
SeeSR
基于语义感知的实景图像超分辨率方法
SeeSR是一种新型语义感知实景图像超分辨率技术,结合稳定扩散模型和语义信息提升低分辨率图像质量。该方法已被CVPR2024接收并在GitHub开源。SeeSR可处理多种场景图像,并支持快速推理。项目提供预训练模型、测试数据集和使用说明,便于研究和应用。此外,项目还包含DAPE和SeeSR模型的训练指南,以及用于生成训练数据的工具。SeeSR采用tiled vae方法节省GPU内存,并提供Gradio演示界面。该技术在多个真实世界图像数据集上展现出优异性能。




SeeSR:面向语义感知的真实世界图像超分辨率(CVPR2024)
<a href='https://arxiv.org/abs/2311.16518'><img src='https://yellow-cdn.veclightyear.com/0a4dffa0/8dcd71d0-38f8-47dc-8cbe-ba4892addaf3.svg'></a> <a href='https://replicate.com/lucataco/seesr'><img src='https://replicate.com/lucataco/seesr/badge'></a>
吴荣源<sup>1,2</sup> | 杨涛<sup>3</sup> | 孙凌晨<sup>1,2</sup> | 张政强<sup>1,2</sup> | 李帅<sup>1,2</sup> | 张磊<sup>1,2</sup>
<sup>1</sup>香港理工大学, <sup>2</sup>OPPO研究院, <sup>3</sup>字节跳动
:star: 如果SeeSR对您的图像或项目有帮助,请给这个仓库点个星。谢谢!:hugs:
🚩已被CVPR2024接收
📢 新闻
- 2024.06 我们的一步式真实世界图像超分辨率工作OSEDiff,可达到SeeSR级别的质量,但速度快10倍以上。
- 2024.03.10 支持sd-turbo,SeeSR只需2步就能得到不错的图像⚡️。请参考这里。
- 2024.01.12 🔥🔥🔥 已集成到 <a href='https://replicate.com/lucataco/seesr'><img src='https://replicate.com/lucataco/seesr/badge'></a> 试用<u>Replicate</u>在线演示 ❤️ 感谢lucataco的实现。
- 2024.01.09 🚀 添加Gradio演示,包括turbo模式。
- 2023.12.25 🎅🎄🎅🎄 圣诞快乐!!!
- 🍺 发布SeeSR-SD2-Base,包括代码和预训练模型。
- 📏 我们还发布了
RealLR200。它包含200张真实世界的低分辨率图像。
- 2023.11.28 创建此仓库。
📌 待办事项
- SeeSR-SDXL
- SeeSR-SD2-Base-face,text
-
SeeSR加速
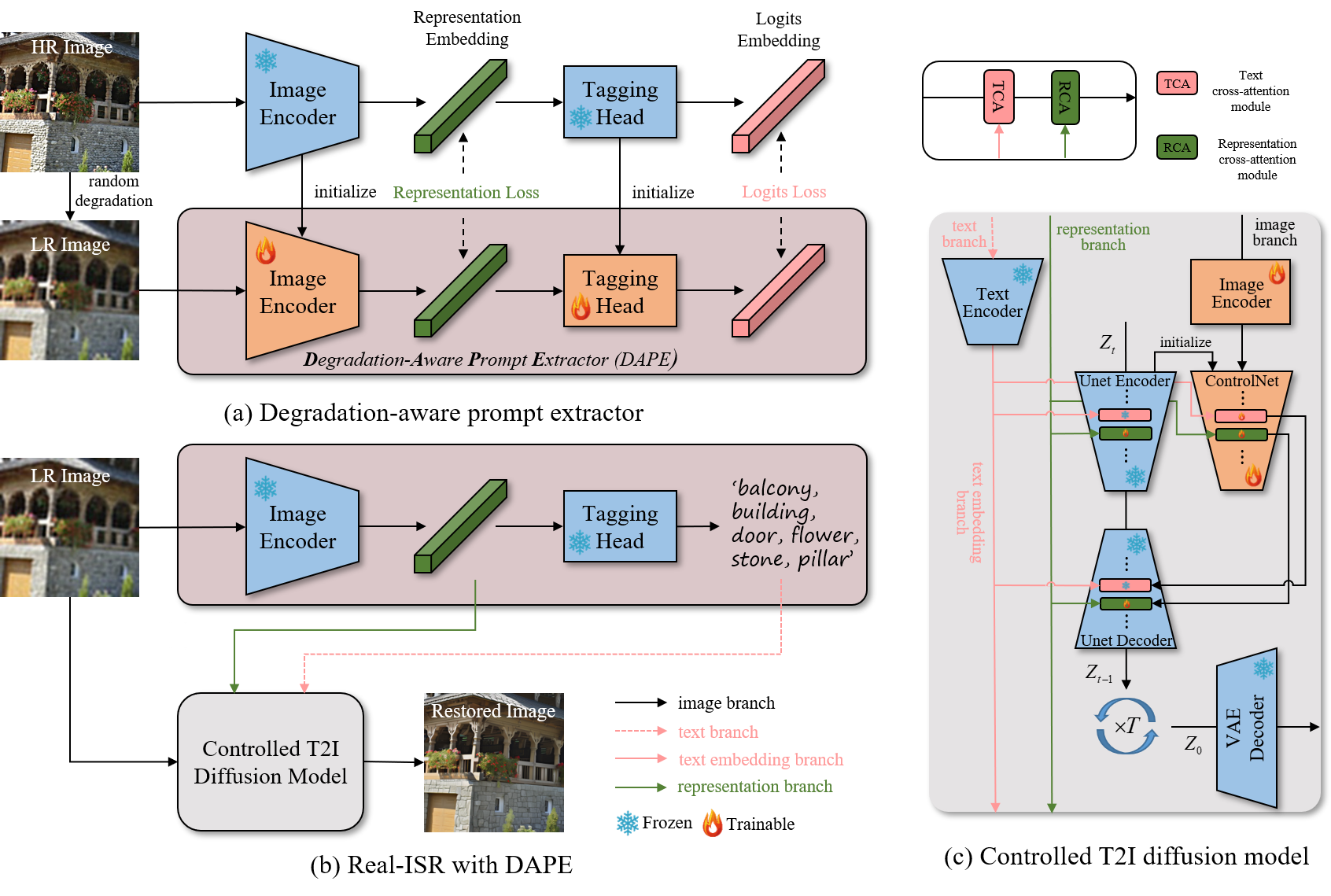
🔎 总体框架
📷 真实世界结果
