




sqlite_zstd_vfs
这是一个SQLite VFS扩展,提供使用Zstandard的流式存储压缩功能,可以在写入时透明地压缩主数据库文件的页面,并在后续读取时解压缩。它在后台线程上运行页面压缩/解压缩,并偶尔生成字典以改善后续压缩效果。
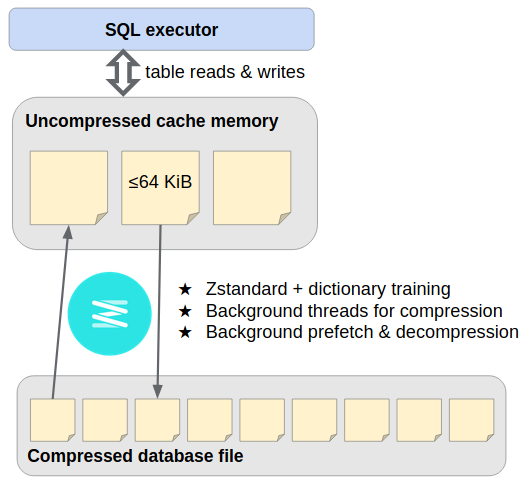
压缩页面存储的操作类似于SQLite开发者专有扩展ZIPVFS的设计。由于我们不太熟悉内部的"分页器"模块,我们使用完整的SQLite数据库作为最底层。当SQLite将数据库页面#P写入磁盘文件的偏移量P × page_size时,我们会执行INSERT INTO outer_page_table(rowid,data) VALUES(P,compressed_inner_page),之后通过SELECT data FROM outer_page_table WHERE rowid=P读取。亲爱的,你不必害怕做一些小小的梦想...
**使用风险自负:**该扩展对数据库存储层进行了根本性的改变。虽然设计上保留了ACID事务安全性,但它还很年轻,不太可能完全没有bug。本项目与SQLite开发者无关。
包含在GenomicSQLite中
使用此VFS最简单的方法是通过Genomics Extension for SQLite,它将其作为核心组件捆绑在一起,并预先调整了设置,还提供了良好打包的语言绑定。可以安全地忽略该扩展的生物信息学特定功能。
以下是独立使用说明。
快速入门
先决条件:
- C++11编译器,CMake >= 3.11
- 最新版本的SQLite3、Zstandard和libcurl开发包,例如Ubuntu 20.04的
sqlite3 libsqlite3-dev libzstd-dev libcurl4-openssl-dev
获取源代码并编译SQLite可加载扩展:
git clone https://github.com/mlin/sqlite_zstd_vfs.git
cd sqlite_zstd_vfs
cmake -DCMAKE_BUILD_TYPE=Release -B build
cmake --build build -j $(nproc)
下载约1MB��的示例数据库,并使用sqlite3命令行界面创建其压缩版本:
wget https://github.com/lerocha/chinook-database/raw/master/ChinookDatabase/DataSources/Chinook_Sqlite.sqlite
sqlite3 Chinook_Sqlite.sqlite -bail \
-cmd '.load build/zstd_vfs.so' \
"VACUUM INTO 'file:Chinook_Sqlite.zstd.sqlite?vfs=zstd'"
ls -l Chinook_Sqlite.*
压缩版本大约小了40%;通过更大的数据库和一些调优(见下文),你通常会看到更好的效果。你可以通过sqlite3 -cmd '.load build/zstd_vfs.so' -cmd '.open file:new_db?vfs=zstd'启动一个新数据库,但上述方法为本例提供了一些可供操作的内容。
查询压缩数据库:
sqlite3 :memory: -bail \
-cmd '.load build/zstd_vfs.so' \
-cmd '.open file:Chinook_Sqlite.zstd.sqlite?mode=ro&vfs=zstd' \
"select e.*, count(i.invoiceid) as 'Total Number of Sales'
from employee as e
join customer as c on e.employeeid = c.supportrepid
join invoice as i on i.customerid = c.customerid
group by e.employeeid"
或在Python中:
python3 - << 'EOF' import sqlite3 conn = sqlite3.connect(":memory:") conn.enable_load_extension(True) conn.load_extension("build/zstd_vfs.so") conn = sqlite3.connect("file:Chinook_Sqlite.zstd.sqlite?mode=ro&vfs=zstd", uri=True) for row in conn.execute(""" select e.*, count(i.invoiceid) as 'Total Number of Sales' from employee as e join customer as c on e.employeeid = c.supportrepid join invoice as i on i.customerid = c.customerid group by e.employeeid """): print(row) EOF
写入压缩数据库:
sqlite3 :memory: -bail \
-cmd '.load build/zstd_vfs.so' \
-cmd '.open file:Chinook_Sqlite.zstd.sqlite?vfs=zstd' \
"update employee set Title = 'SVP Global Sales' where FirstName = 'Steve'"
重复查询以查看更新。
该扩展还包含web_vfs。可以通过打开URI file:/__web__?vfs=zstd&mode=ro&immutable=1&web_url={{PERCENT_ENCODED_URL}}从HTTP(S) URL读取压缩数据库。
