



simglucose
一个用Python实现的1型糖尿病模拟器,用于强化学习目的
这个模拟器是FDA批准的UVa/Padova模拟器(2008版)的Python实现,仅供研究使用。模拟器包含30个虚拟患者,10名青少年,10名成人,10名儿童。
如何引用: Jinyu Xie. Simglucose v0.2.1 (2018) [在线]. 可用: https://github.com/jxx123/simglucose. 访问日期: 月-日-年.
注意: simglucose不再支持Python 3.7和3.8版本,请更新至3.9或更高版本。谢谢!
公告 (2023年8月20日): simglucose现已支持gymnasium! 查看examples/run_gymnasium.py了解使用方法。
| 动画 | CVGA图 | 血糖追踪图 | 风险指数统计 |
|---|---|---|---|
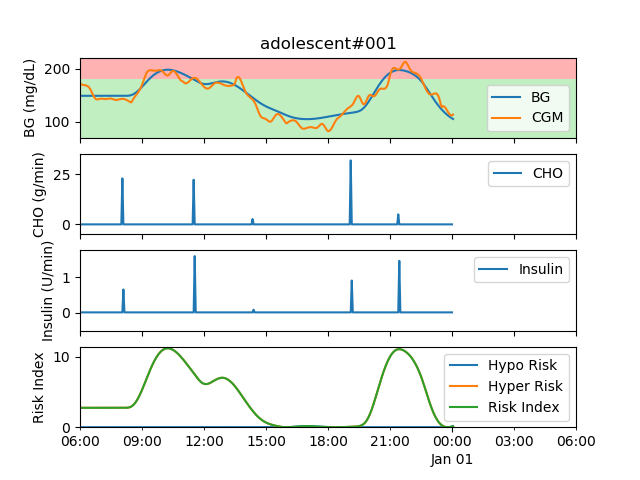 | 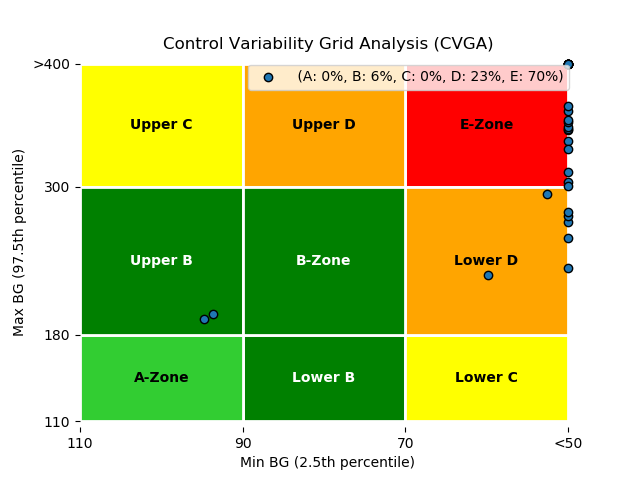 | 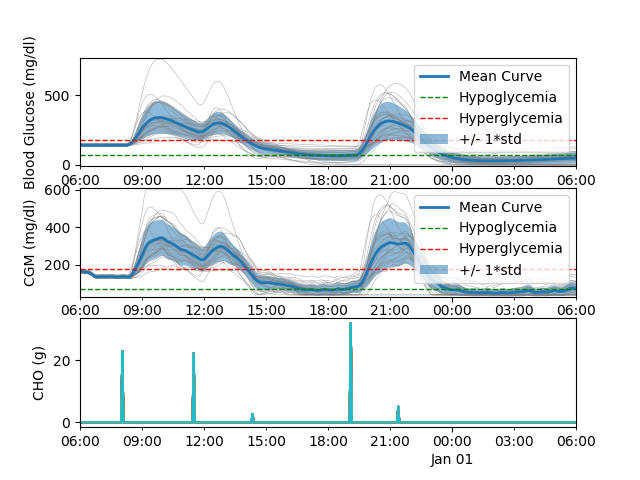 | 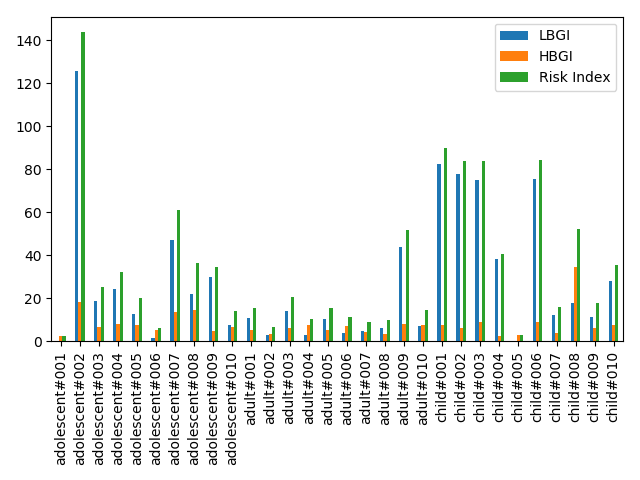 |
主要特性
- 模拟环境遵循OpenAI gym和rllab API。每一步都返回观察、奖励、是否结束和信息,这意味着模拟器已经"准备好用于强化学习"。
- 支持自定义奖励函数。奖励函数是过去一小时内血糖测量值的函数。默认情况下,每一步的奖励是
risk[t-1] - risk[t]。risk[t]是时间t的风险指数,定义见这篇论文。 - 支持并行计算。模拟器使用pathos多进程包并行模拟多个患者(您可以通过设置
parallel=False关闭并行)。 - 模拟器提供随机场景生成器(
from simglucose.simulation.scenario_gen import RandomScenario)和自定义场景生成器(from simglucose.simulation.scenario import CustomScenario)。命令行用户界面将指导您完成场景设置。 - 模拟器目前提供最基本的基础-大剂量控制器。它提供了非常简单的语法来实现您自己的控制器,如模型预测控制、PID控制、强化学习控制等。
- 您可以指定随机种子,以便重复实验。
- 模拟后,模拟器将生成几个性能分析图。这些图包括血糖追踪图、控制变异性网格分析(CVGA)图、不同区域血糖统计图、风险指数统计图。
- 注意:在macOS中,
animate和parallel不能同时设置为True。macOS中大多数matplotlib后端都不是线程安全的。Windows尚未测试。如果有人测试过,请告知结果。
安装
强烈建议使用pip安装simglucose,请点击此链接安装pip。
自动安装:
pip install simglucose
手动安装:
git clone https://github.com/jxx123/simglucose.git cd simglucose
如果您已安装pip,则:
pip install -e .
如果您没有安装pip,则:
python setup.py install
如果安装了rllab(可选),该包将利用rllab中的一些功能。
注意:自动安装版本和手动安装版本之间可能存在一些细微差异。使用git clone和手动安装以获取最新版本。
快速开始
将simglucose用作模拟器并测试控制器
运行模拟器用户界面
from simglucose.simulation.user_interface import simulate simulate()
您可以自由实现自己的控制器,并在模拟器中测试。例如:
from simglucose.simulation.user_interface import simulate from simglucose.controller.base import Controller, Action class MyController(Controller): def __init__(self, init_state): self.init_state = init_state self.state = init_state def policy(self, observation, reward, done, **info): ''' 每个控制器必须实现此方法! ---- 输入: observation - 在simglucose.simulation.env中定义的命名元组。目前 它只有一个条目:CGM传感器测量的血糖水平。 reward - 环境返回的当前奖励 done - True,游戏结束。False,游戏继续 info - 额外信息作为关键字参数, simglucose.simulation.env.T1DSimEnv返回patient_name 和sample_time ---- 输出: action - 在此文件开头定义的命名元组。控制器 动作包含两个条目:basal,bolus ''' self.state = observation action = Action(basal=0, bolus=0) return action def reset(self): ''' 将控制器状态重置为初始状态,必须实现 ''' self.state = self.init_state ctrller = MyController(0) simulate(controller=ctrller)
