




视觉编程的新方式!
我们正在开发一种新的视觉编程方式。我们开发了一款名为 MLJAR Studio 的桌面应用程序。 这是一个基于笔记本的开发环境,具有交互式代码模板和托管的 Python 环境。所有操作都在您的本地机器上运行。我们期待您的反馈。
<p align="center"> <img alt="mljar AutoML" src="https://raw.githubusercontent.com/pplonski/pplonski/main/media/piece-of-code.png" width="88%" /> </p>MLJAR 面向人类的自动机器学习






文档:<a href="https://supervised.mljar.com/" target="_blank">https://supervised.mljar.com/</a>
源代码:<a href="https://github.com/mljar/mljar-supervised" target="_blank">https://github.com/mljar/mljar-supervised</a>
寻求商业支持:请通过电子邮件与我们联系获取详情
<p align="center"> <img src="https://yellow-cdn.veclightyear.com/ab5030c0/0542ffb2-6658-4b3c-829f-bec55b65d8c8.png" width="100%" /> </p>目录
自动机器学习
mljar-supervised 是一个适用于表格数据的自动机器学习 Python 包。它旨在为数据科学家节省时间。它抽象了数据预处理、构建机器学习模型和执行超参数调优以找到最佳模型 :trophy: 的常用方法。它并非黑盒,因为您可以准确地看到 ML 流程是如何构建的(每个 ML 模型都有详细的 Markdown 报告)。
mljar-supervised 将帮助您:
- 解释和理解您的数据(自动探索性数据分析),
- 尝试许多不同的机器学习模型(算法选择和超参数调优),
- 从分析中创建包含所有模型详细信息的 Markdown 报告(自动文档),
- 保存、重新运行和加载分析和 ML 模型。
它内置了四种工作模式:
Explain模式,非常适合解释和理解数据,包含许多数据解释,如决策树可视化、线性模型系数展示、排列重要性和 SHAP 数据解释,Perform模式用于构建可在生产环境中使用的 ML 流程,Compete模式训练高度调优的 ML 模型,包括集成和堆叠,目的是用于 ML 竞赛。Optuna模式可用于搜索高度调优的 ML 模型,应在性能最重要且计算时间不受限制时使用(自版本0.10.0起可用)
当然,您可以进一步自定义每种 模式 的细节以满足需求。
它有什么优点?
- 它使用多种算法:基线、线性回归、随机森林、极端树、LightGBM、Xgboost、CatBoost、神经网络和最近�邻。
- 它可以基于 Caruana 论文中的贪心算法计算集成模型。
- 它可以堆叠模型构建二级集成(在"竞赛"模式下可用或设置 stack_models 参数后可用)。
- 它可以进行特征预处理,如缺失值填充和类别转换。更重要的是,它还可以处理目标值预处理。
- 它可以进行高级特征工程,如黄金特征、特征选择、文本和时间转换。
- 它可以使用"非完全随机搜索"算法(在预定义值集上进行随机搜索)和爬山法来微调最终模型的超参数。
- 它可以为你的数据计算基线,让你知道是否需要机器学习!
- 它有详尽的解释。该包训练简单的决策树(最大深度<=5),因此你可以轻松地用神奇的 dtreeviz 可视化它们,以更好地理解你的数据。
- mljar-supervised 使用简单的线性回归,并在摘要报告中包含其系数,因此你可以检查哪些特征在线性模型中最常用。
- 它关注模型的可解释性:对每种算法,都基于置换计算特征重要性。此外,对每种算法都计算 SHAP 解释:特征重要性、依赖图和决策图(可通过 explain_level 参数关闭解释)。
- AutoML 的每次 ML 实验运行都会自动生成文档。mljar-supervised 创建包含 ML 详细信息、指标和图表的 AutoML 训练 markdown 报告。
带用户界面的 AutoML Web 应用
我们创建了一个带 GUI 的 Web 应用,因此你不需要编写任何代码。只需上传你的数据。请在 github.com/mljar/automl-app 查看 Web 应用。你可以在本地计算机上运行此 Web 应用,因此你的数据是安全的。
<kbd> <img src="https://yellow-cdn.veclightyear.com/ab5030c0/dc60e5b7-0de3-40fc-b5a0-76c9bf08d388.gif" alt="Web 应用中的 AutoML 训练"></img> </kbd>自动文档
AutoML 报告
运行 AutoML 的报告将包含一个表格,其中包含每个模型得分和训练模型所需时间的信息。每个模型都有一个链接,你可以点击查看模型的详细信息。所有 ML 模型的性能都以散点图和箱线图的形式呈现,因此你可以直观地检查哪些算法表现最佳。

决策树报告
决策树摘要的示例,包括树的可视化。对于分类任务,还提供以下额外指标:
- 混淆矩阵
- 阈值(在二分类任务中进行优化)
- F1 分数
- 准确率
- 精确率、召回率、MCC

LightGBM 报告
LightGBM 摘要的示例:

可用模式
在文档中你可以找到表格中列出的 AutoML 模式的详细信息。
<p align="center"> <img src="https://yellow-cdn.veclightyear.com/ab5030c0/2b60bffc-1a6e-452d-a91c-afc8227356d1.png" width="100%" /> </p>解释模式
automl = AutoML(mode="Explain")
当用户想解释和理解数据时,应使用此模式。
- 使用 75%/25% 的训练/测试划分。
- 使用:基线、线性回归、决策树、随机森林、Xgboost、神经网络算法和集成。
- 提供完整解释:学习曲线、重要性图和 SHAP 图。
执行模式
automl = AutoML(mode="Perform")
当用户想训练一个将在实际用例中使用的模型时,应使用此模式。
- 使用 5 折交叉验证。
- 使用:线性回归、随机森林、LightGBM、Xgboost、CatBoost 和神经网络。使用集成。
- 报告中包含学习曲线和重要性图。
竞赛模式
automl = AutoML(mode="Compete")
应在机器学习竞赛中使用此模式。
- 根据数据集大小和 total_time_limit 调整验证策略。可以是:训练/测试划分(80/20)、5 折交叉验证或 10 折交叉验证。
- 使用:线性回归、决策树、随机森林、极端树、LightGBM、Xgboost、CatBoost、神经网络和最近邻。使用集成和堆叠。
- 报告中仅包含学习曲线。
Optuna 模式
automl = AutoML(mode="Optuna", optuna_time_budget=3600)
当性能最重要且时间不受限制时,应使用此模式。
- 使用 10 折交叉验证
- 使用:随机森林、极端树、LightGBM、Xgboost 和 CatBoost。这些算法由 Optuna 框架调优 optuna_time_budget 秒。算法使用原始数据进行调优,不进行高级特征工程。
- 使用高级特征工程、堆叠和集成。原始数据找到的超参数在这些步骤中重复使用。
- 报告中生成学习曲线。
如何保存和加载 AutoML?
