





Rapidgzip:支持快速随机访问的并行Gzip文件解压缩工具


<br>





这个仓库包含了命令行工具rapidgzip,它可以用于几乎任何gzip文件的并行解压缩。其他工具,如bgzip,只能并行解压缩由它们自己生成的gzip文件。rapidgzip适用于所有文件,特别是那些由通常安装的GNU gzip生成的文件。其工作原理可以在pugz论文或rapidgzip论文中阅读,后者是在前者的基础上进行的改进。
Python模块提供了一个RapidgzipFile类,可用于在不需要先解压缩的情况下在gzip文件内进行定位。
或者,你可以简单地将其用作并行化的gzip解码器,作为Python内置gzip模块的替代品,以充分利用所有的CPU核心。
随机定位支持与indexed_gzip提供的功能相同,但通过结合最近最少使用缓存和并行预取器,在以更高内存使用为代价的情况下实现了进一步的加速。
这个仓库是indexed_bzip2仓库的一个轻量级分支,主要开发工作在后者中进行。 这个仓库的创建是为了提高可见性,并将indexed_bzip2和rapidgzip的发布分开。 它将至少在每次发布时更新。 关于rapidgzip的问题应该在这里提出。
目录
安装
你可以直接从PyPI安装:
python3 -m pip install --upgrade pip # 推荐使用更新的manylinux wheels
python3 -m pip install rapidgzip
rapidgzip --help
可以通过以下方式测试最新的未发布开发版本:
python3 -m pip install --force-reinstall 'git+https://github.com/mxmlnkn/indexed_bzip2.git@master#egginfo=rapidgzip&subdirectory=python/rapidgzip'
要在本地构建,可以使用build并安装wheel文件:
</details>cd python/rapidgzip rm -rf dist python3 -m build . python3 -m pip install --force-reinstall --user dist/*.whl
性能
以下是显示使用核心数量与解压缩带宽关系的基准测试。
展示了两种rapidgzip变体:(index)和(no index)。
当使用--import-index提供索引时,Rapidgzip通常更快,因为它可以将解压缩任务委托给ISA-l或zlib,而在没有现成索引时,它必须使用自己编写的自定义gzip解压缩引擎。
此外,当存在索引时,解压缩可以更均匀、更有效地并行化,因为不需要序列化的窗口传播步骤。
小提琴图显示了20次重复测量作为一个单独的"斑点"。 细长的斑点表示时间测量非常可重复,而粗大的斑点则表示有很大的方差。
在2xAMD EPYC CPU 7702(2x64核心)上的扩展基准测试
Silesia语料库的解压缩
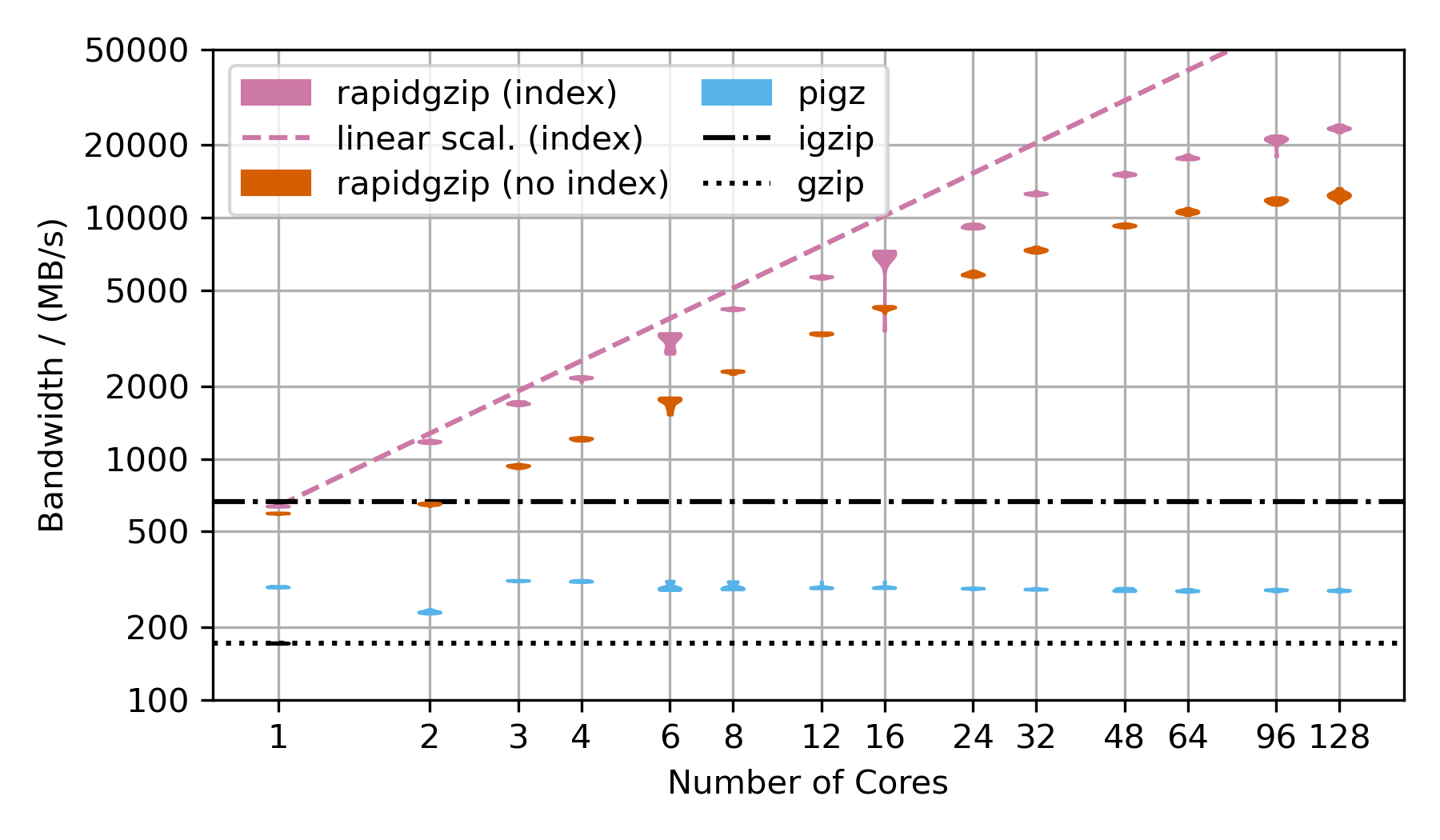
