



:no_entry: [已弃用] 知识蒸馏工具包
论文"缩小大脚怪:减少wav2vec 2.0的占用空间"的代码
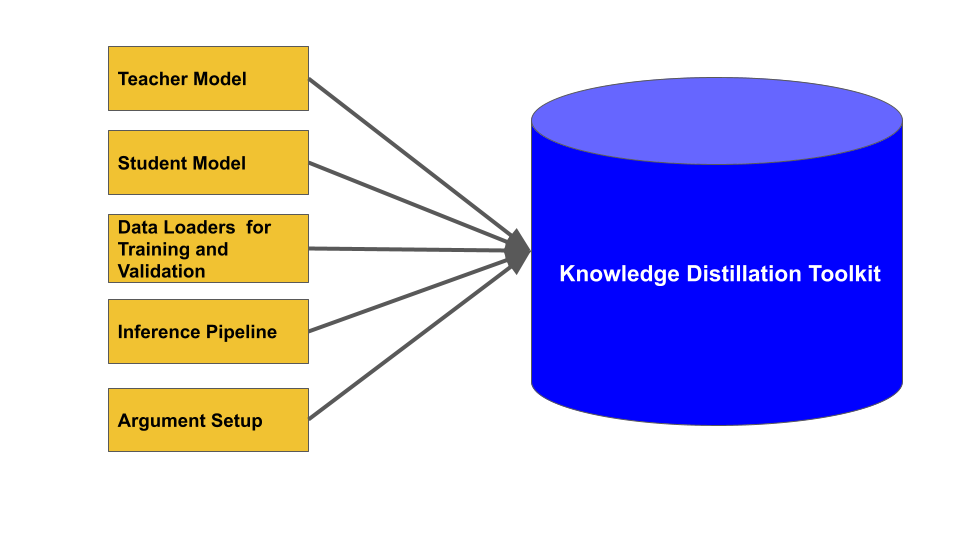
这个工具包允许你使用知识蒸馏来压缩机器学习模型。要使用这个工具包,你需要提供一个教师模型、一个学生模型、用于训练和验证的数据加载器,以及一个推理流程。这个工具包基于PyTorch和PyTorch Lightning,因此教师和学生模型需要是PyTorch神经网络模块,数据加载器需要是PyTorch数据加载器。
<a name="demo"></a> 演示
我们提供了两个使用此工具包并压缩机器学习模型的演示。在这些演示中,我们展示了如何创建学生和教师模型、推理流程、训练和验证数据加载器,并将它们传递到知识蒸馏工具包中。
压缩resnet: 
压缩wav2vec 2.0: 此笔记本
<a name="usage"></a>用法
定义推理流程
class InferencePipeline:
def __init__(self):
# 如有必要进行设置
def run_inference_pipeline(self, model, data_loader):
# 获取模型在验证数据集上的准确率
return {"inference_result": accuracy}
具体示例请参见此处。
定义学生模型
import torch.nn as nn
class StudentModel(nn.Module):
def forward(self, ):
# 学生模型的前向传播
具体示例请参见此处。
定义教师模型
import torch.nn as nn
class TeacherModel(nn.Module):
def forward(self, ):
# 教师模型的前向传播
具体示例请参见此处。
将所有内容整合在一起并开始知识蒸馏
import torch
inference_pipeline = InferencePipeline()
student_model = StudentModel()
teacher_model = TeacherModel()
train_data_loader = torch.utils.data.DataLoader(train_dataset)
val_data_loaders = {"一个验证数据集": torch.utils.data.DataLoader(val_dataset)}
KD_example = KnowledgeDistillationTraining(train_data_loader = train_data_loader,
val_data_loaders = val_data_loaders,
inference_pipeline = inference_pipeline,
student_model = student_model,
teacher_model = teacher_model)
KD_example.start_kd_training()
<a name="kd_train"></a> 开始知识蒸馏训练!
要开始知识蒸馏训练,你需要先实例化KnowledgeDistillationTraining类,然后调用start_kd_training方法。
在下表中,我们展示了KnowledgeDistillationTraining类的构造函数接受的参数。
| 参数名称 | 类型 | 说明 | 默认值 |
|---|---|---|---|
teacher_model | torch.nn.Module | 教师模型 | None |
student_model | torch.nn.Module | 学生模型 | None |
train_data_loader | torch.utils.data.DataLoader | 训练数据集的数据加载器 | None |
val_data_loaders | dict | 包含多个验证数据加载器的字典。键应为数据加载器的名称,值为数据加载器。注意,数据加载器应为torch.utils.data.DataLoader的实例 | None |
inference_pipeline | object | 返回验证结果的Python类。有关此类的更多信息,请参见下文 | None |
num_gpu_used | int | 用于训练的GPU数量 | 0 |
max_epoch | int | 训练轮数 | 10 |
optimize_method | str | 用于训练学生模型的优化方法。可以是["adam", "sgd", "adam_wav2vec2.0", "adam_distilBert", "adamW_distilBert"]之一 | "adam" |
scheduler_method | str | 学习率调度器。可以是["", "linear_decay_with_warm_up", "cosine_anneal"]之一。如果设置为""则不使用学习率调度 | "" |
learning_rate | float | 知识蒸馏训练的学习率 | 0.0001 |
num_lr_warm_up_epoch | int | 预热(增加)学习率的轮数。如果不预热学习率,则设置为0 | 0 |
final_loss_coeff_dict | dict | 包含应与损失相乘的系数的字典。更多信息请参见下文 | {"kd_loss":1} |
log_to_comet | bool | 如果将实验结果记录到comet.ml,则设置为True。如果调试,请将其设置为False | False |
comet_info_path | str | 包含comet.ml的API密钥、项目名称和工作空间的txt文件路径 | "" |
comet_exp_name | str | comet.ml上的实验名称 | "" |
temperature | int | 计算知识蒸馏损失的温度 | 1 |
seed | int | 实验的种子值 | 32 |
track_grad_norm | int | 计算梯度时用于跟踪的范数 | 2 |
accumulate_grad_batches | int | 梯度累积步数 | 1 |
accelerator | str/None | PyTorch Lightning的加速器。详情请参见此处 | None |
num_nodes | int | 计算节点数 | 1 |
precision | int | 16位或32位训练。详情请参见此处 | 16 |
deterministic | bool | PyTorch Lightning中的deterministic标志 | True |
resume_from_checkpoint | str | 当前实验应从中恢复的先前检查点路径 | "" |
logging_param | dict | 包含应保存到comet.ml的参数的字典 | None |
推理流水线如何工作?
该工具包使用推理流水线来测试学生模型。inference_pipeline类需要实现run_inference_pipeline方法。此方法的目的是获取学生模型在验证数据集上的性能。
我们通过以下代码示例来说明如何创建推理流水线。我们将model和data_loader传递给run_inference_pipeline。model是student_model,data_loader是验证数据加载器。在使用此工具包时,你应该已经准备好这两个参数,因为你需要它们来实例化KnowledgeDistillationTraining类。在run_inference_pipeline中,我们从data_loader中获取每个数据样本,然后将其传递给model。对于��每个数据样本,我们根据学生模型的预测和真实标签计算准确率。最后,我们计算总体accuracy并将其作为字典返回。在返回的字典中,inference_result应该对应总体准确率。
class inference_pipeline:
def __init__(self):
# 构造方法是可选的
def run_inference_pipeline(self, model, data_loader):
accuracy = 0
model.eval()
with torch.no_grad():
for i, data in enumerate(data_loader):
X, y = data[0].to(self.device), data[1].to(self.device)
outputs = model(X)
predicted = torch.max(outputs["prob"], 1)[1]
accuracy += predicted.eq(y.view_as(predicted)).sum().item()
accuracy = accuracy / len(data_loader.dataset)
return {"inference_result": accuracy}
上面的代码只是一个示例,你可以按照自己的方式创建推理流水线。只需记住两个规则:
-
inference_pipeline类只需要实现run_inference_pipeline。run_inference_pipeline在验证数据集上测试学生模型。 -
run_inference_pipeline应返回一个字典,例如{"inference_result": 衡量学生模型在验证数据集上性能的数值}。
损失函数如何工作?
在进行知识蒸馏训练时,我们需要计算损失函数。我们总是有一个知识蒸馏损失,它是教师模型和学生模型概率分布之间的KL散度。通常还会在损失函数中添加一个有监督训练损失。例如,如果学生模型是图像分类网络,有监督训练损失可以是交叉熵损失。最终的损失函数会结合不同的损失,这样我们就可以使用最终损失计算梯度并更新学生模型(显然,我们不会手动执行这个过程,PyTorch��会自动为我们完成)。
这个工具包如何结合不同的损失(例如知识蒸馏损失、监督训练损失等)并形成最终损失?我们从final_loss_coeff_dict中获取系数,并将它们与final_loss_components中的损失相乘。final_loss_coeff_dict和final_loss_components都是字典,这两个字典中的键必须匹配,这样我们才知道如何将系数与损失对应起来。例如,final_loss_components总是包含"kd_loss"(知识蒸馏损失的键),所以final_loss_coeff_dict中必须有一个"kd_loss"键。使用这个工具包时,用户需要提供final_loss_coeff_dict,但不需要提供final_loss_components,因为我们内部会形成这个字典。如果你还想将监督训练损失(学生损失)添加到最终损失中,可以在学生模型的前向传播结束时返回它。具体示例可以参考这里。
编辑推荐精选