AutoML 中的所有模型都会自动保存和加载。无需调用 save() 或 load()。
示例:
训练 AutoML
automl = AutoML(results_path="AutoML_classifier") automl.fit(X, y)
所有模型将保存在AutoML_classifier目录中。每个模型都有一个单独的目录,其中包含带有所有训练详细信息的README.md文件。
计算预测结果
automl = AutoML(results_path="AutoML_classifier") automl.predict(X)
AutoML会自动从results_path目录加载模型。如果在已经训练过的AutoML上再次调用fit(),你会收到一条警告消息,提示AutoML已经拟合。
为什么自动保存所有模型?
自动保存所有模型是为了能够在中断后恢复训练。例如,你正在训练AutoML 48小时,在47小时后发生了一些意外中断。在MLJAR AutoML中,你只需在中断后调用相同的训练代码,AutoML就会重新加载已训练的模型并完成训练。
支持的评估指标(AutoML()中的eval_metric参数)
- 二分类:
logloss、auc、f1、average_precision、accuracy- 默认为logloss - 多分类:
logloss、f1、accuracy- 默认为logloss - 回归:
rmse、mse、mae、r2、mape、spearman、pearson- 默认为rmse
如果你没有找到所需的eval_metric,请提出新的问题。我们会添加它。
公平性感知训练
从版本1.0.0开始,AutoML可以使用敏感特征优化机器学习流程。AutoML构造函数中有以下与公平性相关的参数:
fairness_metric- 用于决定模型是否公平的指标fairness_threshold- 用于判断模型公平性的阈值privileged_groups- 用于计算公平性指标的特权群体underprivileged_groups- 用于计算公平性指标的非特权群体
fit()方法接受sensitive_features参数。当向AutoML传递敏感特征时,最佳模型将仅从公平模型中选择。在AutoML�报告中,将添加有关公平性指标的附加信息。MLJAR AutoML支持两种偏见缓解方法:
- 样本加权 - 为样本分配权重以平等对待样本
- 智能网格搜索 - 类似于样本加权,检查不同的权重以优化公平性指标
公平机器学习构建可以与所有算法一起使用,包括Ensemble和Stacked Ensemble。我们支持三种机器学习任务:
- 二分类
- 多分类
- 回归
示例代码:
from sklearn.model_selection import train_test_split from sklearn.datasets import fetch_openml from supervised.automl import AutoML data = fetch_openml(data_id=1590, as_frame=True) X = data.data y = (data.target == ">50K") * 1 sensitive_features = X[["sex"]] X_train, X_test, y_train, y_test, S_train, S_test = train_test_split( X, y, sensitive_features, stratify=y, test_size=0.75, random_state=42 ) automl = AutoML( algorithms=[ "Xgboost" ], train_ensemble=False, fairness_metric="demographic_parity_ratio", fairness_threshold=0.8, privileged_groups = [{"sex": "Male"}], underprivileged_groups = [{"sex": "Female"}], ) automl.fit(X_train, y_train, sensitive_features=S_train)
你可以在我们的文章 https://mljar.com/blog/fairness-machine-learning/ 中阅读更多关于公平性感知AutoML训练的内容
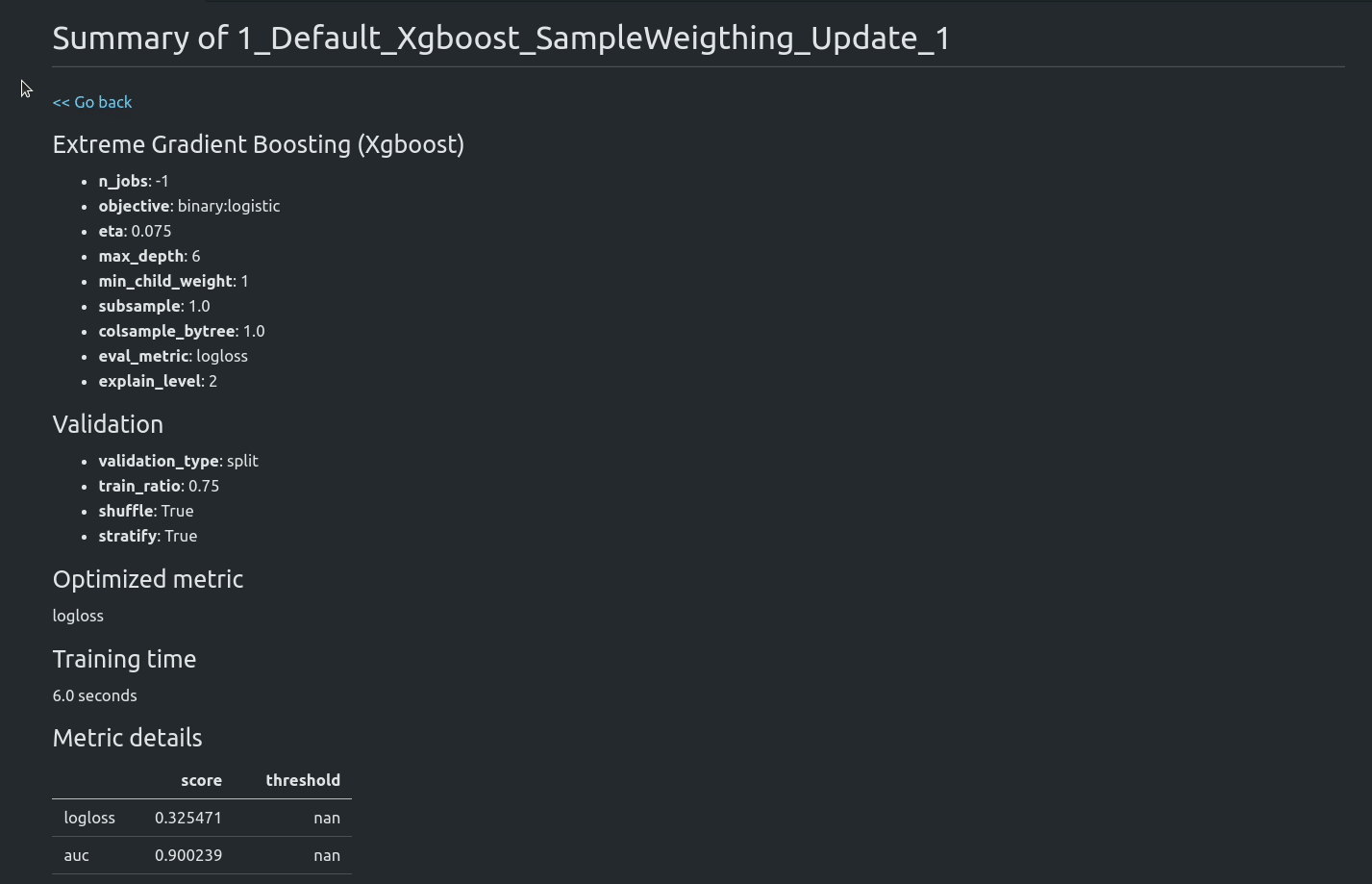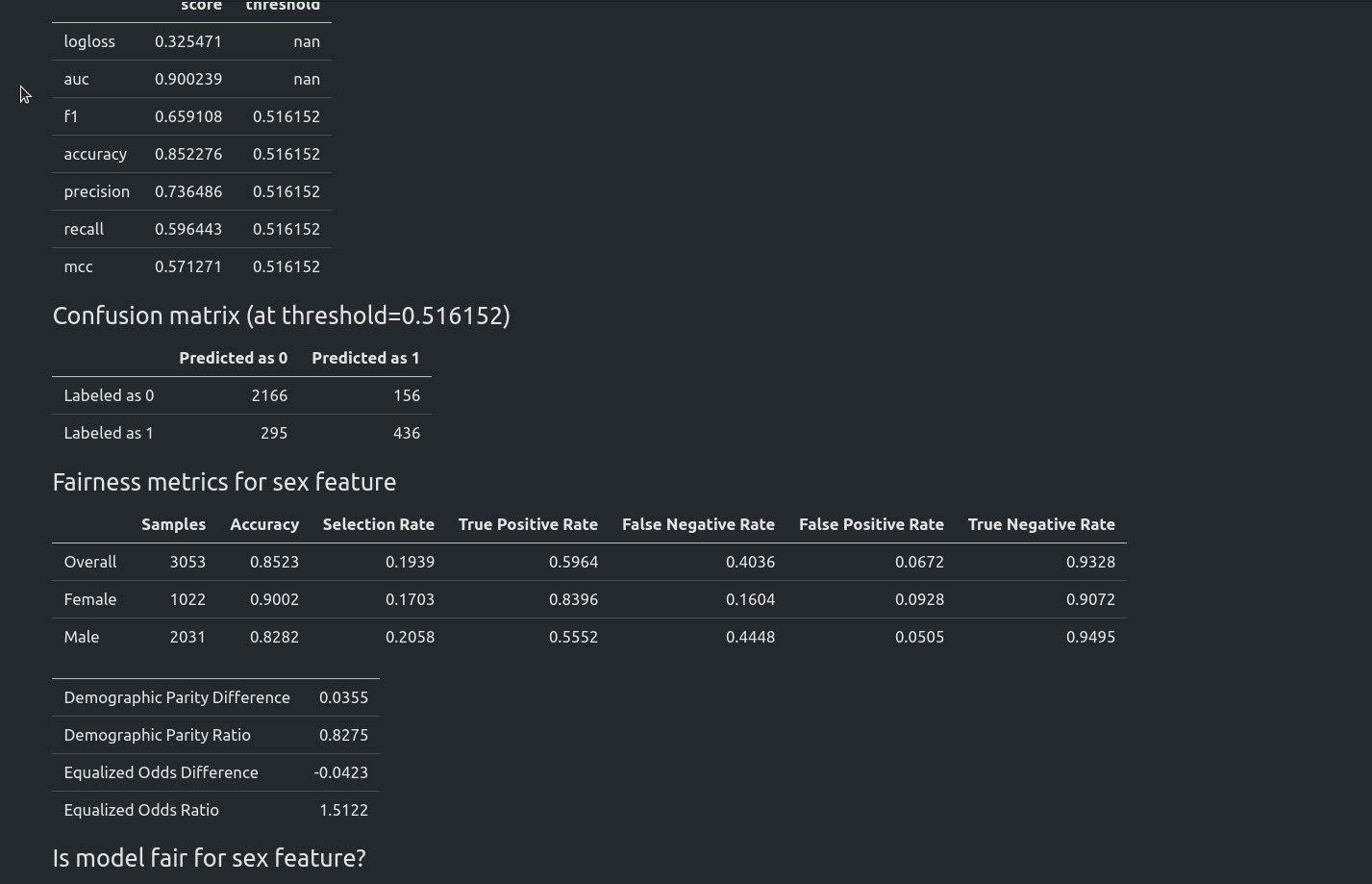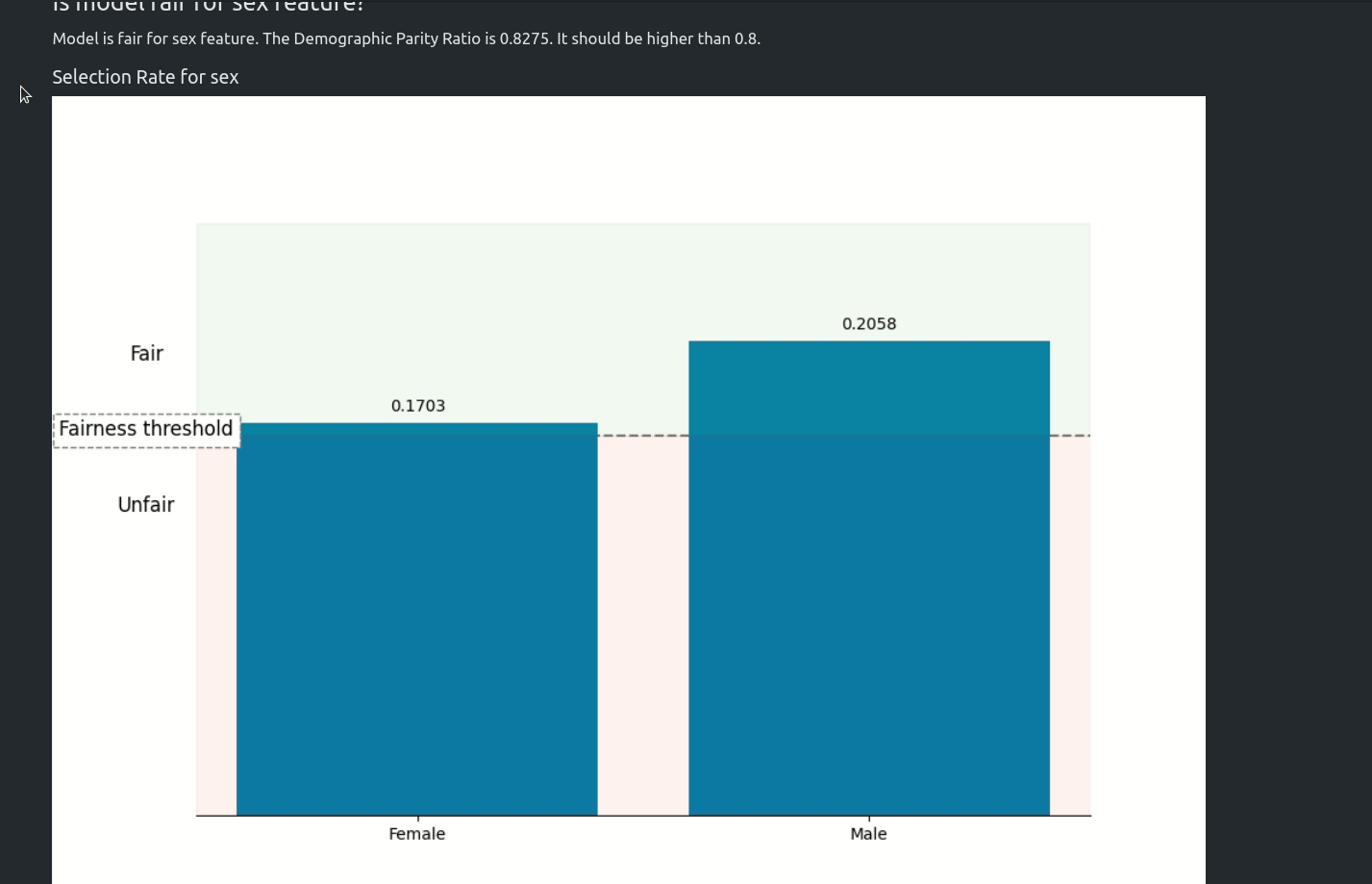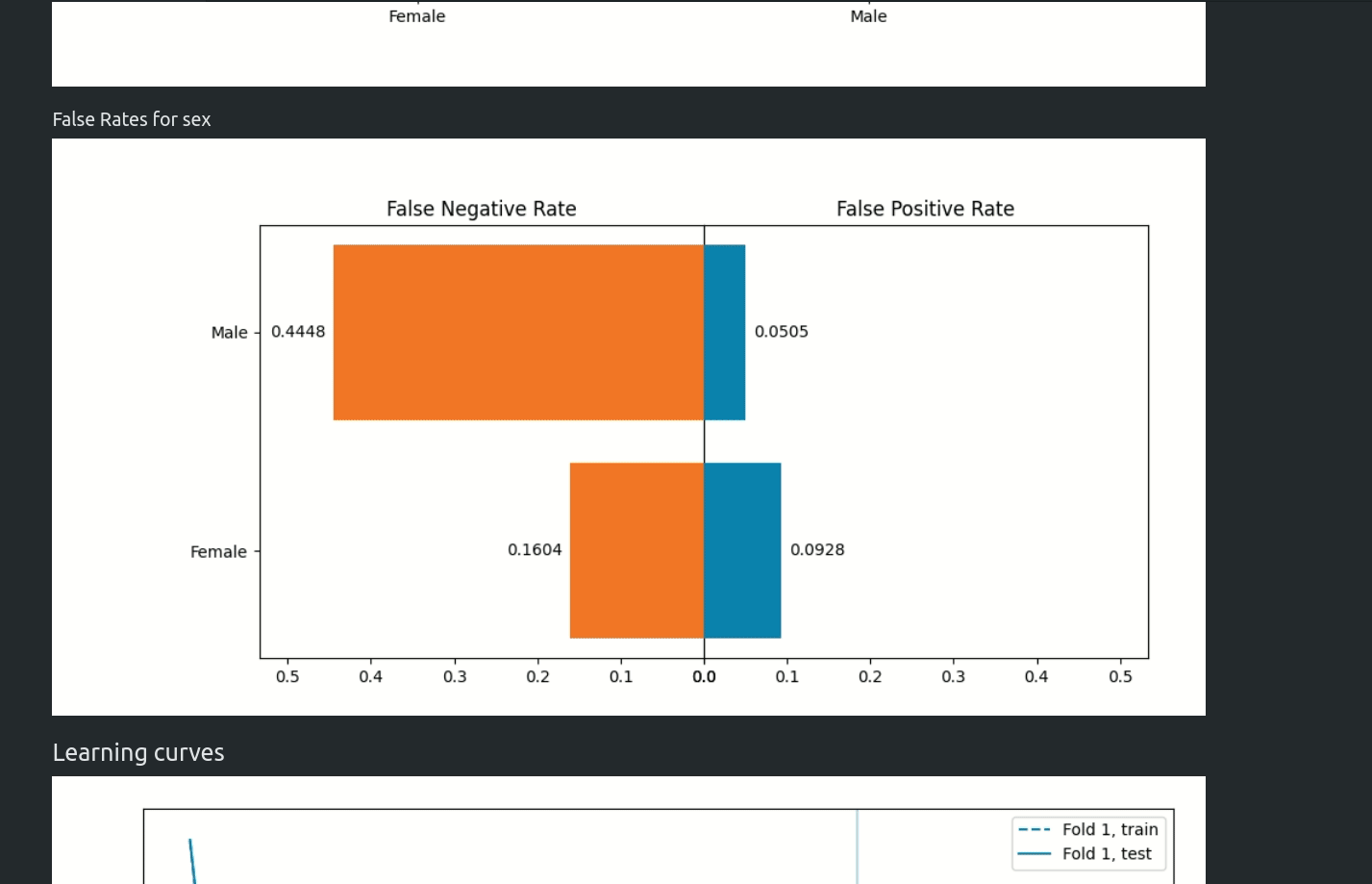
示例
:point_right: 二分类示例
有一个简单的接口可用,包含fit和predict方法。
import pandas as pd from sklearn.model_selection import train_test_split from supervised.automl import AutoML df = pd.read_csv( "https://raw.githubusercontent.com/pplonski/datasets-for-start/master/adult/data.csv", skipinitialspace=True, ) X_train, X_test, y_train, y_test = train_test_split( df[df.columns[:-1]], df["income"], test_size=0.25 ) automl = AutoML() automl.fit(X_train, y_train) predictions = automl.predict(X_test)
