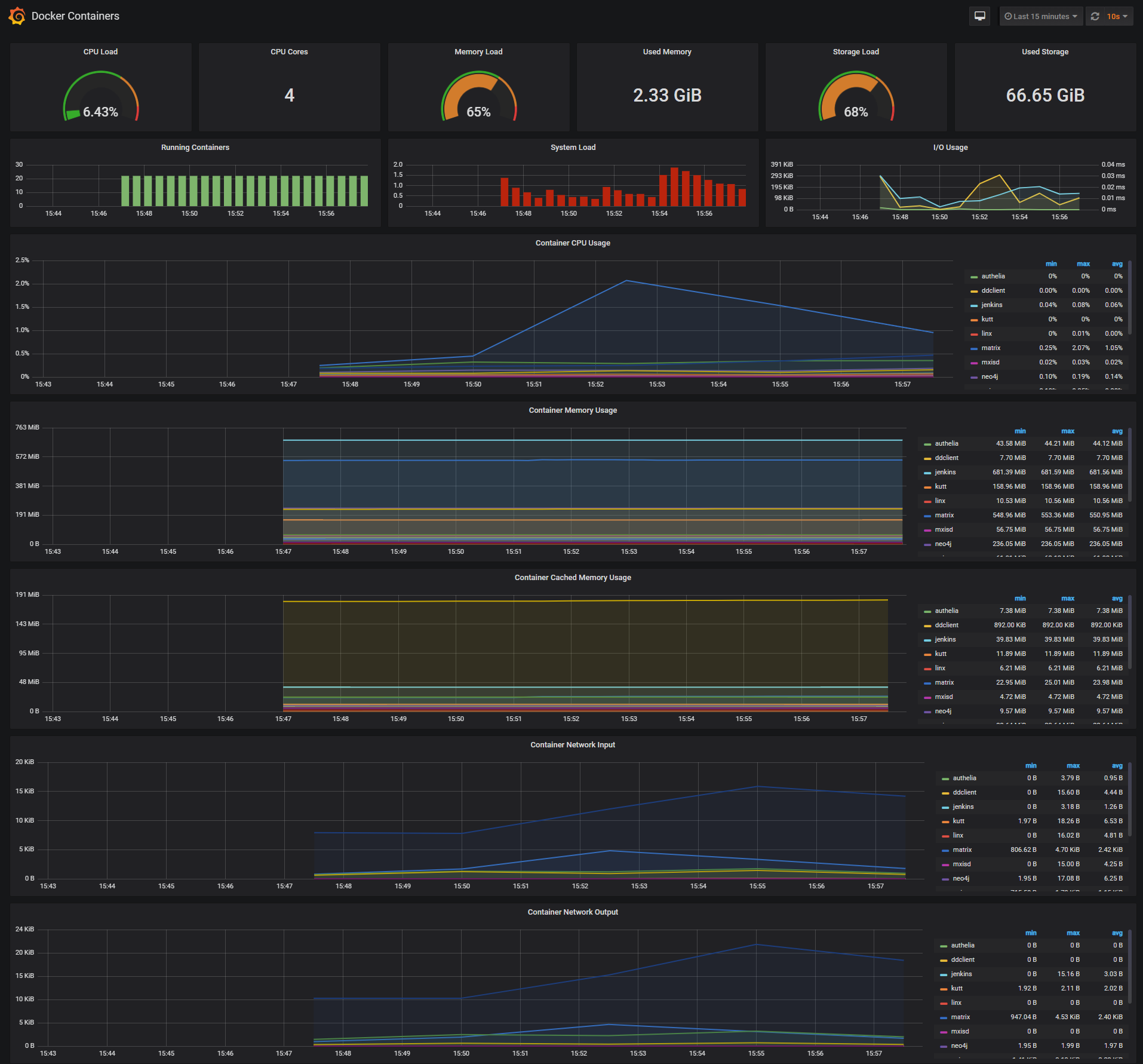
The Docker Containers Dashboard shows key metrics for monitoring running containers:
- Total containers CPU load, memory and storage usage
- Running containers graph, system load graph, IO usage graph
- Container CPU usage graph
- Container memory usage graph
- Container cached memory usage graph
- Container network inbound usage graph
- Container network outbound usage graph
Note that this dashboard doesn't show the containers that are part of the monitoring stack.