Pixmax
一站式AI短剧创作平台
Pixmax专注打造下一代“ AI 视觉创作引擎”,整合行业顶尖 AI 大模型、工工业级精准控制及企业级协同管理功能,是全方位的 AI 内容创作平台。


豆包
��字节跳动旗下 AI 智能助手
字节跳动旗下 AI 智能助手


GPT Plus|Pro充值
GPT充值
支持 ChatGPT Plus / Pro 充值服务,支付便捷,自动发货,售后可查。


GPT Image 2中文站
AI 图片生成平台
GPT Image 2 是面向用户的 AI 图片生成平台,支持文生图、图生图及多模型创意工作流。


Vecbase
你的AI Agent团队
Vecbase 是专为 AI 团队打造的智能工作空间,将数据管理、模型协作与知识沉淀整合于一处。算法、产品与业务在同一平台无缝协同,让从数据到 AI 应用的落地更快一步。


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


QoderWork
阿里Qoder团队推出的桌面端AI智能体
QoderWork 是阿里推出的本地优先桌面 AI 智能体,适配 macOS14+/Windows10+,以自然语言交互实现文件管理、数据分析、AI 视觉生成、浏览器自动化等办公任务,自主拆解执行复杂工作流,数据本地运行零上传,技能市场可无限扩展,是高效的 Agentic 生产力办公助手。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。


seedancetwo2.0
能听懂你表达的视频模型
Seedance two是基于seedance2.0的中国大模型,支持图像、视频、音频、文本四种模态输入,表达方式更丰富,生成也更可控。
推荐工具精选






AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号