这个基准测试使用压缩为.tar.gz文件的Silesia语料库来展示解压缩性能。 然而,压缩后的数据集只有~69 MB,不足以显示在128个核心上的并行化效果。 因此,TAR文件被重复了与基准测试中核心数量相同的次数乘以2,然后压缩成一个单一的大型gzip文件,对于128个核心来说,压缩后约为18 GB,解压后为54 GB。
Rapidgzip在有索引的情况下可以达到24 GB/s,在没有索引的情况下可以达到12 GB/s。
由于Pugz无法处理Silesia数据集中包含的二进制数据,因此没有作为比较。
<details> <summary>更多基准测试</summary>Gzip压缩的Base64数据解压缩
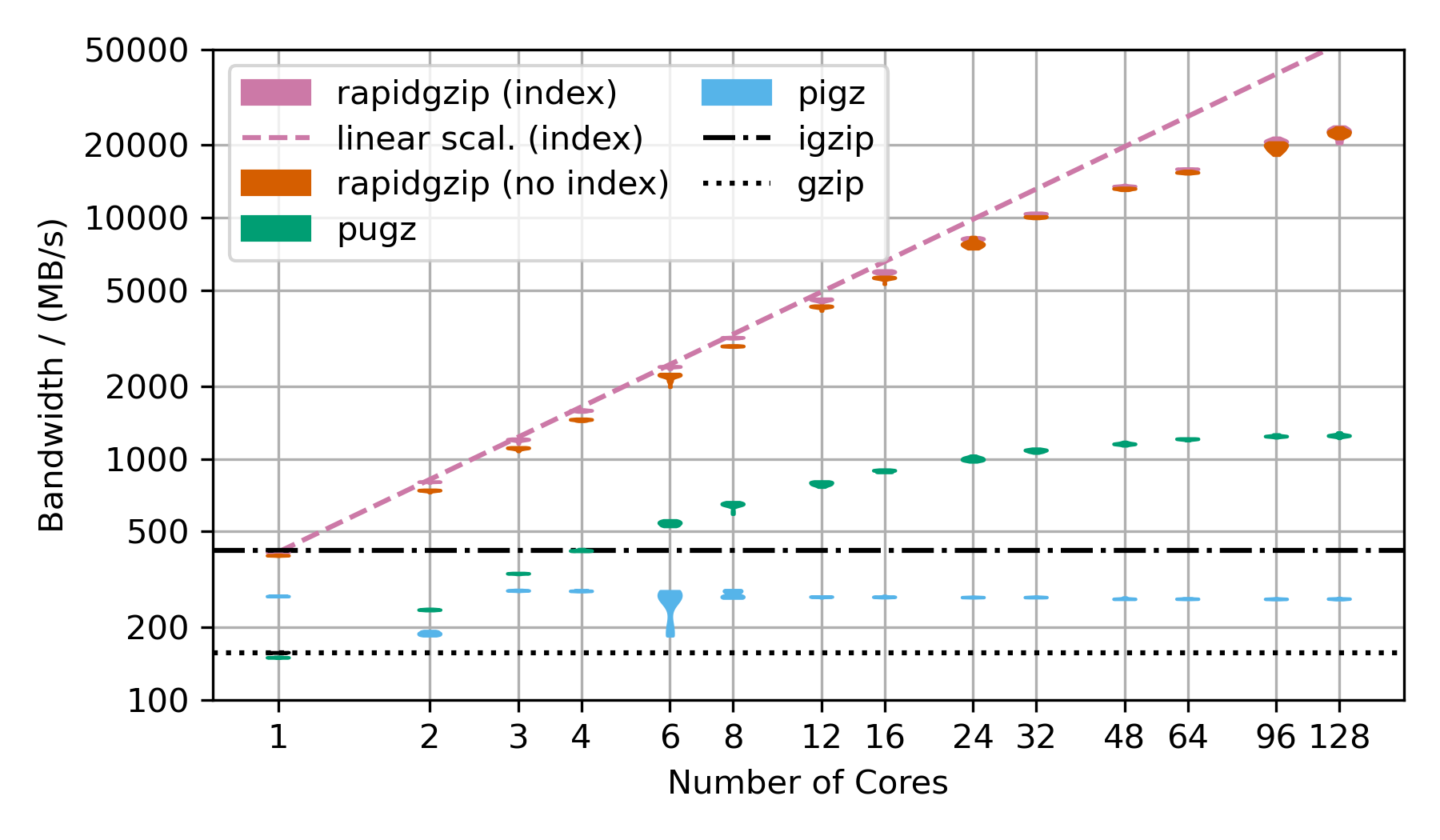 ��这个基准测试使用了经过base64编码然后用gzip压缩的随机数据。
对于rapidgzip来说,这是仅次于纯随机数据的最佳情况,纯随机数据无法压缩,因此可以通过简单的内存复制来解压缩。
这个次优情况主要产生了霍夫曼编码压缩的数据,只有很少的LZ77回溯引用。
没有LZ77回溯引用时,并行解压缩可以更独立地进行,因此比有大量LZ77回溯引用的情况下更快。
��这个基准测试使用了经过base64编码然后用gzip压缩的随机数据。
对于rapidgzip来说,这是仅次于纯随机数据的最佳情况,纯随机数据无法压缩,因此可以通过简单的内存复制来解压缩。
这个次优情况主要产生了霍夫曼编码压缩的数据,只有很少的LZ77回溯引用。
没有LZ77回溯引用时,并行解压缩可以更独立地进行,因此比有大量LZ77回溯引用的情况下更快。
Gzip压缩的FASTQ数据解压缩
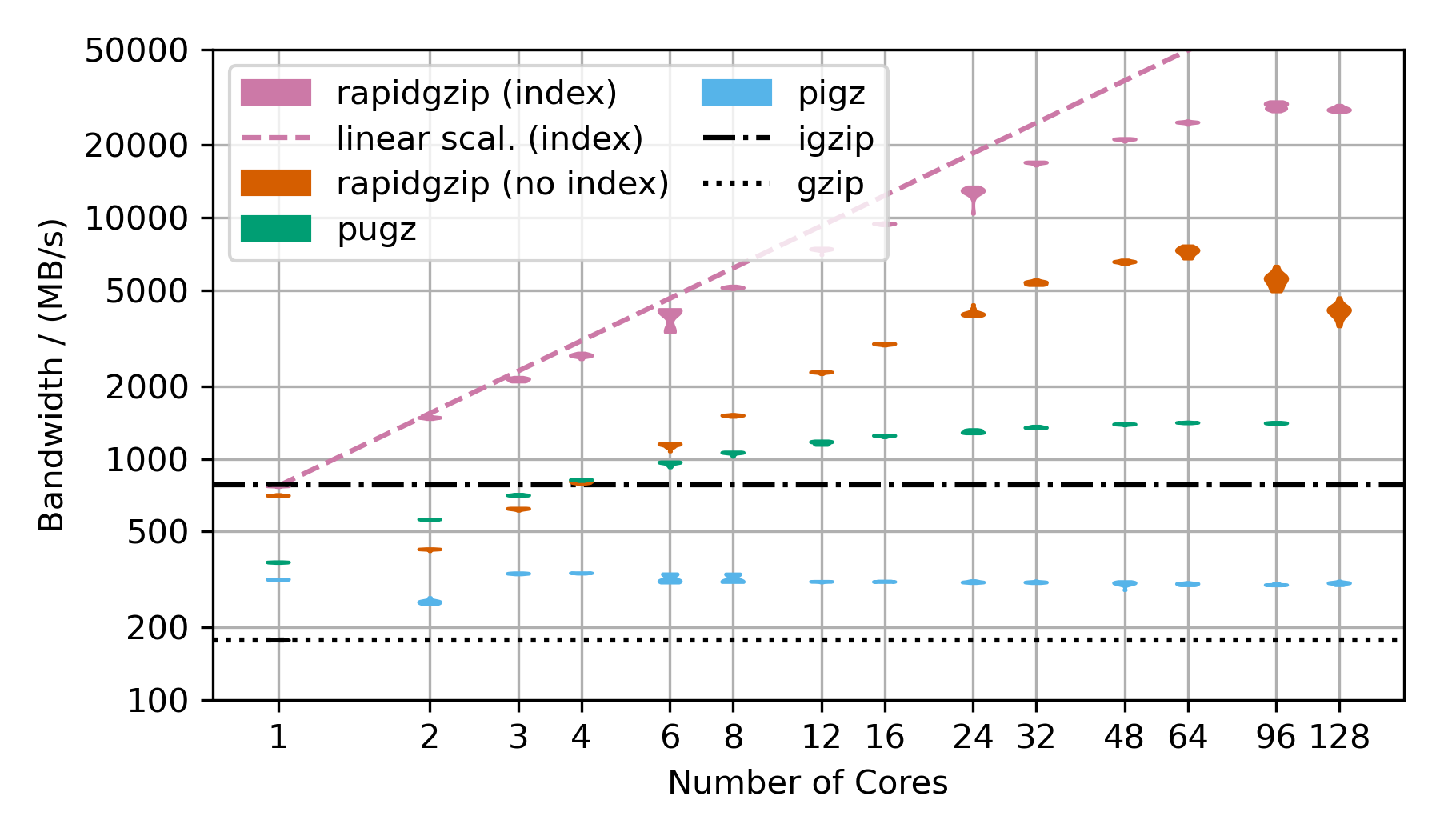
这个基准测试使用了gzip压缩的FASTQ数据。 这就是为什么TAR文件会重复与基准测试中核心数量相同的次数,以保持解压缩时间大致恒定,从而使在如此大范围内的基准测试成为可能。 这几乎是rapidgzip的最坏情况,因为它包含了许多跨越很长范围的LZ77回溯引用。 这意味着无法回退到ISA-L,并且意味着几乎所有数据都必须进行耗时的两阶段解码。 这也是为什么它在超过64个核心(即第二个CPU插槽)时无法扩展的原因。 第一和第二解压缩阶段完全独立地提交给线程池,在这种NUMA架构上意味着,如果一个块的第二步不是在与第一步相同的处理器上完成,数据就需要在两个处理器插槽之间进行昂贵的传输。 这应该可以通过让ThreadPool感知NUMA来修复。
这三个扩展性图表是用rapidgzip 0.9.0创建的,而论文中的图表是用0.5.0创建的。
Ryzen 3900X上的扩展性基准测试
这些在我的本地工作站上进行的基准测试使用了Ryzen 3900X,它只有12个核心(24个虚拟核心),但基础频率比2xAMD EPYC CPU 7702高得多。
使用现有索引的解压缩
| 4GiB-base64 | 4GiB-base64 | 20x-silesia | 20x-silesia | ||
|---|---|---|---|---|---|
| 未压缩大小 | 4 GiB | 3.95 GiB | |||
| 压缩大小 | 3.04 GiB | 1.27 GiB | |||