For storage and particularly Storage Load graph, you have to specify the fstype in grafana graph request.
You can find it in grafana/provisioning/dashboards/docker_containers.json, at line 406 :
"expr": "(node_filesystem_size_bytes{fstype=\"btrfs\"} - node_filesystem_free_bytes{fstype=\"btrfs\"}) / node_filesystem_size_bytes{fstype=\"btrfs\"} * 100",
I work on BTRFS, so i need to change aufs to btrfs.
You can find right value for your system in Prometheus http://<host-ip>:9090 launching this request :
node_filesystem_size_bytes node_filesystem_free_bytes
Monitor Services Dashboard
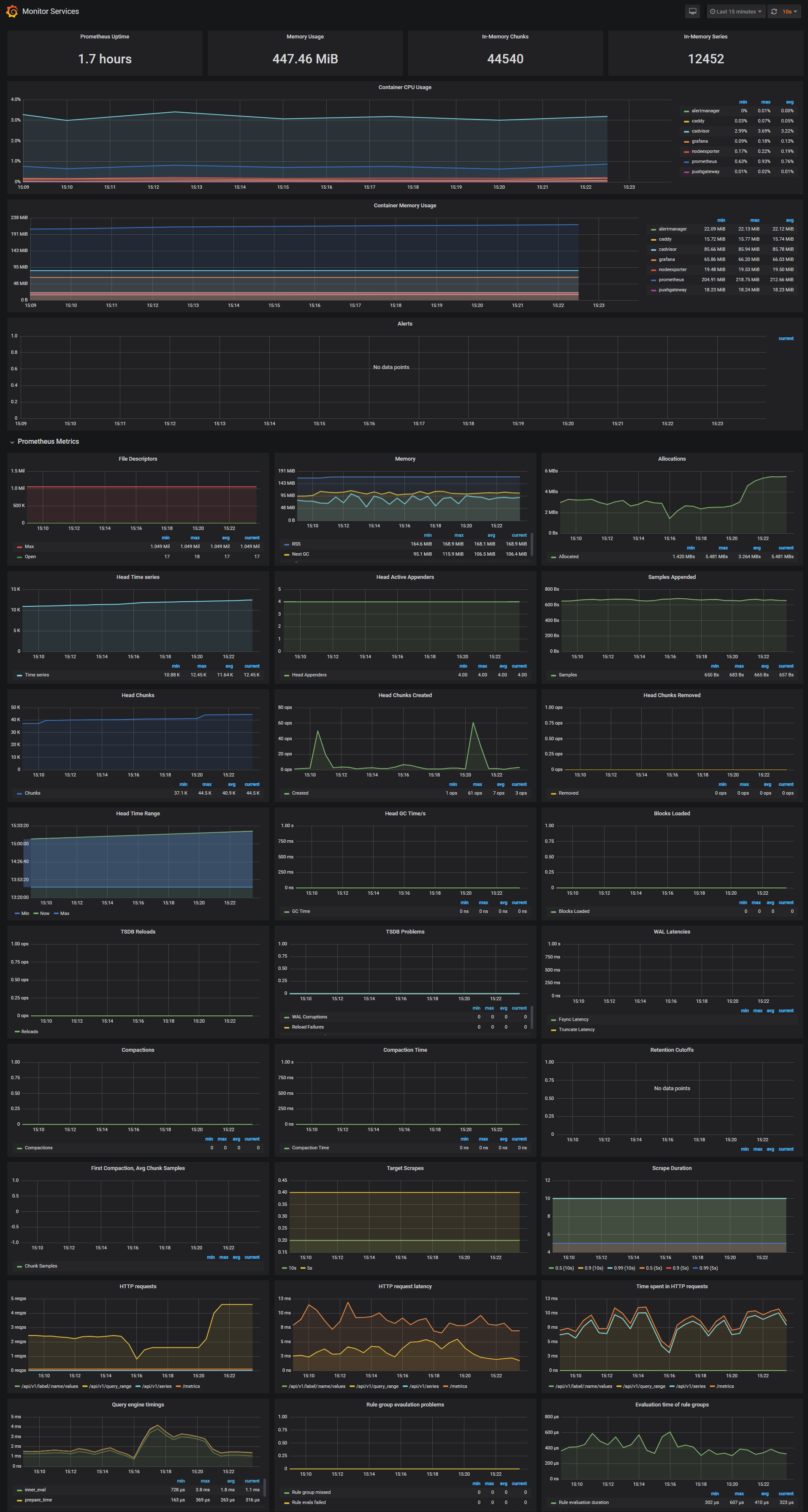
The Monitor Services Dashboard shows key metrics for monitoring the containers that make up the monitoring stack:
- Prometheus container uptime, monitoring stack total memory usage, Prometheus local storage memory chunks and series
- Container CPU usage graph
- Container memory usage graph
- Prometheus chunks to persist and persistence urgency graphs
- Prometheus chunks ops and checkpoint duration graphs
- Prometheus samples ingested rate, target scrapes and scrape duration graphs
- Prometheus HTTP requests graph
- Prometheus alerts graph
Define alerts
Three alert groups have been setup within the alert.rules configuration file:
- Monitoring services alerts targets
- Docker Host alerts host
- Docker Containers alerts containers
You can modify the alert rules and reload them by making a HTTP POST call to Prometheus:
curl -X POST http://admin:admin@<host-ip>:9090/-/reload
Monitoring services alerts
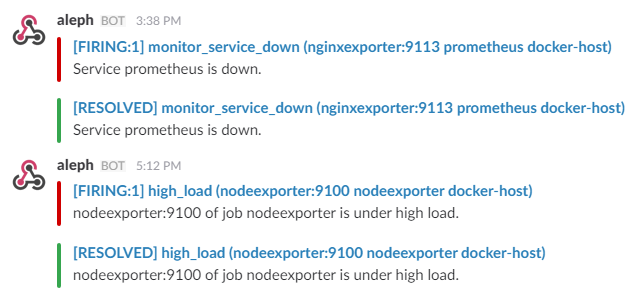
Trigger an alert if any of the monitoring targets (node-exporter and cAdvisor) are down for more than 30 seconds:
- alert: monitor_service_down expr: up == 0 for: 30s labels: severity: critical annotations: summary: "Monitor service non-operational" description: "Service {{ $labels.instance }} is down."
Docker Host alerts
Trigger an alert if the Docker host CPU is under high load for more than 30 seconds:
- alert: high_cpu_load expr: node_load1 > 1.5 for: 30s labels: severity: warning annotations: summary: "Server under high load" description: "Docker host is under high load, the avg load 1m is at {{ $value}}. Reported by instance {{ $labels.instance }} of job {{ $labels.job }}."
Modify the load threshold based on your CPU cores.
Trigger an alert if the Docker host memory is almost full:
- alert: high_memory_load expr: (sum(node_memory_MemTotal_bytes) - sum(node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes) ) / sum(node_memory_MemTotal_bytes) * 100 > 85 for: 30s labels: severity: warning annotations: summary: "Server memory is almost full" description: "Docker host memory usage is {{ humanize $value}}%. Reported by instance {{ $labels.instance }} of job {{ $labels.job }}."
Trigger an alert if the Docker host storage is almost full:
- alert: high_storage_load expr: (node_filesystem_size_bytes{fstype="aufs"} - node_filesystem_free_bytes{fstype="aufs"}) / node_filesystem_size_bytes{fstype="aufs"} * 100 > 85 for: 30s labels: severity: warning annotations: summary: "Server storage is almost full" description: "Docker host storage usage is {{ humanize $value}}%. Reported by instance {{ $labels.instance }} of job {{ $labels.job }}."
Docker Containers alerts
Trigger an alert if a container is down for more than 30 seconds:
- alert: jenkins_down expr: absent(container_memory_usage_bytes{name="jenkins"}) for: 30s labels: severity: critical annotations: summary: "Jenkins down" description: "Jenkins container is down for more than 30 seconds."
