



Quest: 面向高效长文本LLM推理的查询感知稀疏性


概要
Quest是一个高效的长文本LLM推理框架,利用KV缓存中的查询感知稀疏性来减少注意力计算过程中的内存移动,从而提高吞吐量。
摘要
随着对长文本大型语言模型(LLMs)需求的增加,具有高达128k或1M令牌上下文窗口的模型变得越来越普遍。然而,长文本LLM推理具有挑战性,因为随着序列长度的增加,推理速度显著降低。这种减速主要是由于在自注意力计算过程中加载大型KV缓存造成的。先前的研究表明,少量关键令牌将主导注意力结果。然而,我们观察到令牌的重要性高度依赖于查询。
为此,我们提出了Quest,一种查询感知的令牌重要性估计算法。Quest跟踪KV缓存页面中的最小和最大Key值,并使用Query向量估计给定页面的重要性。通过仅加载Top-K关键KV缓存页面进行注意力计算,Quest显著加速了自注意力计算,而不牺牲准确性。我们展示了Quest可以实现高达7.03倍的自注意力加速,将推理延迟减少2.23倍,同时在长依赖任务上表现良好,准确性损失可忽略不计。
安装
- 克隆此仓库(同时克隆子模块)
git clone --recurse-submodules https://github.com/mit-han-lab/quest
cd quest
- 安装依赖库
conda create -yn quest python=3.10
conda activate quest
pip install -e . && pip install flash-attn==2.3.0 --no-build-isolation
# 安装CMake(�版本 >= 3.26.4)
conda install cmake
# 构建libraft
cd kernels/3rdparty/raft
./build.sh libraft
- 编译内核基准测试(可选)。记得配置CUDA的环境变量(查看教程)。
cd kernels
mkdir build && cd build
cmake ..
make -j
- 使用PyBind构建端到端操作符
# 这将自动构建和链接操作符
cd quest/ops
bash setup.sh
准确性评估
我们的评估基于LongChat-7B-v1.5-32K和Yarn-Llama2-7B-128K模型,这些模型能够处理长文本生成。我们评估了密钥检索和LongBench基准测试。我们提供了几个脚本来重现论文中的结果:
要获取密钥检索结果,请修改并执行:
bash scripts/passkey.sh
要重现LongBench结果,请修改并执行:
bash scripts/longbench.sh
要评估PG-19的困惑度结果,请执行:
bash scripts/ppl_eval.sh
效率评估
内核和端到端效率评估在NVIDIA Ada6000和RTX4090 GPU上进行,CUDA版本为12.4。我们提供了几个脚本来重现论文中的结果:
内核级效率
我们还发布了用于内核实现的单元测试和基准测试。内核的正确性通过kernels/src/test中的单元测试进行验证,而性能则通过kernels/src/bench中的NVBench进行评估。我们还在quest/tests中使用PyTest通过PyTorch结果测试了PyBind操作符的正确性。
要测试内核的正确性,请执行:
cd kernels/build
./test_batch_decode # 或任何其他操作符
或使用PyTest:
cd quest/tests
PYTHONPATH=$PYTHONPATH:../../ pytest
要重现论文中显示的内核性能,请执行:
cd kernels/build
./bench_batch_decode -a seqlen=4096 -a page_budget=[64,512]
# 或任何其他操作符
示例输出:

端到端效率
Quest可以实现高达2.23倍的端到端加速,同时在长依赖任务上表现良好,准确性损失可忽略不计:
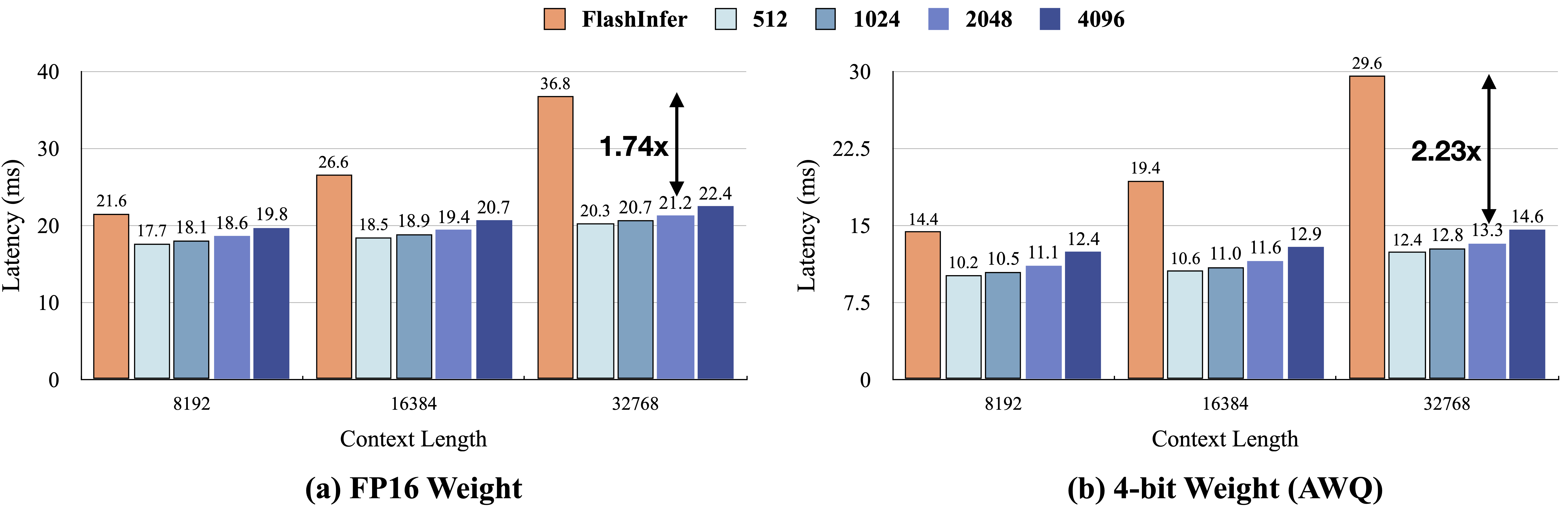
我们将所有实现的操作符整合到一个完整的流程中,以评估文本生成的端到端效率。基于Huggingface Transformers,我们启用了一个支持查询感知稀疏性的KV缓存管理器,如quest/models/QuestAttention.py所示。
要重现图10中的端到端效率结果,请执行:
bash scripts/bench_efficiency_e2e.sh
对于基线的定性分析,我们使用FlashInfer内核来估计H2O和TOVA的性能。要重现图11中的结果,请执行:
bash scripts/bench_kernels.sh
示例
我们提供了几个示例来演示Quest的使用。这些示例使用Quest操作符的端到端集成实现,可以通过以下命令执行(请确保您已设置好所有操作符):
python3 scripts/example_textgen.py
LongChat-7B-v1.5-32K模型下长文本摘要的示例输出:

您还可以尝试scripts/example_demo.py来测试Quest在您自己的文本生成任务上的性能。我们提供了一个简单的接口来加载模型并使用Quest操作符生成文本。上面的演示是一个使用32K输入在FP16 LongChat-7B-v1.5-32K上的示例。使用2048令牌预算的Quest比完整缓存FlashInfer版本实现了1.7倍的加速。
待办事项
- 支持GQA模型
参考
如果您发现这个项目对您的研究有帮助,请考虑引用我们的论文:
@misc{tang2024quest,
title={Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference},
author={Jiaming Tang and Yilong Zhao and Kan Zhu and Guangxuan Xiao and Baris Kasikci and Song Han},
year={2024},
eprint={2406.10774},
archivePrefix={arXiv},
primaryClass={id='cs.CL' full_name='Computation and Language' is_active=True alt_name='cmp-lg' in_archive='cs' is_general=False description='Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.'}
}
相关项目
本代码库使用lm_eval来评估困惑度和零样本准确性。它还改编了来自H2O、StreamingLLM和Punica的代码片段。我们的内核基于FlashInfer(一个高性能且可扩展的LLM服务内核库)实现,并由NVBench进行测试。感谢我们社区的优秀工作!
编辑推荐精选


GPT Plus|Pro充值
GPT充值
支持 ChatGPT Plus / Pro 充值服务,支付便捷,自动发货,售后可查。


GPT Image 2中文站
AI 图片生成平台
GPT Image 2 是面向用户的 AI 图片生成平台,支持文生图、图生图及多模型创意工作流。


Vecbase
你的AI Agent团队
Vecbase 是专为 AI 团队打造的智能工作空间,将数据管理、模型协作与知识沉淀整合于一处。算法、产品与业务在同一平台无缝协同,让从数据到 AI 应用的落地更快一步。


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


QoderWork
阿里Qoder团队推出的桌面端AI智能体
QoderWork 是阿里推出的本地优先桌面 AI 智能体,适配 macOS14+/Windows10+,以自然语言交互实现文件管理、数据分析、AI 视觉生成、浏览器自动化等办公任务,自主拆解执行复杂工作流,数据本地运行零上传,技能市场可无限扩展,是高效的 Agentic 生产力办公助手。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。


seedancetwo2.0
能听懂你表达的视频模型
Seedance two是基于seedance2.0的中国大模型,支持图像、视频、音频、文本四种模态输入,表达方式更丰富,生成也更可控。


nano-banana纳米香蕉中文站
国内直接访问,限时3折
输入简单文字,生成想要的图片,纳米香蕉中文站基于 Google 模型的 AI 图片生成网站,支持文字生图、图生图。官网价格限时3折活动


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!
推荐工具精选





AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号