| 模块 | 带宽 <br/> / (MB/s) | 加速比 | 带宽 <br/> / (MB/s) | 加速比 | |
| gzip | 250 | 1 | 293 | 1 | |
| rapidgzip (0 线程) | 5179 | 20.6 | 5640 | 18.8 | |
| rapidgzip (1 线程) | 488 | 1.9 | 684 | 2.3 | |
| rapidgzip (2 线程) | 902 | 3.6 | 1200 | 4.0 | |
| rapidgzip (6 线程) | 2617 | 10.4 | 3250 | 10.9 | |
| rapidgzip (12 线程) | 4463 | 17.7 | 5600 | 18.7 | |
| rapidgzip (24 线程) | 5240 | 20.8 | 5750 | 19.2 | |
| rapidgzip (32 线程) | 4929 | 19.6 | 5300 | 17.7 |
从头开始解压缩
| 4GiB-base64 | 4GiB-base64 | 20x-silesia | 20x-silesia | ||
|---|---|---|---|---|---|
| 未压缩大小 | 4 GiB | 3.95 GiB | |||
| 压缩大小 | 3.04 GiB | 1.27 GiB | |||
| 模块 | 带宽 <br/> / (MB/s) | 加速比 | 带宽 <br/> / (MB/s) | 加速比 | |
| gzip | 250 | 1 | 293 | 1 | |
| rapidgzip (0 线程) | 5060 | 20.1 | 2070 | 6.9 | |
| rapidgzip (1 线程) | 487 | 1.9 | 630 | 2.1 | |
| rapidgzip (2 线程) | 839 | 3.3 | 694 | 2.3 | |
| rapidgzip (6 线程) | 2365 | 9.4 | 1740 | 5.8 | |
| rapidgzip (12 线程) | 4116 | 16.4 | 1900 | 6.4 | |
| rapidgzip (24 线程) | 4974 | 19.8 | 2040 | 6.8 | |
| rapidgzip (32 线程) | 4612 | 18.3 | 2580 | 8.6 |
不同压缩器的基准测试
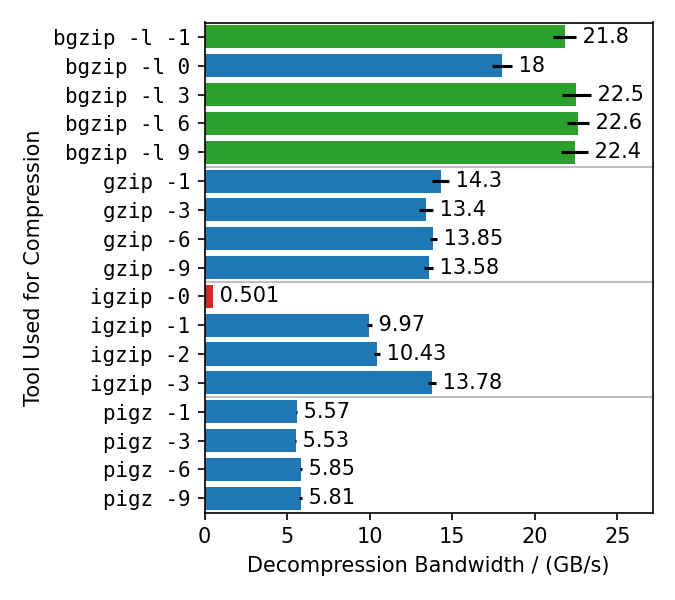
这个基准测试使用不同的gzip实现以不同的压缩级别压缩了放大的Silesia TAR。 然后使用rapidgzip在128个核心上解压缩生成的文件。
Rapidgzip几乎可以为所有测试的情况并行解压缩。
唯一的例外是用igzip -0压缩的文件,因为这些文件只包含一个几个GB大小的deflate块。
这是唯一已知会产生如此病态deflate块的工具。
其他压缩器的解压缩带宽差异很大。
最快的解压缩达到了22 GB/s,是针对bgzip压缩的文件,因为bgzip格式得到直接支持,这使rapidgzip能够避免两阶段解压缩方法,并且能够将所有工作卸载给ISA-L。