Trigger an alert if a container is using more than 10% of total CPU cores for more than 30 seconds:
- alert: jenkins_high_cpu expr: sum(rate(container_cpu_usage_seconds_total{name="jenkins"}[1m])) / count(node_cpu_seconds_total{mode="system"}) * 100 > 10 for: 30s labels: severity: warning annotations: summary: "Jenkins high CPU usage" description: "Jenkins CPU usage is {{ humanize $value}}%."
Trigger an alert if a container is using more than 1.2GB of RAM for more than 30 seconds:
- alert: jenkins_high_memory expr: sum(container_memory_usage_bytes{name="jenkins"}) > 1200000000 for: 30s labels: severity: warning annotations: summary: "Jenkins high memory usage" description: "Jenkins memory consumption is at {{ humanize $value}}."
Setup alerting
The AlertManager service is responsible for handling alerts sent by Prometheus server. AlertManager can send notifications via email, Pushover, Slack, HipChat or any other system that exposes a webhook interface. A complete list of integrations can be found here.
You can view and silence notifications by accessing http://<host-ip>:9093.
The notification receivers can be configured in alertmanager/config.yml file.
To receive alerts via Slack you need to make a custom integration by choose incoming web hooks in your Slack team app page. You can find more details on setting up Slack integration here.
Copy the Slack Webhook URL into the api_url field and specify a Slack channel.
route: receiver: 'slack' receivers: - name: 'slack' slack_configs: - send_resolved: true text: "{{ .CommonAnnotations.description }}" username: 'Prometheus' channel: '#<channel>' api_url: 'https://hooks.slack.com/services/<webhook-id>'
Sending metrics to the Pushgateway
The pushgateway is used to collect data from batch jobs or from services.
To push data, simply execute:
echo "some_metric 3.14" | curl --data-binary @- http://user:password@localhost:9091/metrics/job/some_job
Please replace the user:password part with your user and password set in the initial configuration (default: admin:admin).
Updating Grafana to v5.2.2
In Grafana versions >= 5.1 the id of the grafana user has been changed. Unfortunately this means that files created prior to 5.1 won’t have the correct permissions for later versions.
| Version | User | User ID |
|---|---|---|
| < 5.1 | grafana | 104 |
| >= 5.1 | grafana | 472 |
There are two possible solutions to this problem.
- Change ownership from 104 to 472
- Start the upgraded container as user 104
Specifying a user in docker-compose.yml
To change ownership of the files run your grafana container as root and modify the permissions.
First perform a docker-compose down then modify your docker-compose.yml to include the user: root option:
grafana: image: grafana/grafana:5.2.2 container_name: grafana volumes: - grafana_data:/var/lib/grafana - ./grafana/datasources:/etc/grafana/datasources - ./grafana/dashboards:/etc/grafana/dashboards - ./grafana/setup.sh:/setup.sh entrypoint: /setup.sh user: root environment: - GF_SECURITY_ADMIN_USER=${ADMIN_USER:-admin} - GF_SECURITY_ADMIN_PASSWORD=${ADMIN_PASSWORD:-admin} - GF_USERS_ALLOW_SIGN_UP=false restart: unless-stopped expose: - 3000 networks: - monitor-net labels: org.label-schema.group: "monitoring"
Perform a docker-compose up -d and then issue the following commands:
docker exec -it --user root grafana bash # in the container you just started: chown -R root:root /etc/grafana && \ chmod -R a+r /etc/grafana && \ chown -R grafana:grafana /var/lib/grafana && \ chown -R grafana:grafana /usr/share/grafana
To run the grafana container as user: 104 change your docker-compose.yml like such:
grafana: image: grafana/grafana:5.2.2 container_name: grafana volumes: - grafana_data:/var/lib/grafana - ./grafana/datasources:/etc/grafana/datasources - ./grafana/dashboards:/etc/grafana/dashboards - ./grafana/setup.sh:/setup.sh entrypoint: /setup.sh user: "104" environment: - GF_SECURITY_ADMIN_USER=${ADMIN_USER:-admin} - GF_SECURITY_ADMIN_PASSWORD=${ADMIN_PASSWORD:-admin} - GF_USERS_ALLOW_SIGN_UP=false restart: unless-stopped expose: - 3000 networks: - monitor-net labels: org.label-schema.group:
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号