AutoML fit将打印:
Create directory AutoML_1 AutoML task to be solved: binary_classification AutoML will use algorithms: ['Baseline', 'Linear', 'Decision Tree', 'Random Forest', 'Xgboost', 'Neural Network'] AutoML will optimize for metric: logloss 1_Baseline final logloss 0.5519845471086654 time 0.08 seconds 2_DecisionTree final logloss 0.3655910192804364 time 10.28 seconds 3_Linear final logloss 0.38139916864708445 time 3.19 seconds 4_Default_RandomForest final logloss 0.2975204390214936 time 79.19 seconds 5_Default_Xgboost final logloss 0.2731086827200411 time 5.17 seconds 6_Default_NeuralNetwork final logloss 0.319812276905242 time 21.19 seconds Ensemble final logloss 0.2731086821194617 time 1.43 seconds
- AutoML结果在Markdown报告中
- Xgboost Markdown报告,请查看由SHAP包生成的惊人依赖图 :sparkling_heart:
- 决策树 Markdown报告,请查看美丽的树可视化 :sparkles:
- 逻辑回归 Markdown报告,请查看系数表,你可以比较(Xgboost、决策树和逻辑回归)之间的SHAP图 :coffee:
:point_right: 多分类示例
以下是手写数字光学识别数据集分类的示例代码。在不到30分钟内运行此代码将得到测试准确率约98%。