这两个示例也可以在examples\文件夹中找到。
实际上,您可以通过simulation指定更多的模拟参数:
simulate(sim_time=my_sim_time, scenario=my_scenario, controller=my_controller, start_time=my_start_time, save_path=my_save_path, animate=False, parallel=True)
OpenAI Gym 用法
- 使用默认奖励
import gym # 注册gym环境。通过指定kwargs, # 你可以选择模拟哪个或哪些患者。 # patient_name必须是'adolescent#001'到'adolescent#010', # 或'adult#001'到'adult#010',或'child#001'到'child#010' # 它也可以是患者名称列表 # 你还可以指定自定义场景或自定义场景列表 # 如果你选择了患者名称列表或自定义场景列表, # 每次环境重置时,都会从列表中随机选择一个患者和场景 from gym.envs.registration import register from simglucose.simulation.scenario import CustomScenario from datetime import datetime start_time = datetime(2018, 1, 1, 0, 0, 0) meal_scenario = CustomScenario(start_time=start_time, scenario=[(1,20)]) register( id='simglucose-adolescent2-v0', entry_point='simglucose.envs:T1DSimEnv', kwargs={'patient_name': 'adolescent#002', 'custom_scenario': meal_scenario} ) env = gym.make('simglucose-adolescent2-v0') observation = env.reset() for t in range(100): env.render(mode='human') print(observation) # gym环境中的动作是一个标量 # 代表基础胰岛素,这与 # gym环境外的常规控制器动作不同 # (一个元组(basal, bolus))。 # 在理�想情况下,代理应该能够 # 仅通过基础胰岛素控制血糖,而不是 # 要求患者注射大剂量胰岛素 action = env.action_space.sample() observation, reward, done, info = env.step(action) if done: print("在{}个时间步后,回合结束".format(t + 1)) break
- 自定义奖励函数
import gym from gym.envs.registration import register def custom_reward(BG_last_hour): if BG_last_hour[-1] > 180: return -1 elif BG_last_hour[-1] < 70: return -2 else: return 1 register( id='simglucose-adolescent2-v0', entry_point='simglucose.envs:T1DSimEnv', kwargs={'patient_name': 'adolescent#002', 'reward_fun': custom_reward} ) env = gym.make('simglucose-adolescent2-v0') reward = 1 done = False observation = env.reset() for t in range(200): env.render(mode='human') action = env.action_space.sample() observation, reward, done, info = env.step(action) print(observation) print("奖励 = {}".format(reward)) if done: print("在{}个时间步后,回合结束".format(t + 1)) break
rllab用法
