
segment-anything-2
新一代图像和视频分割基础模型
SAM 2是Meta AI研发的图像和视频分割基础模型,扩展了SAM的功能。它采用transformer架构和流式内存,实现实时视频处理。通过模型循环数据引擎,研究团队构建了大规模视频分割数据集SA-V。SAM 2在多种视觉任务中展现出卓越性能,为计算机视觉领域带来新的可能。




SAM 2: 图像和视频中的任意分割
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollár, Christoph Feichtenhofer
[论文] [项目] [演示] [数据集] [博客] [引用]
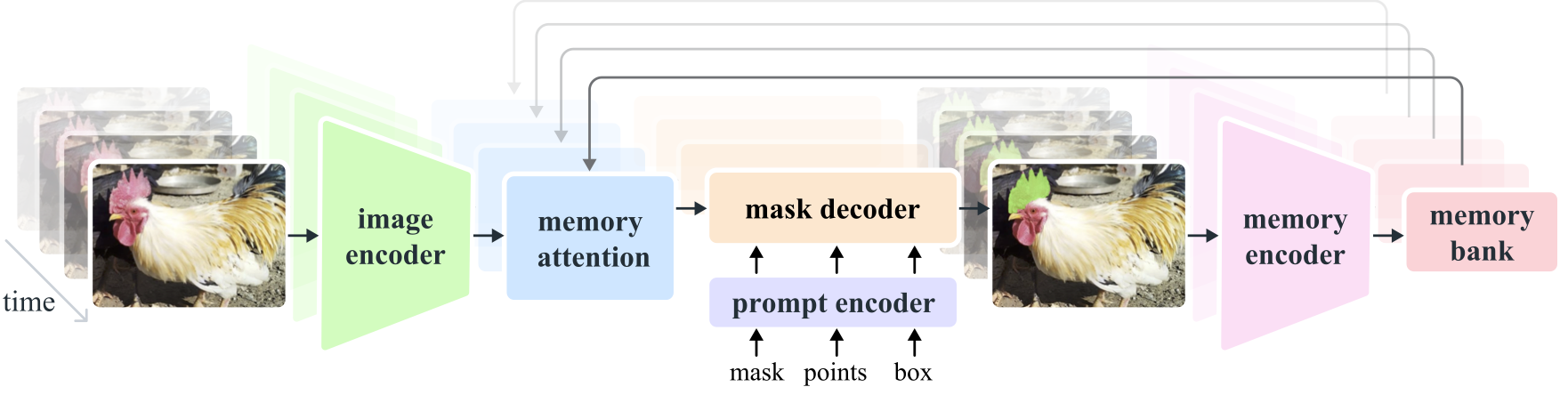
Segment Anything Model 2 (SAM 2) 是一个基础模型,旨在解决图像和视频中的可提示视觉分割问题。我们通过将图像视为单帧视频来将SAM扩展到视频。模型设计是一个简单的transformer架构,具有用于实时视频处理的流式内存。我们构建了一个模型在环的数据引擎,通过用户交互来改进模型和数据,以收集我们的SA-V数据集,这是迄今为止最大的视频分割数据集。在我们的数据上训练的SAM 2在广泛的任务和视觉领域中表现出色。

安装
使用前需要先安装SAM 2。代码要求python>=3.10,以及torch>=2.3.1和torchvision>=0.18.1。请按照这里的说明安装PyTorch和TorchVision依赖项。您可以在GPU机器上使用以下命令安装SAM 2:
git clone https://github.com/facebookresearch/segment-anything-2.git cd segment-anything-2 & pip install -e .
如果您在Windows上安装,强烈建议使用Windows Subsystem for Linux (WSL)和Ubuntu。
要使用SAM 2预测器并运行示例笔记本,需要jupyter和matplotlib,可以通过以下命令安装:
pip install -e ".[demo]"
注意:
- 建议通过Anaconda为此安装创建一个新的Python环境,并按照https://pytorch.org/的说明通过`pip`安装PyTorch 2.3.1(或更高版本)。如果您当前环境中的PyTorch版本低于2.3.1,上述安装命令将尝试使用
pip将其升级到最新的PyTorch版本。 - 上述步骤需要使用
nvcc编译器编译自定义CUDA内核。如果您的机器上还没有该编译器,请安装与您的PyTorch CUDA版本匹配的CUDA工具包。 - 如果在安装过程中看到类似
Failed to build the SAM 2 CUDA extension的消息,您可以忽略它并仍然使用SAM 2(某些后处理功能可能会受限,但在大多数情况下不会影响结果)。
请参阅INSTALL.md了解潜在问题和解决方案的常见问题解答。
入门
下载检查点
首先,我们需要下载模型检查点。可以通过运行以下命令下载所有模型检查点:
cd checkpoints && \ ./download_ckpts.sh && \ cd ..
