
ohm
解析工具包简化语法分析和编译器开发
Ohm是一款解析工具包,包含库和领域特定语言。它可用于解析自定义文件格式,快速构建编程语言的解析器、解释器和编译器。Ohm基于解析表达文法(PEG),具有左递归规则支持、面向对象语法扩展和模块化语义操作等特点。配套的在线编辑器和可视化工具提供即时反馈,有助于提高开发效率。




Ohm · 


Ohm is a parsing toolkit consisting of a library and a domain-specific language. You can use it to parse custom file formats or quickly build parsers, interpreters, and compilers for programming languages.
The Ohm language is based on parsing expression grammars (PEGs), which are a formal way of describing syntax, similar to regular expressions and context-free grammars. The Ohm library provides a JavaScript interface for creating parsers, interpreters, and more from the grammars you write.
- Full support for left-recursive rules means that you can define left-associative operators in a natural way.
- Object-oriented grammar extension makes it easy to extend an existing language with new syntax.
- Modular semantic actions. Unlike many similar tools, Ohm completely separates grammars from semantic actions. This separation improves modularity and extensibility, and makes both grammars and semantic actions easier to read and understand.
- Online editor and visualizer. The Ohm Editor provides instant feedback and an interactive visualization that makes the entire execution of the parser visible and tangible. It'll make you feel like you have superpowers. 💪
Some awesome things people have built using Ohm:
- Seymour, a live programming environment for the classroom.
- Shadama, a particle simulation language designed for high-school science.
- turtle.audio, an audio environment where simple text commands generate lines that can play music.
- A browser-based tool that turns written Konnakkol (a South Indian vocal percussion art) into audio.
- Wildcard, a browser extension that empowers anyone to modify websites to meet their own specific needs, uses Ohm for its spreadsheet formulas.
Getting Started
The easiest way to get started with Ohm is to use the interactive editor. Alternatively, you can play with one of the following examples on JSFiddle:
Resources
- Tutorial: Ohm: Parsing Made Easy
- The math example is extensively commented and is a good way to dive deeper.
- Examples
- Documentation
- For community support and discussion, join us on Discord, GitHub Discussions, or the ohm-discuss mailing list.
- For updates, follow @_ohmjs on Twitter.
Installation
On a web page
To use Ohm in the browser, just add a single <script> tag to your page:
<!-- Development version of Ohm from unpkg.com --> <script src="https://unpkg.com/ohm-js@17/dist/ohm.js"></script>
or
<!-- Minified version, for faster page loads --> <script src="https://unpkg.com/ohm-js@17/dist/ohm.min.js"></script>
This creates a global variable named ohm.
Node.js
First, install the ohm-js package with your package manager:
Then, you can use require to use Ohm in a script:
const ohm = require('ohm-js');
Ohm can also be imported as an ES module:
import * as ohm from 'ohm-js';
Deno
To use Ohm from Deno:
import * as ohm from 'https://unpkg.com/ohm-js@17';
Basics
Defining Grammars
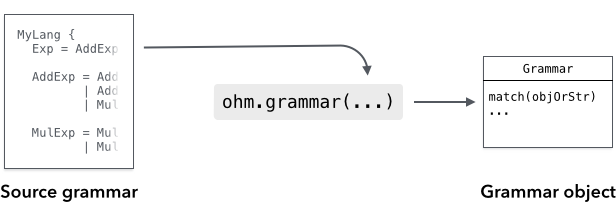
To use Ohm, you need a grammar that is written in the Ohm language. The grammar provides a formal definition of the language or data format that you want to parse. There are a few different ways you can define an Ohm grammar:
-
The simplest option is to define the grammar directly in a JavaScript string and instantiate it using
ohm.grammar(). In most cases, you should use a template literal with String.raw:const myGrammar = ohm.grammar(String.raw` MyGrammar { greeting = "Hello" | "Hola" } `); -
In Node.js, you can define the grammar in a separate file, and read the file's contents and instantiate it using
ohm.grammar(contents):In
myGrammar.ohm:MyGrammar { greeting = "Hello" | "Hola" }In JavaScript:
const fs = require('fs'); const ohm = require('ohm-js'); const contents = fs.readFileSync('myGrammar.ohm', 'utf-8'); const myGrammar = ohm.grammar(contents);
For more information, see Instantiating Grammars in the API reference.
Using Grammars
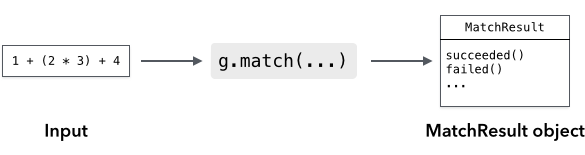
Once you've instantiated a grammar object, use the grammar's match() method to recognize input:
const userInput = 'Hello'; const m = myGrammar.match(userInput); if (m.succeeded()) { console.log('Greetings, human.'); } else { console.log("That's not a greeting!"); }
The result is a MatchResult object. You can use the succeeded() and failed() methods to see whether the input was recognized or not.
For more information, see the main documentation.
Debugging
Ohm has two tools to help you debug grammars: a text trace, and a graphical visualizer.
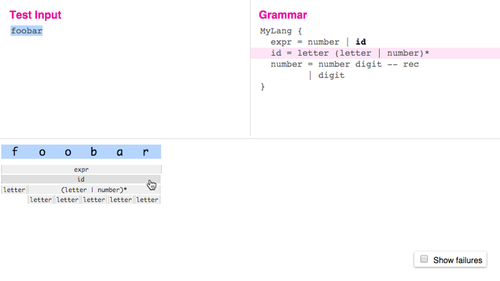
You can try the visualizer online.
To see the text trace for a grammar g, just use the g.trace()
method instead of g.match. It takes the same arguments, but instead of returning a MatchResult
object, it returns a Trace object — calling its toString method returns a string describing
all of the decisions the parser made when trying to match the input. For example, here is the
result of g.trace('ab').toString() for the grammar G { start = letter+ }:
ab ✓ start ⇒ "ab"
ab ✓ letter+ ⇒ "ab"
ab ✓ letter ⇒ "a"
ab ✓ lower ⇒ "a"
ab ✓ Unicode [Ll] character ⇒ "a"
b ✓ letter ⇒ "b"
b ✓ lower ⇒ "b"
b ✓ Unicode [Ll] character ⇒ "b"
✗ letter
✗ lower
✗ Unicode [Ll] character
✗ upper
✗ Unicode [Lu] character
✗ unicodeLtmo
✗ Unicode [Ltmo] character
✓ end ⇒ ""
Publishing Grammars
If you've written an Ohm grammar that you'd like to share with others, see our suggestions for publishing grammars.
Contributing to Ohm
Interested in contributing to Ohm? Please read CONTRIBUTING.md and the Ohm Contributor Guide.
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情��等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考��文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号