



.. figure:: https://raw.githubusercontent.com/spotify/luigi/master/doc/luigi.png :alt: Luigi Logo :align: center
.. image:: https://img.shields.io/endpoint.svg?url=https%3A%2F%2Factions-badge.atrox.dev%2Fspotify%2Fluigi%2Fbadge&label=build&logo=none&%3Fref%3Dmaster&style=flat :target: https://actions-badge.atrox.dev/spotify/luigi/goto?ref=master
.. image:: https://img.shields.io/codecov/c/github/spotify/luigi/master.svg?style=flat :target: https://codecov.io/gh/spotify/luigi?branch=master
.. image:: https://img.shields.io/pypi/v/luigi.svg?style=flat :target: https://pypi.python.org/pypi/luigi
.. image:: https://img.shields.io/pypi/l/luigi.svg?style=flat :target: https://pypi.python.org/pypi/luigi
.. image:: https://readthedocs.org/projects/luigi/badge/?version=stable :target: https://luigi.readthedocs.io/en/stable/?badge=stable :alt: Documentation Status
Luigi is a Python (3.6, 3.7, 3.8, 3.9, 3.10, 3.11, 3.12 tested) package that helps you build complex pipelines of batch jobs. It handles dependency resolution, workflow management, visualization, handling failures, command line integration, and much more.
Getting Started
Run pip install luigi to install the latest stable version from PyPI <https://pypi.python.org/pypi/luigi>_. Documentation for the latest release <https://luigi.readthedocs.io/en/stable/>__ is hosted on readthedocs.
Run pip install luigi[toml] to install Luigi with TOML-based configs <https://luigi.readthedocs.io/en/stable/configuration.html>__ support.
For the bleeding edge code, pip install git+https://github.com/spotify/luigi.git. Bleeding edge documentation <https://luigi.readthedocs.io/en/latest/>__ is also available.
Background
The purpose of Luigi is to address all the plumbing typically associated
with long-running batch processes. You want to chain many tasks,
automate them, and failures will happen. These tasks can be anything,
but are typically long running things like
Hadoop <http://hadoop.apache.org/>_ jobs, dumping data to/from
databases, running machine learning algorithms, or anything else.
There are other software packages that focus on lower level aspects of
data processing, like Hive <http://hive.apache.org/>,
Pig <http://pig.apache.org/>, or
Cascading <http://www.cascading.org/>. Luigi is not a framework to
replace these. Instead it helps you stitch many tasks together, where
each task can be a Hive query <https://luigi.readthedocs.io/en/latest/api/luigi.contrib.hive.html>,
a Hadoop job in Java <https://luigi.readthedocs.io/en/latest/api/luigi.contrib.hadoop_jar.html>,
a Spark job in Scala or Python <https://luigi.readthedocs.io/en/latest/api/luigi.contrib.spark.html>,
a Python snippet,
dumping a table <https://luigi.readthedocs.io/en/latest/api/luigi.contrib.sqla.html>_
from a database, or anything else. It's easy to build up
long-running pipelines that comprise thousands of tasks and take days or
weeks to complete. Luigi takes care of a lot of the workflow management
so that you can focus on the tasks themselves and their dependencies.
You can build pretty much any task you want, but Luigi also comes with a
toolbox of several common task templates that you use. It includes
support for running
Python mapreduce jobs <https://luigi.readthedocs.io/en/latest/api/luigi.contrib.hadoop.html>_
in Hadoop, as well as
Hive <https://luigi.readthedocs.io/en/latest/api/luigi.contrib.hive.html>,
and Pig <https://luigi.readthedocs.io/en/latest/api/luigi.contrib.pig.html>,
jobs. It also comes with
file system abstractions for HDFS <https://luigi.readthedocs.io/en/latest/api/luigi.contrib.hdfs.html>_,
and local files that ensures all file system operations are atomic. This
is important because it means your data pipeline will not crash in a
state containing partial data.