用bgzip -l 0压缩的文件解压缩速度稍慢,"仅"18 GB/s,因为它创建了一个完全未压缩的gzip流,因此比其他bgzip生成的文件更受I/O限制。
pigz生成的文件解压缩最慢,只有6 GB/s,而gzip和igzip为10-14 GB/s。
目前还不清楚原因。可能是因为pigz生成小的deflate块并添加了刷新标记。
这个图表中��的值高于论文中表3的值,因为测量是用rapidgzip 0.10.1而不是0.5.0版本进行的。
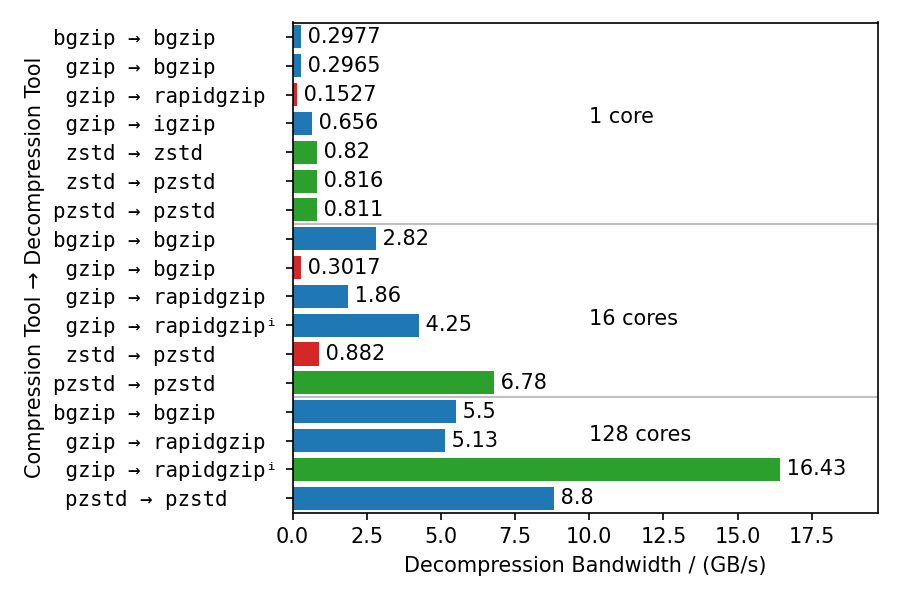
不同解压缩器的基准测试
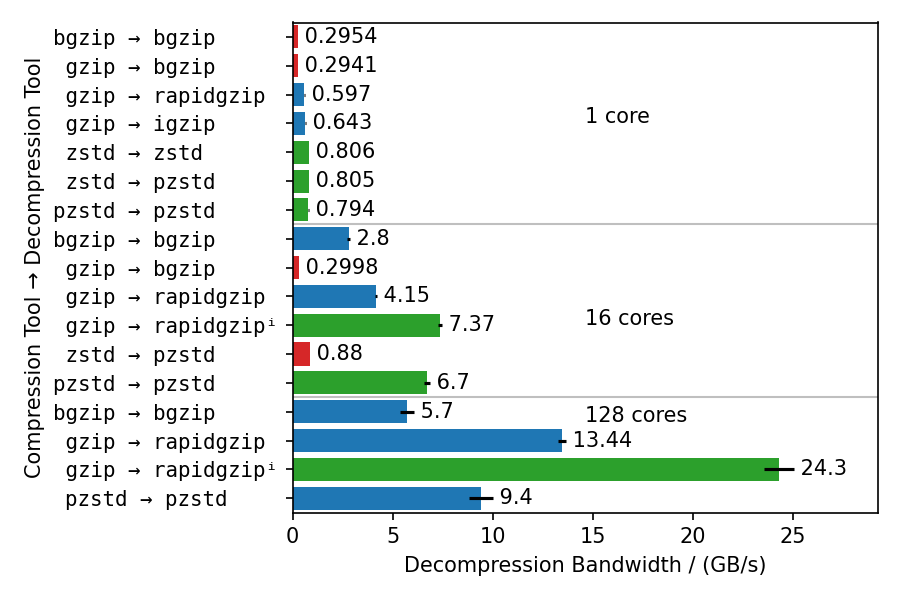
这个基准测试使用不同的压缩器和解压缩器来展示多个方面:
- Rapidgzip的单核解压缩速度接近
igzip,大约是使用zlib的bgzip的两倍。 - 使用ISA-L的解压缩带宽可以在某种程度上与zstd竞争,只慢25%。
bgzip和pzstd只能并行解压缩用bgzip/pzstd压缩的文件。 这特别意味着,用标准zstd工具压缩的文件无法并行解压缩,最高只能达到~800 MB/s。- 即使对于bgzip压缩的文件,rapidgzip在解压缩时也总是比
bgzip快,这要归功于ISA-L和更好的多线程。 - 对于多核解压缩,rapidgzip的扩展性比pzstd更高,当存在索引时,速度可以超过两倍:24.3 GB/s vs. 9.5 GB/s。 本图表中的数值高于论文中表4的数值,因为测量使用的是rapidgzip 0.10.1版本,而不是0.5.0版本。
使用方法
命令行工具
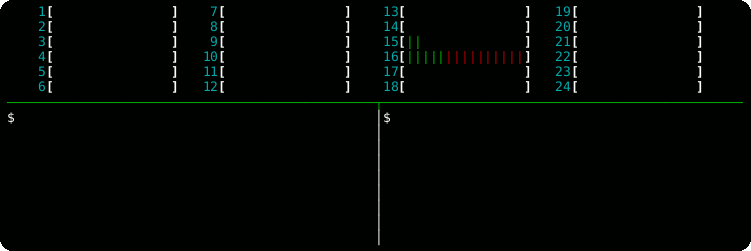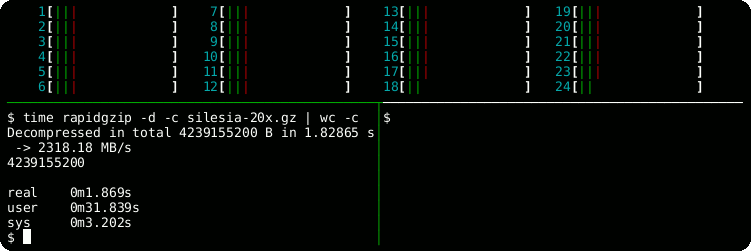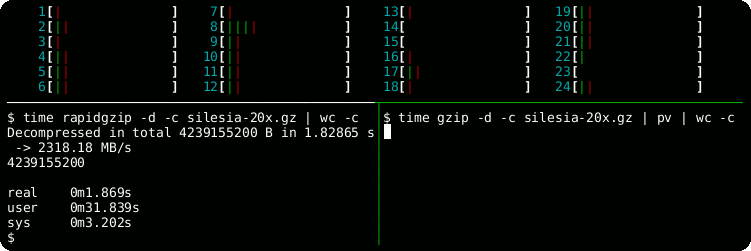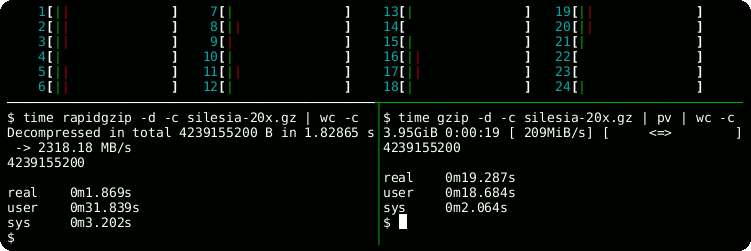
<details> <summary>帮助输出</summary>rapidgzip --help # 并行解码:1.7秒 time rapidgzip -d -c -P 0 sample.gz | wc -c # 串行解码:22秒 time gzip -d -c sample.gz | wc -c
一个基于ratarmount的rapidgzip后端的gzip解压缩工具
用法:
rapidgzip [选项...] 位置参数
操作选项:
-d, --decompress 强制解压。仅为兼容性。无论如何不支持压缩。
--import-index arg 使用现有的gzip索引。
--export-index arg 写出gzip索引文件。
--count 打印解压后的大小。
-l, --count-lines 打印解压数据中的换行符数量。
--analyze 打印有关内部文件格式结构的输出,如块类型。
高级选项:
--chunk-size arg 并行工作器解码的块大小,单位为KiB。(默认值:4096)