from rllab.algos.ddpg import DDPG from rllab.envs.normalized_env import normalize from rllab.exploration_strategies.ou_strategy import OUStrategy from rllab.policies.deterministic_mlp_policy import DeterministicMLPPolicy from rllab.q_functions.continuous_mlp_q_function import ContinuousMLPQFunction from rllab.envs.gym_env import GymEnv from gym.envs.registration import register register( id='simglucose-adolescent2-v0', entry_point='simglucose.envs:T1DSimEnv', kwargs={'patient_name': 'adolescent#002'} ) env = GymEnv('simglucose-adolescent2-v0') env = normalize(env) policy = DeterministicMLPPolicy( env_spec=env.spec, # 神经网络策略应该有两个隐藏层,每层32个隐藏单元。 hidden_sizes=(32, 32) ) es = OUStrategy(env_spec=env.spec) qf = ContinuousMLPQFunction(env_spec=env.spec) algo = DDPG( env=env, policy=policy, es=es, qf=qf, batch_size=32, max_path_length=100, epoch_length=1000, min_pool_size=10000, n_epochs=1000, discount=0.99, scale_reward=0.01, qf_learning_rate=1e-3, policy_learning_rate=1e-4 ) algo.train()
高级用法
你可以创建模拟对象,并运行批量模拟。例如,
from simglucose.simulation.env import T1DSimEnv from simglucose.controller.basal_bolus_ctrller import BBController from simglucose.sensor.cgm import CGMSensor from simglucose.actuator.pump import InsulinPump from simglucose.patient.t1dpatient import T1DPatient from simglucose.simulation.scenario_gen import RandomScenario from simglucose.simulation.scenario import CustomScenario from simglucose.simulation.sim_engine import SimObj, sim, batch_sim from datetime import timedelta from datetime import datetime # 将start_time指定为今天的开始 now = datetime.now() start_time = datetime.combine(now.date(), datetime.min.time()) # --------- 创建随机场景 -------------- # 指定结果保存路径 path = './results' # 创建模拟环境 patient = T1DPatient.withName('adolescent#001') sensor = CGMSensor.withName('Dexcom', seed=1) pump = InsulinPump.withName('Insulet') scenario = RandomScenario(start_time=start_time, seed=1) env = T1DSimEnv(patient, sensor, pump, scenario) # 创建控制器 controller = BBController() # 将它们组合在一起创建模拟对象 s1 = SimObj(env, controller, timedelta(days=1), animate=False, path=path) results1 = sim(s1) print(results1) # --------- 创建自定义场景 -------------- # 创建模拟环境 patient = T1DPatient.withName('adolescent#001') sensor = CGMSensor.withName('Dexcom', seed=1) pump = InsulinPump.withName('Insulet') # 自定义场景是一个元组列表 (时间, 餐量) scen = [(7, 45), (12, 70), (16, 15), (18, 80), (23, 10)] scenario = CustomScenario(start_time=start_time, scenario=scen) env = T1DSimEnv(patient, sensor, pump, scenario) # 创建控制器 controller = BBController() # 将它们组合在一起创建模拟对象 s2 = SimObj(env, controller, timedelta(days=1), animate=False, path=path) results2 = sim(s2) print(results2) # --------- 批量模拟 -------------- # 重新初始化模拟对象 s1.reset() s2.reset() # 创建SimObj列表,并调用batch_sim s = [s1, s2] results = batch_sim(s, parallel=True) print(results)
离线运行分析(example/offline_analysis.py):
from simglucose.analysis.report import report import pandas as pd from pathlib import Path # 获取example文件夹的路径 exmaple_pth = Path(__file__).parent # 查找所有符合 *#*.csv 模式的 csv 文件,例如 adolescent#001.csv result_filenames = list(exmaple_pth.glob( 'results/2017-12-31_17-46-32/*#*.csv')) patient_names = [f.stem for f in result_filenames] df = pd.concat( [pd.read_csv(str(f), index_col=0) for f in result_filenames], keys=patient_names) report(df)
发布说明
2023年8月20日
- 修复了风险指数计算的 numpy 兼容性问题(感谢 @yihuicai)
- 支持 Gymnasium。
- 注意:gymnasium 版本中的观察结果不再是带有 CGM 字段的命名元组。它是一个 numpy 数组(与其空间定义保持一致)。
- 注意:不再支持 Python 3.7 和 3.8 版本。请更新至 3.9 以上版本。
2021年3月10日
- 修复了一些随机种子问题。
2020年5月27日
- 在 simglucose/controller/pid_ctrller 中添加了 PIDController。在 examples/run_pid_controller.py 中有一个示例展示如何使用它。
2018年9月10日
- 控制器的
policy方法可以通过info['patient_state']访问当前患者的所有状态。
2018年2月26日
- 支持自定义奖励函数。
2018年1月10日
- 添加了在创建 gym 环境时选择患者的解决方法:通过传递 patient_name 的 kwargs 来注册 gym 环境。
2018年1月7日
- 添加了 OpenAI gym 支持,使用
gym.make('simglucose-v0')来创建环境。 - 注意问题:目前在 gym.make 中无法使用患者名称选择。患者名称必须在
simglucose.envs.T1DSimEnv的构造函数中硬编码。
报告问题
通过创建 issues 向我反馈任何 bug、改进建议,甚至是讨论。
如何贡献
以下说明最初来自 sklearn 的贡献指南。
贡献 simglucose 的首选工作流程是在 GitHub 上 fork 主仓库,克隆,并在分支上开发。步骤如下:
-
点击页面右上角附近的 "Fork" 按钮,fork 项目仓库。这会在你的 GitHub 账户下创建代码的副本。有关如何 fork 仓库的更多详细信息,请参阅此指南。
-
将你 fork 的 simglucose 仓库从你的 GitHub 账户克隆到本地磁盘:
$ git clone git@github.com:你的登录名/simglucose.git $ cd simglucose -
创建一个
feature分支来保存你的开发更改:$ git checkout -b my-feature始终使用
feature分支。永远不要在master分支上工作是一个好习惯! -
在你的 feature 分支上开发功能。使用
git add添加更改的文件,然后git commit提交文件:$ git add 修改的文件 $ git commit在 Git 中记录你的更改,然后使用以下命令将更改推送到你的 GitHub 账户:
$ git push -u origin my-feature -
按照这些说明从你的 fork 创建一个拉取请求。这将通知贡献者。
(如果以上任何内容对你来说像魔法一样,请查阅网上的 Git 文档,或向朋友或其他贡献者寻求帮助。)
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页�应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付��速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号