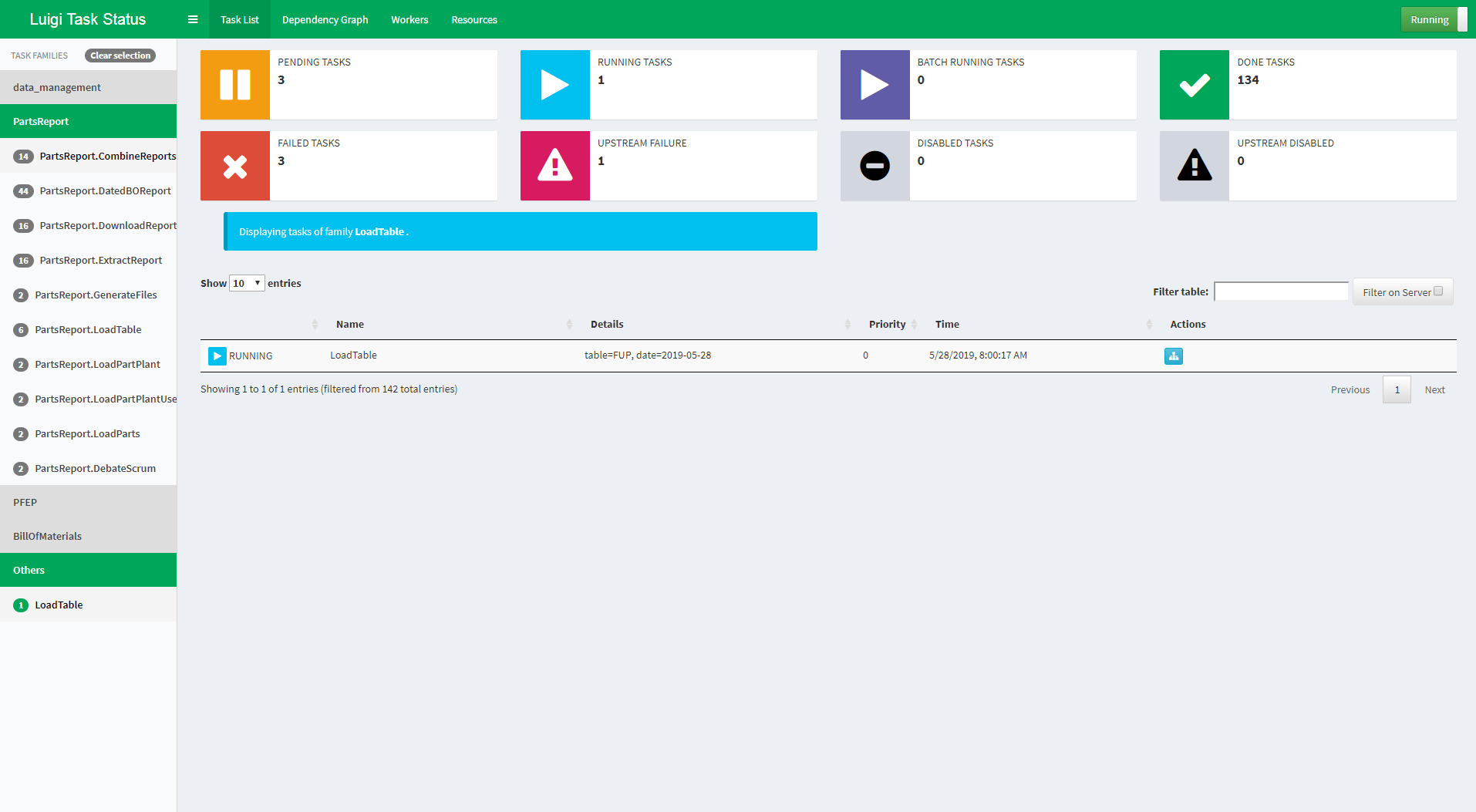
Visualiser page
The Luigi server comes with a web interface too, so you can search and filter among all your tasks.