限制
- 主要面向Unix x86-64;欢迎其他平台的帮助。
- 始终应用EXCLUSIVE锁定模式(写入器在其连接期间排除所有其他连接)。
- 放宽这一限制是可能的,但自然需要严格的并发测试。欢迎帮助。
- 尚不支持WAL模式;请勿触碰。
- 需要调整几个SQLite设置以获得良好性能(见下文)。
- 再次强调:使用风险自负
性能
以下是在Google N2 VM上使用1,195MiB的TPC-H数据库进行的一些操作计时。这不是一个全面的��基准测试,只是粗略表明许多应用程序应该会发现压缩/解压缩的开销值得节省的存储空间。
| 数据库文件大小 | 批量加载<sup>1</sup> | 查询1 | 查询8 | |
|---|---|---|---|---|
| SQLite 默认设置 | 1182MiB | 2.4秒 | 6.7秒 | 3.0秒 |
| zstd_vfs 默认设置 | 647MiB | 25.0秒 | 8.8秒 | 35.7秒 |
| zstd_vfs 优化<sup>2</sup> | 433MiB | 33.7秒 | 7.8秒 | 4.5秒 |
| zstd_vfs 优化 &threads=8 | 433MiB | 6.9秒 | 6.7秒 | 3.1秒 |
<sup>1</sup> 通过VACUUM INTO实现<br/>
<sup>2</sup> &level=6&outer_page_size=2048&outer_unsafe=true; PRAGMA page_size=65536; PRAGMA cache_size=-102400
查询1是一次表扫描就能满足的聚合查询。前台Zstandard解压缩使其速度降低约25%,而数据库文件大小缩小了45-65%。(每次查询开始时,文件系统缓存是热的,而数据库页面缓存是冷的。)
查询8是一个历史上具有影响力的八路连接查询。SQLite默认的约2MB页面缓存对其访问模式来说太小,导致重复页面解压缩造成严重的性能下降;但只要将页面缓存增加到100MiB就能在很大程度上解决这个问题。显然,考虑到缓存未命中的增加成本,我们应该倾向于使用更大的页面缓存。
后台线程可用于压缩和顺序扫描期间的"预取"。这大大提高了批量加载速度,有时甚至可以完全隐藏解压缩延迟(在顺序访问模式、大页面和有空闲CPU可用的情况下)。
调优
一些参数通过打开数据库的文件URI查询字符串控制,而其他参数则通过PRAGMA语句稍后设置:
| URI查询参数 | PRAGMA | |
|---|---|---|
| 写入/压缩 | <ul><li>level</li><li>threads</li><li>outer_page_size</li><li>outer_unsafe</li></ul> | <ul><li>page_size</li><li>auto_vacuum</li><li>journal_mode</li></ul> |
| 读取/解压缩 | <ul><li>outer_cache_size</li><li>noprefetch</li></ul> | <ul><li>cache_size</li></ul> |
-
&level=3:新写入页面的Zstandard压缩级别(-7到22)
-
&threads=1:页面压缩和预取的线程预算(-1表示匹配主机处理器数量)
-
&outer_page_size=4096:新创建的外部数据库的页面大小;建议设为(内部)page_size的两倍�,以减少打包压缩内部页面的空间开销
-
&outer_unsafe=false:设为true可通过禁用外部数据库的事务安全来加速批量加载(应用程序崩溃容易导致数据损坏)
-
&outer_cache_size=-2000:外部数据库的页面缓存大小,单位与PRAGMA cache_size相同。如果在SSD上效果有限。
-
&noprefetch=false:即使threads>1,设为true也会禁用后台预取/解压缩。如果page_size太小或CPU资源紧张,预取可能会适得其反。
-
PRAGMA page_size=4096:新创建的内部数据库的未压缩页面大小。较大的页面更易压缩,但会增加读写放大。效果因情况而异,但8或16 KiB对我们来说效果不错。
-
PRAGMA auto_vacuum=NONE:如果预计数据库大小会随时间波动,在新创建的数据库上设为FULL或INCREMENTAL,这样文件会自动收缩。(外部数据库在关闭时会自动执行vacuum。)
-
PRAGMA journal_mode=DELETE:如ZIPVFS文档中Multiple Journal Files部分所讨论的,设为MEMORY或OFF。(如文档所述,这不应影响事务安全性。)
-
PRAGMA cache_size=-2000:内部数据库的页面缓存大小,单位与PRAGMA cache_size相同。对复杂查询性能至关重要,如上文所示。
对于批量加载,使用&outer_unsafe=true URI参数和SQLITE_OPEN_NOMUTEX标志打开数据库,然后执行PRAGMA journal_mode=OFF; PRAGMA synchronous=OFF。在一个大事务中插入所有内容,创建所需的索引,然后提交。
建议使用VACUUM INTO 'file:fresh_copy.db?vfs=zstd'(加上上述URI参数)来整理长期经过大量修改的数据库。
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制�作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可��快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号