import pandas as pd # scikit learn工具 from sklearn.datasets import load_digits from sklearn.metrics import accuracy_score from sklearn.model_selection import train_test_split # mljar-supervised包 from supervised.automl import AutoML # 加载数据 digits = load_digits() X_train, X_test, y_train, y_test = train_test_split( pd.DataFrame(digits.data), digits.target, stratify=digits.target, test_size=0.25, random_state=123 ) # 使用AutoML训练模型 automl = AutoML(mode="Perform") automl.fit(X_train, y_train)
在测试数据上计算准确率
predictions = automl.predict_all(X_test) print(predictions.head()) print("测试准确率:", accuracy_score(y_test, predictions["label"].astype(int)))
## :point_right: 回归示例
使用`加州房价`数据集的回归示例。
```python
import numpy as np
import pandas as pd
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from supervised.automl import AutoML # mljar-supervised
# 加载数据
housing = fetch_california_housing()
X_train, X_test, y_train, y_test = train_test_split(
pd.DataFrame(housing.data, columns=housing.feature_names),
housing.target,
test_size=0.25,
random_state=123,
)
# 使用AutoML训练模型
automl = AutoML(mode="Explain")
automl.fit(X_train, y_train)
# 在测试数据上计算均方误差
predictions = automl.predict(X_test)
print("测试均方误差:", mean_squared_error(y_test, predictions))
:point_right: 更多示例
常见问题