<img src="https://yellow-cdn.veclightyear.com/0a4dffa0/172ff6e6-89b3-4603-867c-30e5c83ce902.png" height="320px"/> <img src="https://yellow-cdn.veclightyear.com/0a4dffa0/bb3c79cb-b414-4007-8373-23ba4224b8d8.png" height="320px"/> <img src="https://yellow-cdn.veclightyear.com/0a4dffa0/3514b1ff-de6f-4c50-8a6a-2d3eb76ec041.png" height="320px"/> <img src="https://yellow-cdn.veclightyear.com/0a4dffa0/59aadec8-8fbd-46da-bf23-f941558a58ca.png" height="320px"/>

⚙️ 依赖项和安装
## 克隆此仓库
git clone https://github.com/cswry/SeeSR.git
cd SeeSR
# 创建一个Python版本 >= 3.8的环境
conda create -n seesr python=3.8
conda activate seesr
pip install -r requirements.txt
🚀 快速推理
步骤1:下载预训练模型
- 从HuggingFace下载预训练的SD-2-base模型。
- 从GoogleDrive或OneDrive下载SeeSR和DAPE模型。
您可以将模型放入preset/models目录。
步骤2:准备测试数据
您可以将测试图像放入preset/datasets/test_datasets目录。
步骤3:运行测试命令
python test_seesr.py \
--pretrained_model_path preset/models/stable-diffusion-2-base \
--prompt '' \
--seesr_model_path preset/models/seesr \
--ram_ft_path preset/models/DAPE.pth \
--image_path preset/datasets/test_datasets \
--output_dir preset/datasets/output \
--start_point lr \
--num_inference_steps 50 \
--guidance_scale 5.5 \
--process_size 512
更多详情请参阅此处
SD-Turbo步骤
��只需从sd-turbo下载权重,并将它们放入preset/models。然后,您就可以运行命令了。更多比较可以在这里找到。请注意,在turbo模式下,guidance_scale固定为1.0。
python test_seesr_turbo.py \
--pretrained_model_path preset/models/sd-turbo \
--prompt '' \
--seesr_model_path preset/models/seesr \
--ram_ft_path preset/models/DAPE.pth \
--image_path preset/datasets/test_datasets \
--output_dir preset/datasets/output \
--start_point lr \
--num_inference_steps 2 \
--guidance_scale 1.0 \
--process_size 512