--verify 验证CRC32校验和。会减慢解压速度,但已有一些隐式和显式检查,如是否能到达文件末尾以及流大小是否正确。
--no-verify 不验证CRC32校验和。可能加快解压速度,但已有一些隐式和显式检查,如是否能到达文件末尾以及流大小是否正确。
--io-read-method arg 强制使用某种I/O方法进行读取的选项。默认情况下,在可能时使用pread。可选值:pread、sequential、locked-read (默认值:pread)
--index-format arg 选择输出索引格式的选项。可选值:gztool、gztool-with-lines、indexed_gzip。(默认值:indexed_gzip)
解压选项:
-c, --stdout 输出到标准输出。从标准输入读取时,这是默认设置。
-f, --force 强制覆盖现有输出文件。即使输出到/dev/null也强制解压。
-o, --output arg 输出文件。如果未指定,则使用去掉'.gz'的输入文件名或'<输入文件>.out'。如果从标准输入读取且未指定输出文件,则写入标准输出。
-k, --keep 保留(不删除)输入文件。仅为兼容性。本工具不会自动删除任何内容!
-P, --decoder-parallelism arg
使用并行解码器。如果给定可选的整数 >= 1,则为要使用的解码器线程数。请注意,可能会启动更多的非解码工作线程。如果给定0,则自动确定并行度。(默认值:0)
--ranges arg 仅解压指定的字节范围。
例如:10@0,1KiB@15KiB,5L@20L 解压前10个字节,偏移15 KiB处的1024字节,以及跳过前20行后的5行。
输出选项:
-h, --help 打印此帮助信息。
-q, --quiet 抑制非关键错误消息。
-v, --verbose 打印调试输出和性能统计信息。
-V, --version 显示软件版本。
--oss-attributions 显示开源软件许可证。
--oss-attributions-yaml 以YAML格式显示开源软件许可证,用于Conda。
如果未给出文件名,rapidgzip将从标准输入解压到标准输出。
如果通过管道将输出丢弃到/dev/null,则在未给出-l或-L或--force的情况下,可能会省略实际的解码步骤。
示例:
解压文件:
rapidgzip -d file.gz
并行解压文件:
rapidgzip -d -P 0 file.gz
列出所有gzip流和deflate块的信息:
rapidgzip --analyze file.gz
Python库
简单的打开、定位、读取和关闭
from rapidgzip import RapidgzipFile file = RapidgzipFile("example.gz", parallelization=os.cpu_count()) # 现在可以像普通文件一样使用它 file.seek(123) data = file.read(100) file.close()
第一次调用seek将确保块偏移列表是完整的,因此可能会首先创建它们。 由于这个原因,第一次调用seek可能需要一些时间。