<details><summary>使用什么方法进行超参数优化?</summary> - 对于"Explain"、"Perform"和"Compete"模式,使用随机搜索方法结合爬山算法。在这种方法中,所有检查过的模型都会被保存并用于构建集成模型。 - 对于"Optuna"模式,使用Optuna框架。它使用TPE采样器进行调优。在Optuna超参数搜索过程中检查的模型不会被保存,只保存最佳模型(调优的最终模型)。你可以通过查看AutoML `results_path`中`optuna`目录下的study文件来了解检查过的超参数详情。 </details> <details><summary>如何保存和加载AutoML?</summary>AutoML模型的保存和加载是自动的。在AutoML训练期间创建的所有模型都保存在results_path设置的目录中(AutoML()构造函数的参数)。如果没有设置results_path,则会创建一个以下命名约定的目录:AutoML_{number},其中number将是1到1000之间的数字(取决于哪个目录名可用)。
保存和加载示例:
automl = AutoML(results_path='AutoML_1') automl.fit(X, y)
所有AutoML模型都保存在AutoML_1目录中。
加载模型:
</details> <details><summary>如何设置机器学习任务(在分类或回归之间选择)?</summary>automl = AutoML(results_path='AutoML_1') automl.predict(X)
MLJAR AutoML可以处理:
- 二元分类
- 多类分类
- 回归
机器学习任务的检测是根据目标值自动进行的。如果你想手动强制AutoML选择机器学习任务,则需要设置ml_task参数。它可以设置为'binary_classification'、'multiclass_classification'、'regression'。
示例:
automl = AutoML(ml_task='regression') automl.fit(X, y)
在上面的例子中将拟合回归模型。
</details> <details><summary>如何重用Optuna超参数?</summary>你可以重用在其他AutoML训练中找到的Optuna超参数。你需要在optuna_init_params参数中传递它们。在Optuna调优过程中找到的所有超参数都保存在optuna/optuna.json文件中(在results_path目录内)。
示例:
optuna_init = json.loads(open('previous_AutoML_training/optuna/optuna.json').read()) automl = AutoML( mode='Optuna', optuna_init_params=optuna_init ) automl.fit(X, y)