.. figure:: https://raw.githubusercontent.com/spotify/luigi/master/doc/visualiser_front_page.png :alt: Visualiser page
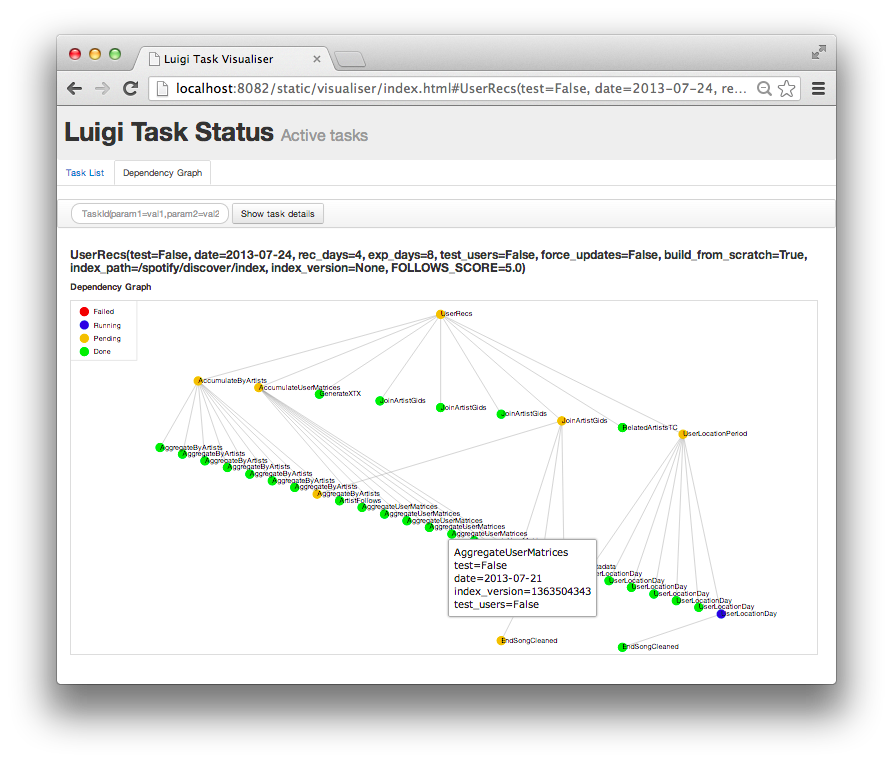
Dependency graph example
Just to give you an idea of what Luigi does, this is a screen shot from something we are running in production. Using Luigi's visualiser, we get a nice visual overview of the dependency graph of the workflow. Each node represents a task which has to be run. Green tasks are already completed whereas yellow tasks are yet to be run. Most of these tasks are Hadoop jobs, but there are also some things that run locally and build up data files.
.. figure:: https://raw.githubusercontent.com/spotify/luigi/master/doc/user_recs.png :alt: Dependency graph
Philosophy
Conceptually, Luigi is similar to GNU Make <http://www.gnu.org/software/make/>_ where you have certain tasks
and these tasks in turn may have dependencies on other tasks. There are
also some similarities to Oozie <http://oozie.apache.org/>_
and Azkaban <https://azkaban.github.io/>_. One major
difference is that Luigi is not just built specifically for Hadoop, and
it's easy to extend it with other kinds of tasks.
Everything in Luigi is in Python. Instead of XML configuration or
similar external data files, the dependency graph is specified within
Python. This makes it easy to build up complex dependency graphs of
tasks, where the dependencies can involve date algebra or recursive
references to other versions of the same task. However, the workflow can
trigger things not in Python, such as running
Pig scripts <https://luigi.readthedocs.io/en/latest/api/luigi.contrib.pig.html>_
or scp'ing files <https://luigi.readthedocs.io/en/latest/api/luigi.contrib.ssh.html>_.
Who uses Luigi?
We use Luigi internally at Spotify <https://www.spotify.com>_ to run
thousands of tasks every day, organized in complex dependency graphs.
Most of these tasks are Hadoop jobs. Luigi provides an infrastructure
that powers all kinds of stuff including recommendations, toplists, A/B
test analysis, external reports, internal dashboards, etc.