使用上下文管理器
import os import rapidgzip with rapidgzip.open("example.gz", parallelization=os.cpu_count()) as file: file.seek(123) data = file.read(100)
存储和加载块偏移映射
创建gzip块列表可能需要一些时间,因为它必须完全解码gzip文件。 为了避免在打开gzip文件时进行这种设置,可以导出和导入块偏移列表。
为索引读取打开纯Python文件类对象
import io import os import rapidgzip as rapidgzip with open("example.gz", "rb") as file: in_memory_file = io.BytesIO(file.read()) with rapidgzip.open(in_memory_file, parallelization=os.cpu_count()) as file: file.seek(123) data = file.read(100)
通过Ratarmount
自0.14.0版本以来,rapidgzip是ratarmount的默认后端。
然后,您可以使用ratarmount轻松挂载单个gzip文件。
base64 /dev/urandom | head -c $(( 4 * 1024 * 1024 * 1024 )) | gzip > sample.gz # 串行解码:23秒 time gzip -c -d sample.gz | wc -c python3 -m pip install --user ratarmount ratarmount sample.gz mounted # 并行解码:3.5秒 time cat mounted/sample | wc -c # 随机定位到文件中间并读取1 MiB:0.287秒 time dd if=mounted/sample bs=$(( 1024 * 1024 )) \ iflag=skip_bytes,count_bytes skip=$(( 2 * 1024 * 1024 * 1024 )) count=$(( 1024 * 1024 )) | wc -c
C++库
由于它是用C++编写的,当然也可以作为C++库使用。
为了大量使用模板并简化与Python setuptools的编译,它主要是仅头文件的,因此将其集成到另一个项目中应该很容易。
许可证对大多数用例来说也足够宽松。
目前我还没有测试将其集成到其他项目中,除了简单地手动复制src/core、src/rapidgzip中的源代码,如果需要集成zlib,还有src/external/zlib。
如果您有建议和愿望,比如对CMake或Conan的支持,请开一个问题。
引用
描述实现细节并展示使用多达128个核心的扩展行为的论文已提交并被接受于ACM HPDC'23,第32届高性能并行和分布式计算国际研讨会。 该论文也可以在ACM DL或Arxiv上访问。 相关演示可以在这里找到。
如果您在科学出版物中使用此软件,请引用它:
@inproceedings{rapidgzip, author = {Knespel, Maximilian 和 Brunst, Holger}, title = {Rapidgzip: 使用缓存预取实现Gzip文件的并行解压缩和定位}, year = {2023}, isbn = {9798400701559}, publisher = {美国计算机协会}, address = {美国纽约}, url = {https://doi.org/10.1145/3588195.3592992}, doi = {10.1145/3588195.3592992}, abstract = {Gzip是一种被广泛使用的文件压缩格式。尽管存在多种gzip实现,但只有pugz能够充分利用当前的多核处理器架构进行解压缩。然而,pugz无法解压任意gzip文件。它要求解压后的数据流只包含9-126范围内的字节值。在本文中,我们提出了对pugz使用的并行化方案的一般化,可以可靠地应用于任意gzip压缩数据,而不会影响性能。我们证明,通过实现基于缓存和并行预取器的架构,可以去除pugz对文件内容的要求。这种架构可以安全地处理可能出现的错误解压结果,这些错误可能发生在线程通过试错法从gzip文件中间开始解压时。使用128个核心,我们的实现在解压gzip压缩的base64编码数据时达到了8.7 GB/s的解压带宽,相比单线程GNU gzip提速55倍,对于Silesia语料库达到了5.6 GB/s,相比GNU gzip提速33倍。}, booktitle = {第32届高性能并行和分布式计算国际研讨会论文集}, pages = {295–307}, numpages = {13}, keywords = {gzip, 解压缩, 并行算法, 性能, 随机访问}, location = {美国佛罗里达州奥兰多}, series = {HPDC '23}, }
关于
这个工具最初是作为ratarmount的后端开发的。在为ratarmount编写bzip2后端后,我对重新实现现有文件格式的自定义解码器的犹豫大大减少了。虽然使用indexed_gzip可以对gzip文件进行随机访问,但它不支持并行解压缩,无论是在创建索引还是索引已存在的情况下。后者在忽略负载均衡问题时是很简单的,但是要并行化索引创建过程要复杂得多,因为解压数据需要知道之前32 KiB的解压数据。
在通过改进pugz使用的算法实现了一个可用于生产的版本后,我提交了一篇论文。审稿过程是双盲的,我不确定是否应该对Pragzip进行假名化,因为它已经上传到了Github。最后,我在审稿过程中使用了"rapidgzip",因为我不确定应该在哪些表单字段中填写假名化的标题,所以我就一直使用了它。选择Rapidgzip的原因与pragzip类似,即P和RA是Parallel和Random Access的首字母缩写。由于rapgzip不够朗朗上口,我使用了rapidgzip,现在它的名字中也包含了最重要的设计目标:比单线程实现快得多。此外,额外的ID可以解释为Index和Decompression的缩写,使"rapid"成为一个部分反向缩写。
内部架构
用于并行化的内部架构的主要部分与indexed_bzip2使用的相同。