当重用Optuna超参数时,Optuna调优会被简单跳过。模型将使用optuna_init_params中设置的超参数进行训练。目前没有选项可以继续使用种子参数进行Optuna调优。
要获取带有类别标签信息的预测概率,请使用predict_all()方法。它返回一个pandas DataFrame,其中列名为类别名称。predict_proba()和predict_all()方法中预测列的顺序是相同的。predict_all()方法还会额外包含一个预测类别标签的列。
文档
详细信息请查看mljar-supervised文档。
安装
从PyPi仓库安装:
pip install mljar-supervised
使用conda安装此包:
conda install -c conda-forge mljar-supervised
从源代码安装:
git clone https://github.com/mljar/mljar-supervised.git
cd mljar-supervised
python setup.py install
开发安装
git clone https://github.com/mljar/mljar-supervised.git
virtualenv venv --python=python3.6
source venv/bin/activate
pip install -r requirements.txt
pip install -r requirements_dev.txt
在Docker中运行:
FROM python:3.7-slim-buster
RUN apt-get update && apt-get -y update
RUN apt-get install -y build-essential python3-pip python3-dev
RUN pip3 -q install pip --upgrade
RUN pip3 install mljar-supervised jupyter
CMD ["jupyter", "notebook", "--port=8888", "--no-browser", "--ip=0.0.0.0", "--allow-root"]
使用pip从GitHub安装:
pip install -q -U git+https://github.com/mljar/mljar-supervised.git@master
演示
在下面的演示GIF中,你将看到:
- 在Jupyter Notebook中使用Titanic数据集训练的MLJAR AutoML
- 创建文件的概览
- AutoML训练期间创建的部分精选图表展示
- 算法比较报告及其图表
- README文件和包含结果的CSV文件示例