或单独从以下链接下载:
然后可以通过几行代码使用SAM 2进行图像和视频预测。
图像预测
SAM 2在静态图像上具有SAM的所有功能,我们为图像用例提供了与SAM非常相似的图像预测API。SAM2ImagePredictor类提供了一个简单的图像提示接口。
import torch from sam2.build_sam import build_sam2 from sam2.sam2_image_predictor import SAM2ImagePredictor checkpoint = "./checkpoints/sam2_hiera_large.pt" model_cfg = "sam2_hiera_l.yaml" predictor = SAM2ImagePredictor(build_sam2(model_cfg, checkpoint)) with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16): predictor.set_image(<your_image>) masks, _, _ = predictor.predict(<input_prompts>)
请参考image_predictor_example.ipynb(也可在Colab这里找到)中的示例,了解静态图像用例。
SAM 2还支持像SAM一样在图像上自动生成蒙版。请参阅automatic_mask_generator_example.ipynb(也可在Colab这里找到)了解图像中的自动蒙版生成。
视频预测
对于视频中的可提示分割和跟踪,我们提供了一个视频预测器,其API可以添加提示并在整个视频中传播小蒙版。SAM 2支持对多个对象进行视频推理,并使用推理状态来跟踪每个视频中的交互。
import torch from sam2.build_sam import build_sam2_video_predictor checkpoint = "./checkpoints/sam2_hiera_large.pt" model_cfg = "sam2_hiera_l.yaml" predictor = build_sam2_video_predictor(model_cfg, checkpoint) with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16): state = predictor.init_state(<your_video>) # 添加新提示并立即在同一帧上获得输出 frame_idx, object_ids, masks = predictor.add_new_points_or_box(state, <your_prompts>): # 传播提示以获取整个视频中的小蒙版 for frame_idx, object_ids, masks in predictor.propagate_in_video(state): ...
请参考video_predictor_example.ipynb(也可在Colab这里找到)中的示例,了解如何添加点击或框提示、进行细化以及在视频中跟踪多个对象的详细信息。
从🤗 Hugging Face加载
或者,也可以从Hugging Face加载模型(需要pip install huggingface_hub)。
对于图像预测:
import torch from sam2.sam2_image_predictor import SAM2ImagePredictor predictor = SAM2ImagePredictor.from_pretrained("facebook/sam2-hiera-large") 使用 torch.inference_mode() 和 torch.autocast("cuda", dtype=torch.bfloat16): predictor.set_image(<你的图像>) masks, _, _ = predictor.predict(<输入提示>) 对于视频预测: import torch from sam2.sam2_video_predictor import SAM2VideoPredictor predictor = SAM2VideoPredictor.from_pretrained("facebook/sam2-hiera-large") 使用 torch.inference_mode() 和 torch.autocast("cuda", dtype=torch.bfloat16): state = predictor.init_state(<你的视频>) # 添加新提示并立即获取同一帧的输出 frame_idx, object_ids, masks = predictor.add_new_points_or_box(state, <你的提示>): # 在视频中传播提示以获得整个视频的掩模 for frame_idx, object_ids, masks in predictor.propagate_in_video(state): ... 模型描述 | 模型 | 大小 (M) | 速度 (FPS) | SA-V 测试 (J&F) | MOSE 验证 (J&F) | LVOS v2 (J&F) | | :-------------: | :------: | :---------------: | :-------------: | :-------------: | :-----------: | | sam2_hiera_tiny | 38.9 | 47.2 | 75.0 | 70.9 | 75.3 | | sam2_hiera_small| 46 | 43.3 (53.0 编译*) | 74.9 | 71.5 | 76.4 | |sam2_hiera_base_plus| 80.8 | 34.8 (43.8 编译*) | 74.7 | 72.8 | 75.8 | | sam2_hiera_large| 224.4 | 24.2 (30.2 编译*) | 76.0 | 74.6 | 79.8 | * 通过在配置中设置 `compile_image_encoder: True` 来编译模型。 分割任何视频数据集 有关详细信息,请参阅 sav_dataset/README.md。 许可证 这些模型根据 Apache 2.0 许可证授权。有关模型的更多详细信息,请参阅我们的研究论文。 贡献 请参阅贡献指南和行为准则。 贡献者 SAM 2 项目得以实现离不开众多贡献者的帮助(按字母顺序排列): Karen Bergan, Daniel Bolya, Alex Bosenberg, Kai Brown, Vispi Cassod, Christopher Chedeau, Ida Cheng, Luc Dahlin, Shoubhik Debnath, Rene Martinez Doehner, Grant Gardner, Sahir Gomez, Rishi Godugu, Baishan Guo, Caleb Ho, Andrew Huang, Somya Jain, Bob Kamma, Amanda Kallet, Jake Kinney, Alexander Kirillov, Shiva Koduvayur, Devansh Kukreja, Robert Kuo, Aohan Lin, Parth Malani, Jitendra Malik, Mallika Malhotra, Miguel Martin, Alexander Miller, Sasha Mitts, William Ngan, George Orlin, Joelle Pineau, Kate Saenko, Rodrick Shepard, Azita Shokrpour, David Soofian, Jonathan Torres, Jenny Truong, Sagar Vaze, Meng Wang, Claudette Ward, Pengchuan Zhang. 第三方代码:我们使用了改编自 cc_torch 的基于 GPU 的连通分量算法(其许可证在 LICENSE_cctorch 中),作为掩模预测的可选后处理步骤。 引用 SAM 2 如果您在研究中使用 SAM 2 或 SA-V 数据集,请使用以下 BibTeX 条目。 @article{ravi2024sam2, title={SAM 2: Segment Anything in Images and Videos}, author={Ravi, Nikhila and Gabeur, Valentin and Hu, Yuan-Ting and Hu, Ronghang and Ryali, Chaitanya and Ma, Tengyu and Khedr, Haitham and R{\"a}dle, Roman and Rolland, Chloe and Gustafson, Laura and Mintun, Eric and Pan, Junting and Alwala, Kalyan Vasudev and Carion, Nicolas and Wu, Chao-Yuan and Girshick, Ross and Doll{\'a}r, Piotr and Feichtenhofer, Christoph}, journal={arXiv preprint arXiv:2408.00714}, url={https://arxiv.org/abs/2408.00714}, year={2024} }
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号