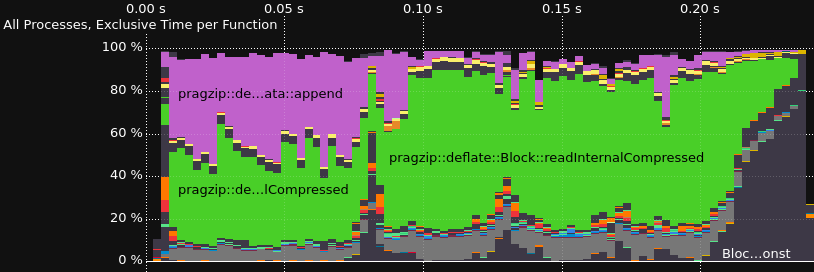
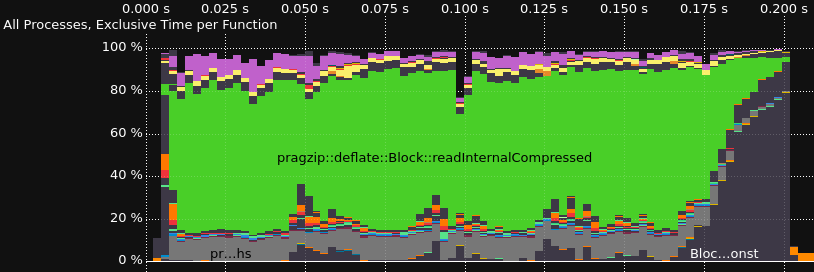
跟踪解码器
性能分析和跟踪使用Score-P进行插桩,使用Vampir进行可视化。这是在Ubuntu 22.04上安装大部分功能的Score-P的一种方法。
依赖项安装
<details> <summary>Score-P的安装步骤</summary></details>sudo apt-get install libopenmpi-dev openmpi-bin gcc-11-plugin-dev llvm-dev libclang-dev libunwind-dev \ libopen-trace-format-dev otf-trace libpapi-dev # 安装Score-P(到/opt/scorep) SCOREP_VERSION=8.0 wget "https://perftools.pages.jsc.fz-juelich.de/cicd/scorep/tags/scorep-${SCOREP_VERSION}/scorep-${SCOREP_VERSION}.tar.gz" tar -xf "scorep-${SCOREP_VERSION}.tar.gz" cd "scorep-${SCOREP_VERSION}" ./configure --with-mpi=openmpi --enable-shared --without-llvm --without-shmem --without-cubelib --prefix="/opt/scorep-${SCOREP_VERSION}" make -j $( nproc ) make install # 在shell启动时将/opt/scorep添加到你的路径变量中 cat <<EOF >> ~/.bashrc if test -d /opt/scorep; then export SCOREP_ROOT=/opt/scorep export PATH=$SCOREP_ROOT/bin:$PATH export LD_LIBRARY_PATH=$SCOREP_ROOT/lib:$LD_LIBRARY_PATH fi EOF echo -1 | sudo tee /proc/sys/kernel/perf_event_paranoid # 检查是否正常工作 scorep --version scorep-info config-summary
跟踪
2023-02-04版本的结果
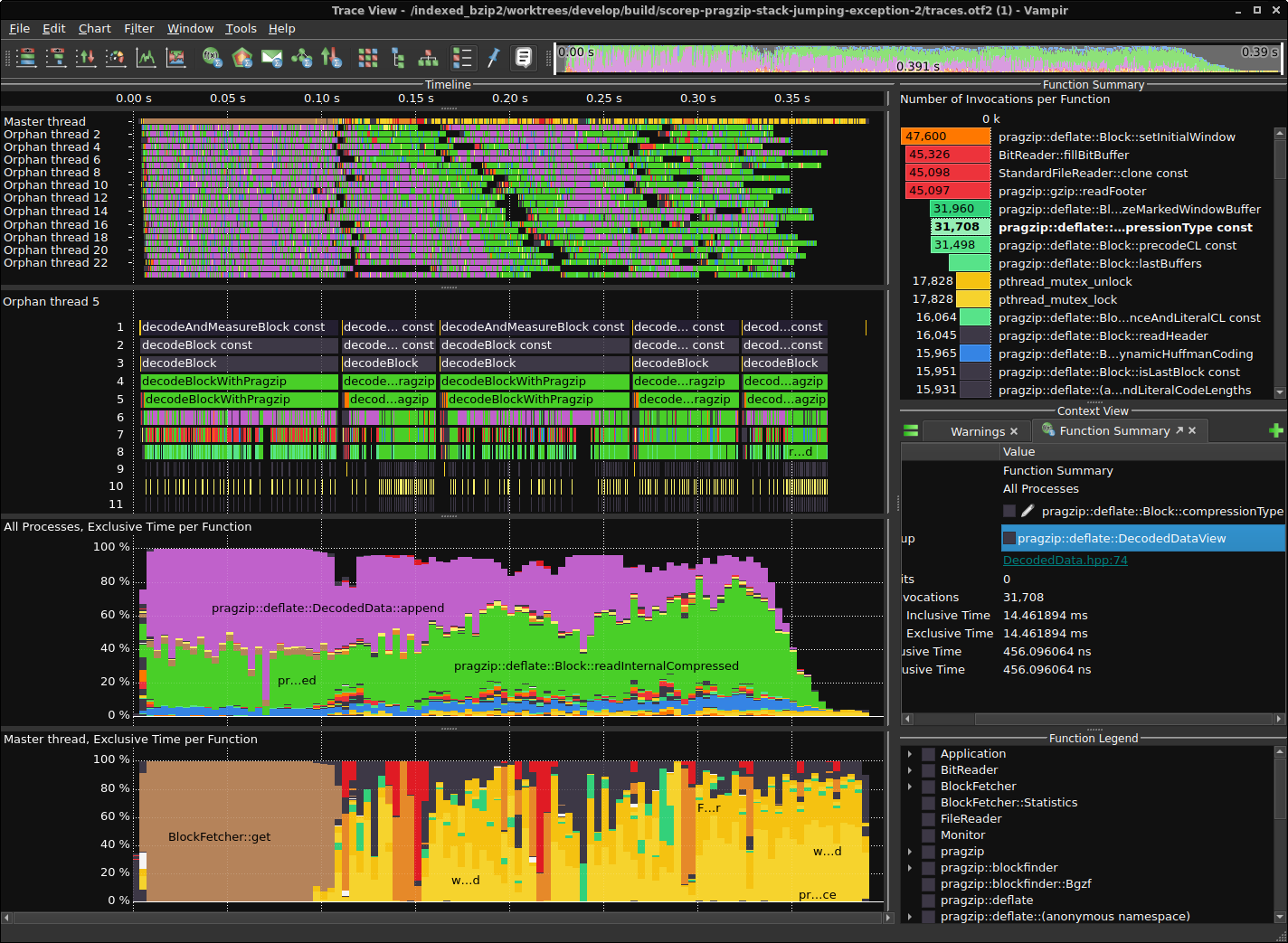
未预加载和预加载rpmalloc的比较
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,�内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




{kind=link}
AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号