Since Luigi is open source and without any registration walls, the exact number of Luigi users is unknown. But based on the number of unique contributors, we expect hundreds of enterprises to use it. Some users have written blog posts or held presentations about Luigi:
Spotify <https://www.spotify.com>_(presentation, 2014) <http://www.slideshare.net/erikbern/luigi-presentation-nyc-data-science>__Foursquare <https://foursquare.com/>_(presentation, 2013) <http://www.slideshare.net/OpenAnayticsMeetup/luigi-presentation-17-23199897>__Mortar Data (Datadog) <https://www.datadoghq.com/>_(documentation / tutorial) <http://help.mortardata.com/technologies/luigi>__Stripe <https://stripe.com/>_(presentation, 2014) <http://www.slideshare.net/PyData/python-as-part-of-a-production-machine-learning-stack-by-michael-manapat-pydata-sv-2014>__Buffer <https://buffer.com/>_(blog, 2014) <https://overflow.bufferapp.com/2014/10/31/buffers-new-data-architecture/>__SeatGeek <https://seatgeek.com/>_(blog, 2015) <http://chairnerd.seatgeek.com/building-out-the-seatgeek-data-pipeline/>__Treasure Data <https://www.treasuredata.com/>_(blog, 2015) <http://blog.treasuredata.com/blog/2015/02/25/managing-the-data-pipeline-with-git-luigi/>__Growth Intelligence <http://growthintel.com/>_(presentation, 2015) <http://www.slideshare.net/growthintel/a-beginners-guide-to-building-data-pipelines-with-luigi>__AdRoll <https://www.adroll.com/>_(blog, 2015) <http://tech.adroll.com/blog/data/2015/09/22/data-pipelines-docker.html>__- 17zuoye
(presentation, 2015) <https://speakerdeck.com/mvj3/luiti-an-offline-task-management-framework>__ Custobar <https://www.custobar.com/>_(presentation, 2016) <http://www.slideshare.net/teemukurppa/managing-data-workflows-with-luigi>__Blendle <https://launch.blendle.com/>_(presentation) <http://www.anneschuth.nl/wp-content/uploads/sea-anneschuth-streamingblendle.pdf#page=126>__TrustYou <http://www.trustyou.com/>_(presentation, 2015) <https://speakerdeck.com/mfcabrera/pydata-berlin-2015-processing-hotel-reviews-with-python>__Groupon <https://www.groupon.com/>_ /OrderUp <https://orderup.com>_(alternative implementation) <https://github.com/groupon/luigi-warehouse>__Red Hat - Marketing Operations <https://www.redhat.com>_(blog, 2017) <https://github.com/rh-marketingops/rh-mo-scc-luigi>__GetNinjas <https://www.getninjas.com.br/>_(blog, 2017) <https://labs.getninjas.com.br/using-luigi-to-create-and-monitor-pipelines-of-batch-jobs-eb8b3cd2a574>__voyages-sncf.com <https://www.voyages-sncf.com/>_(presentation, 2017) <https://github.com/voyages-sncf-technologies/meetup-afpy-nantes-luigi>__Open Targets <https://www.opentargets.org/>_(blog, 2017) <https://blog.opentargets.org/using-containers-with-luigi>__Leipzig University Library <https://ub.uni-leipzig.de>_(presentation, 2016) <https://de.slideshare.net/MartinCzygan/build-your-own-discovery-index-of-scholary-eresources>__ /(project) <https://finc.info/de/datenquellen>__Synetiq <https://synetiq.net/>_(presentation, 2017) <https://www.youtube.com/watch?v=M4xUQXogSfo>__Glossier <https://www.glossier.com/>_(blog, 2018) <https://medium.com/glossier/how-to-build-a-data-warehouse-what-weve-learned-so-far-at-glossier-6ff1e1783e31>__Data Revenue <https://www.datarevenue.com/>_(blog, 2018) <https://www.datarevenue.com/en/blog/how-to-scale-your-machine-learning-pipeline>_Uppsala University <http://pharmb.io>_(tutorial) <http://uppnex.se/twiki/do/view/Courses/EinfraMPS2015/Luigi.html>_ /(presentation, 2015) <https://www.youtube.com/watch?v=f26PqSXZdWM>_ /(slides, 2015) <https://www.slideshare.net/SamuelLampa/building-workflows-with-spotifys-luigi>_ /(poster, 2015) <https://pharmb.io/poster/2015-sciluigi/>_ /(paper, 2016) <https://doi.org/10.1186/s13321-016-0179-6>_ /(project) <https://github.com/pharmbio/sciluigi>_GIPHY <https://giphy.com/>_(blog, 2019) <https://engineering.giphy.com/luigi-the-10x-plumber-containerizing-scaling-luigi-in-kubernetes/>__xtream <https://xtreamers.io/>__(blog, 2019) <https://towardsdatascience.com/lessons-from-a-real-machine-learning-project-part-1-from-jupyter-to-luigi-bdfd0b050ca5>__CIAN <https://cian.ru/>__(presentation, 2019) <https://www.highload.ru/moscow/2019/abstracts/6030>__
Some more companies are using Luigi but haven't had a chance yet to write about it:
Schibsted <http://www.schibsted.com/>_enbrite.ly <http://enbrite.ly/>_Dow Jones / The Wall Street Journal <http://wsj.com>_Hotels.com <https://hotels.com>_Newsela <https://newsela.com>_Squarespace <https://www.squarespace.com/>_OAO <https://adops.com/>_Grovo <https://grovo.com/>_Weebly <https://www.weebly.com/>_Deloitte <https://www.Deloitte.co.uk/>_Stacktome <https://stacktome.com/>_LINX+Neemu+Chaordic <https://www.chaordic.com.br/>_Foxberry <https://www.foxberry.com/>_Okko <https://okko.tv/>_ISVWorld <http://isvworld.com/>_Big Data <https://bigdata.com.br/>_Movio <https://movio.co.nz/>_Bonnier News <https://www.bonniernews.se/>_Starsky Robotics <https://www.starsky.io/>_BaseTIS <https://www.basetis.com/>_Hopper <https://www.hopper.com/>_VOYAGE GROUP/Zucks <https://zucks.co.jp/en/>_Textpert <https://www.textpert.ai/>_Tracktics <https://www.tracktics.com/>_Whizar <https://www.whizar.com/>_xtream <https://www.xtreamers.io/>__Skyscanner <https://www.skyscanner.net/>_Jodel <https://www.jodel.com/>_Mekar <https://mekar.id/en/>_M3 <https://corporate.m3.com/en/>_Assist Digital <https://www.assistdigital.com/>_Meltwater <https://www.meltwater.com/>_DevSamurai <https://www.devsamurai.com/>_Veridas <https://veridas.com/>_
We're more than happy to have your company added here. Just send a PR on GitHub.
External links
Mailing List <https://groups.google.com/d/forum/luigi-user/>_ for discussions and asking questions. (Google Groups)Releases <https://pypi.python.org/pypi/luigi>_ (PyPI)Source code <https://github.com/spotify/luigi>_ (GitHub)Hubot Integration <https://github.com/houzz/hubot-luigi>_ plugin for Slack, Hipchat, etc (GitHub)
Authors
Luigi was built at Spotify <https://www.spotify.com>, mainly by
Erik Bernhardsson <https://github.com/erikbern> and
Elias Freider <https://github.com/freider>.
Many other people <https://github.com/spotify/luigi/graphs/contributors>
have contributed since open sourcing in late 2012.
Arash Rouhani <https://github.com/tarrasch>_ was the chief maintainer from 2015 to 2019, and now
Spotify's Data Team maintains
编辑推荐精选


QoderWork
阿里Qoder团队推出的桌面端AI智能体
QoderWork 是阿里推出的本地优先桌面 AI 智能体,�适配 macOS14+/Windows10+,以自然语言交互实现文件管理、数据分析、AI 视觉生成、浏览器自动化等办公任务,自主拆解执行复杂工作流,数据本地运行零上传,技能市场可无限扩展,是高效的 Agentic 生产力办公助手。


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。


seedancetwo2.0
能听懂你表达的�视频模型
Seedance two是基于seedance2.0的中国大模型,支持图像、视频、音频、文本四种模态输入,表达方式更丰富,生成也更可控。


nano-banana纳米香蕉中文站
国内直接访问,限时3折
输入简单文字,生成想要的图片,纳米香蕉中文站基于 Google 模型的 AI 图片生成网站,支持文字生图、图生图。官网价格限时3折活动


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具
推荐工具精选





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号