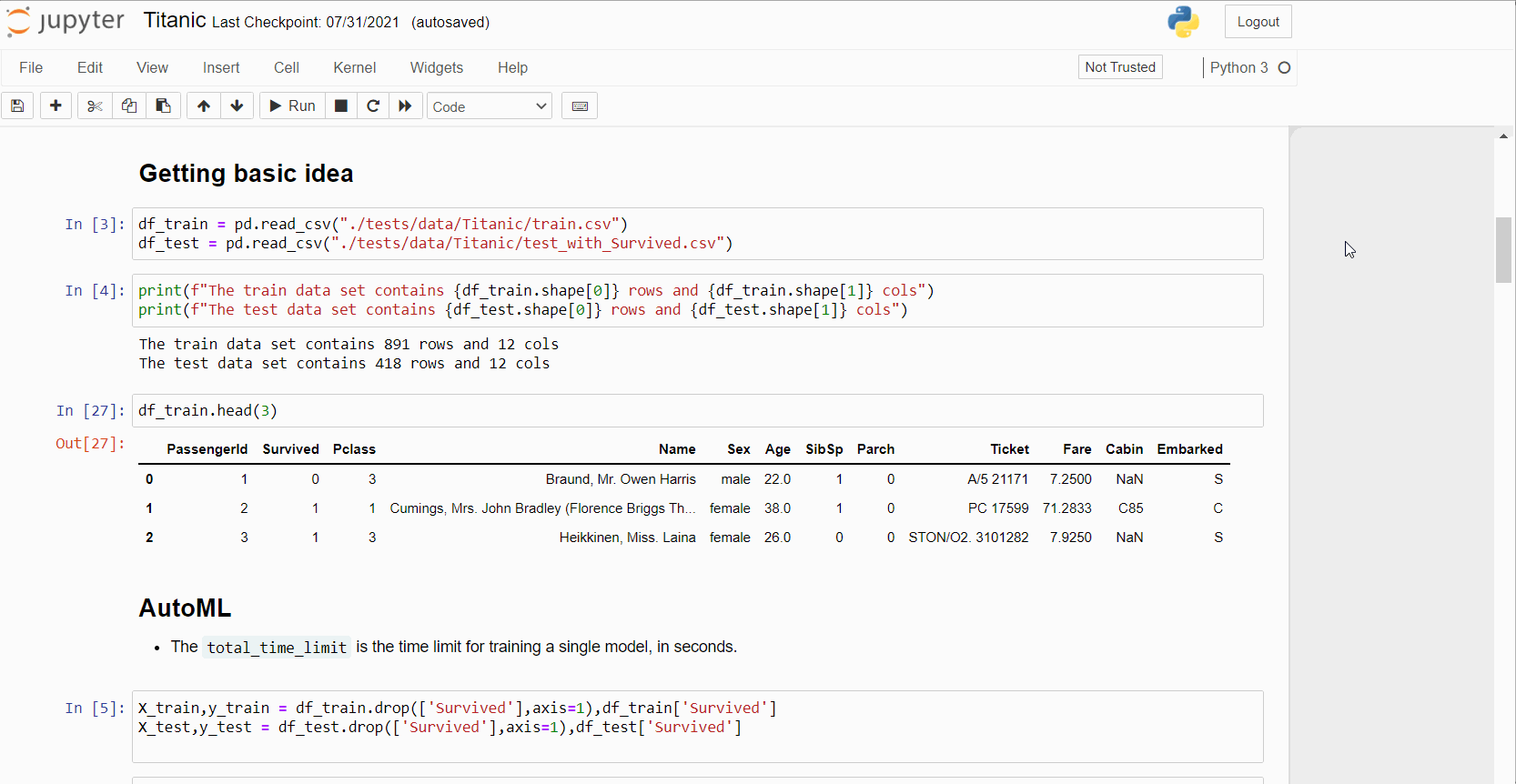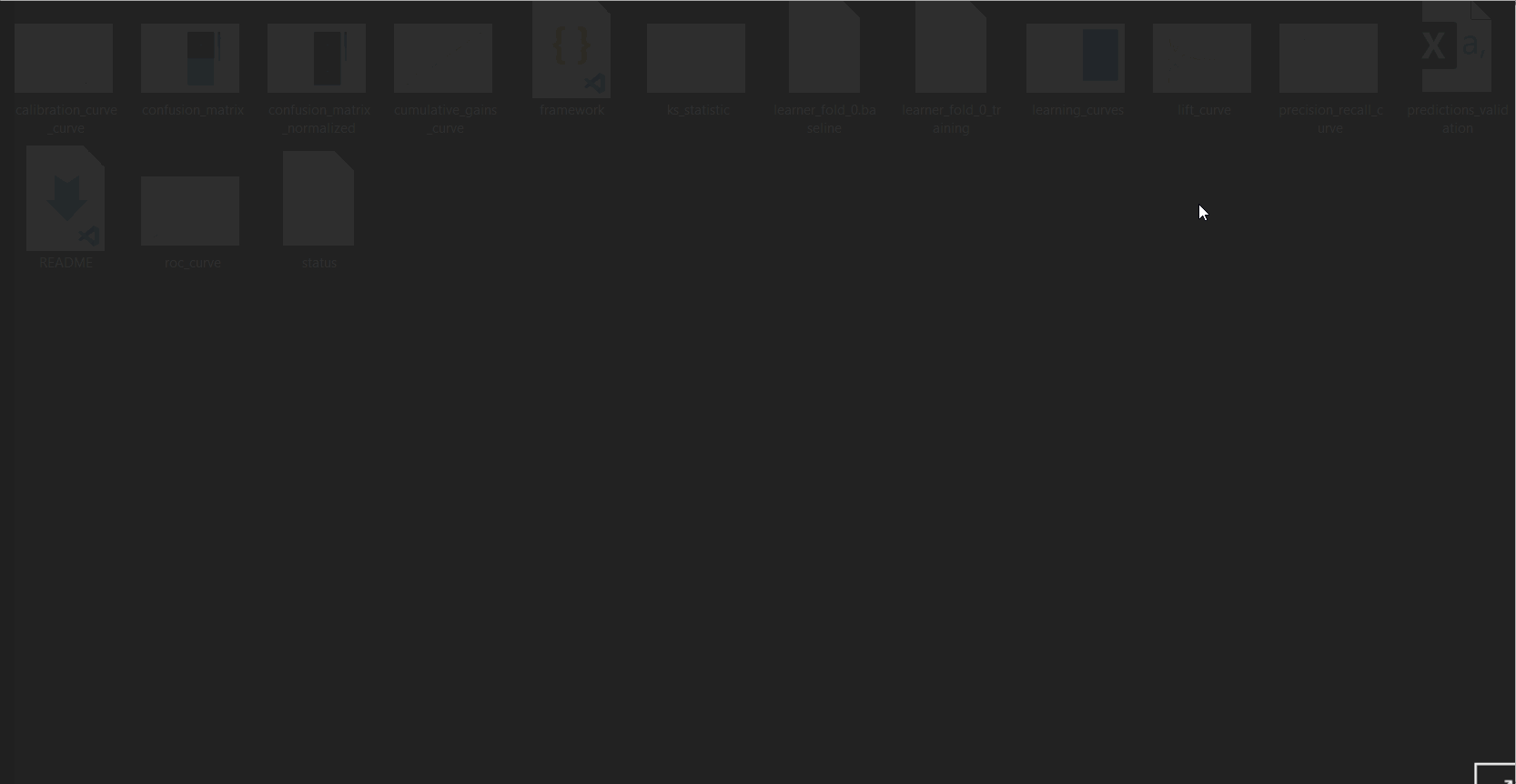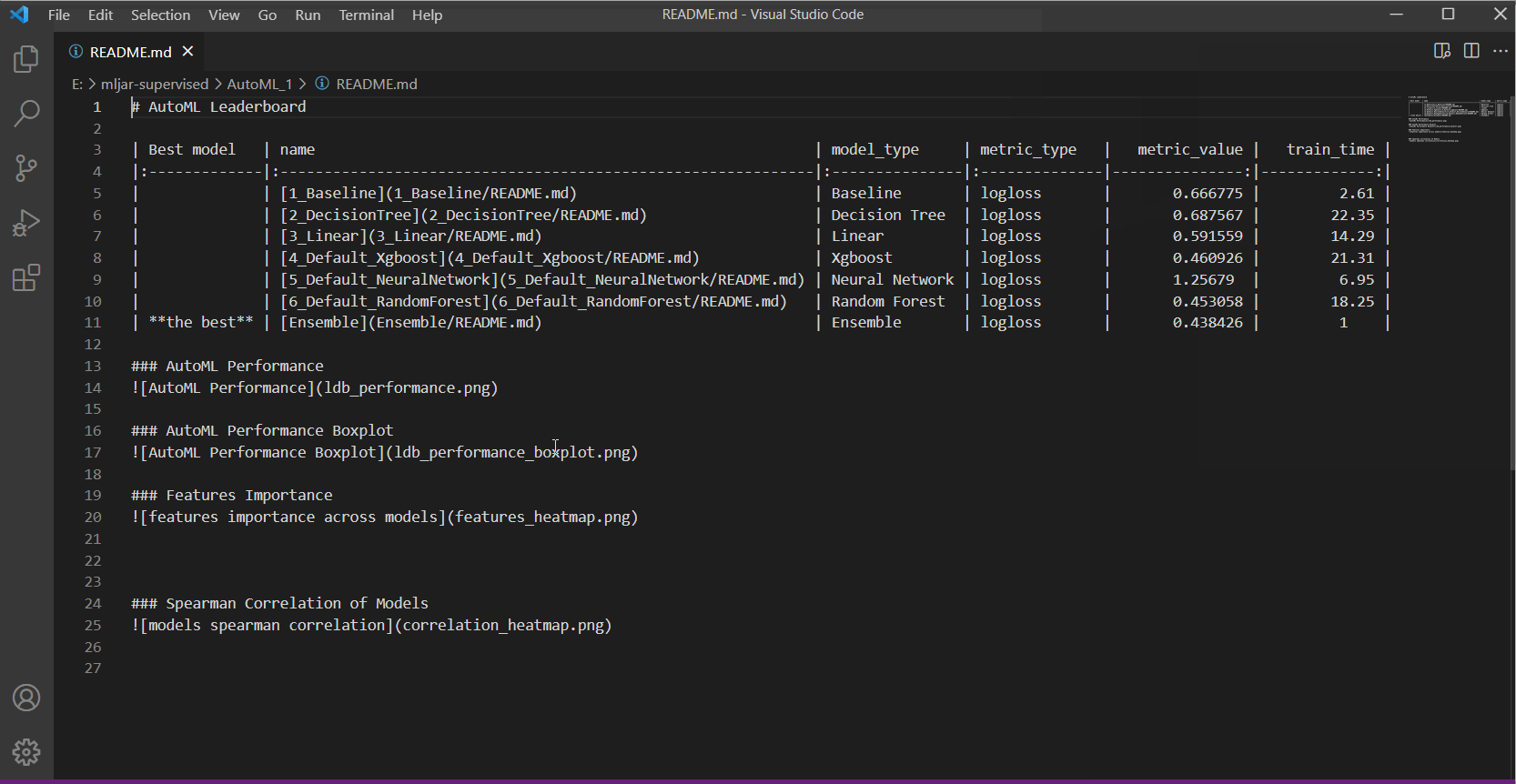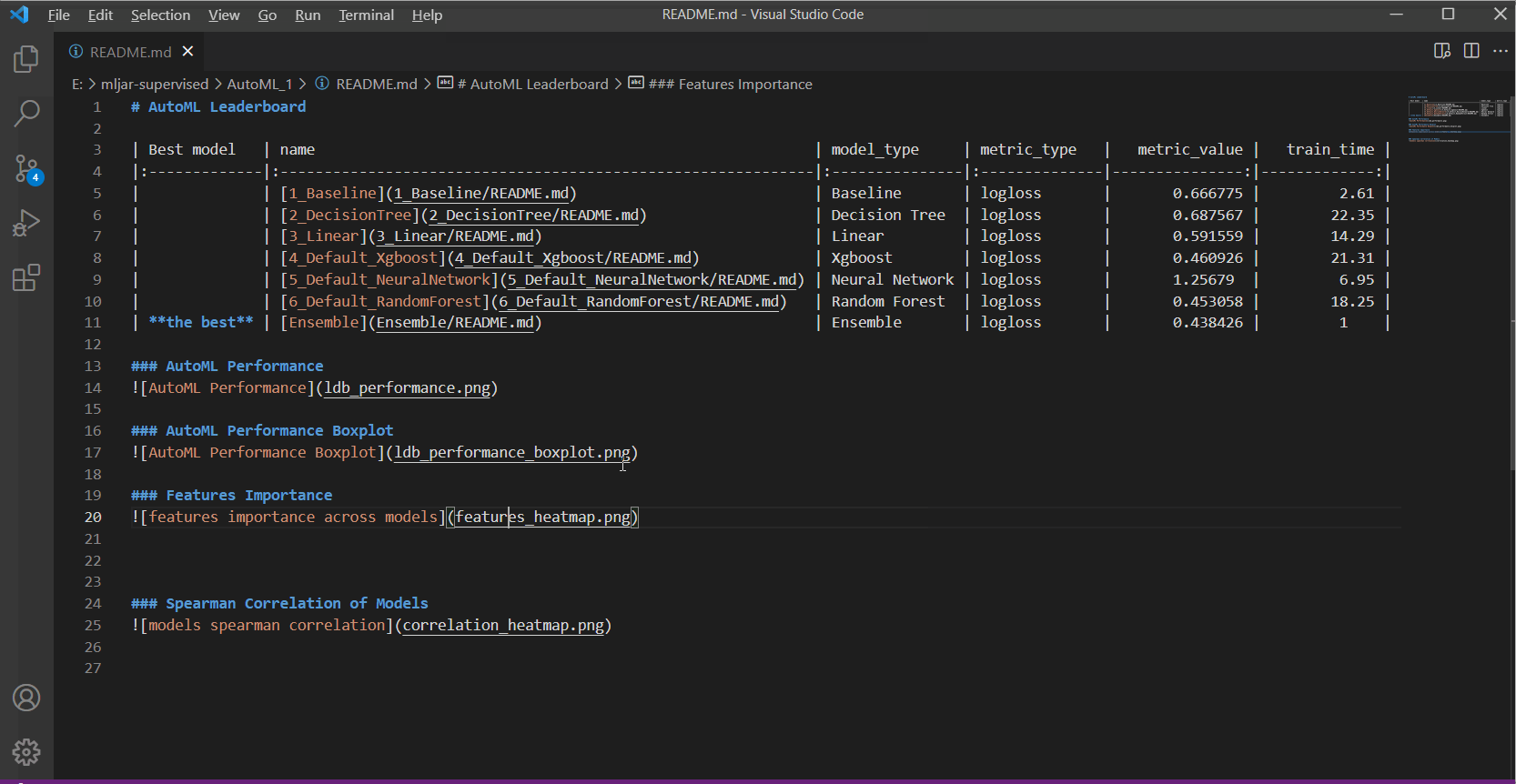
贡献
要开始贡献,请查看我们的贡献指南,了解有关我们流程的信息以及你可以如何参与其中!
贡献者
<a href="https://github.com/mljar/mljar-supervised/graphs/contributors"> <img src="https://contributors-img.web.app/image?repo=mljar/mljar-supervised" /> </a>引用
你想引用MLJAR吗?太好了!:)
你可以按以下方式引用MLJAR:
@misc{mljar,
author = {Aleksandra P\l{}o\'{n}ska and Piotr P\l{}o\'{n}ski},
year = {2021},
publisher = {MLJAR},
address = {\L{}apy, Poland},
title = {MLJAR: 用于表格数据的最先进自动机器学习框架。版本0.10.3},
url = {https://github.com/mljar/mljar-supervised}
}
我们很想听听你是如何在项目中使用MLJAR AutoML的。
请随时通过以下方式告诉我们

许可证
mljar-supervised采用MIT许可证提供。
商业支持
寻求商业支持?需要实现新功能?请通过电子邮件联系我们了解详情。
MLJAR
<p align="center"> <img src="https://yellow-cdn.veclightyear.com/ab5030c0/eb74f93e-a58d-474d-9254-17cf81faaf0d.png" width="314" /> </p>mljar-supervised是由MLJAR创建的开源项目。我们注重机器学习的易用性。
mljar.com提供了一个美观简洁的用户界面,用于构建机器学习模型。
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面�友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开��发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、�公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应�的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号