<img src="https://yellow-cdn.veclightyear.com/0a4dffa0/c7ab149e-c358-4b4b-9bde-1aaefbccc185.png" height="350px"/> <img src="https://yellow-cdn.veclightyear.com/0a4dffa0/2353deeb-c4d0-4ca5-bd5f-243d6719673f.png" height="350px"/>
注意
请仔细阅读test_seesr.py中的参数。我们采用了multidiffusion-upscaler-for-automatic1111提出的平铺VAE方法来节省GPU内存。
Gradio演示
请将所有预训练模型放在preset/models目录下,然后运行以下命令以与gradio网站交互。
python gradio_seesr.py
我们还提供了带有sd-turbo的gradio,祝您使用愉快。🤗
python gradio_seesr_turbo.py
测试基准
我们在GoogleDrive和OneDrive上发布了我们的RealLR200。您可以从StableSR下载RealSR和DRealSR。我们还在GoogleDrive和OneDrive上提供了其副本。至于合成测试集,您可以通过下面描述的合成方法获得。
🌈 训练
步骤1:下载预训练模型
下载预训练的SD-2-base模型和RAM。您可以将它们放入preset/models目录。
步骤2:准备训练数据
我们为训练过程预先准备训练数据对,这会占用一些内存空间但可以节省训练时间。我们使用COCO数据集训练DAPE,使用常见的低级数据集(如DF2K)训练SeeSR。
要为DAPE训练制作配对数据,可以运行:
python utils_data/make_paired_data_DAPE.py \
--gt_path 路径_1 路径_2 ... \
--save_dir preset/datasets/train_datasets/training_for_dape \
--epoch 1
要为SeeSR训练制作配对数据,可以运行:
python utils_data/make_paired_data.py \
--gt_path 路径_1 路径_2 ... \
--save_dir preset/datasets/train_datasets/training_for_dape \
--epoch 1
--gt_path高清图像的路径。如果有多个高清图像目录,可以设置为路径1 路径2 路径3 ...--save_dir配对图像的保存路径--epoch你想要制作的轮次数
make_paired_data_DAPE.py和make_paired_data.py的区别在于,make_paired_data_DAPE.py将整个图像调整为512的分辨率,而make_paired_data.py随机裁剪出512分辨率的子图像。
一旦创建了降质数据对,你可以基于它们通过运行utils_data/make_tags.py来生成标签数据。
数据文件夹应该如下所示:
your_training_datasets/
└── gt
└── 0000001.png # 高清图像,(512, 512, 3)
└── ...
└── lr
└── 0000001.png # 低分辨率图像,(512, 512, 3)
└── ...
└── tag
└── 0000001.txt # 标签提示
└── ...
步骤3:训练DAPE
请在basicsr/options/dape.yaml的第13行指定DAPE训练数据路径,然后运行训练命令:
python basicsr/train.py -opt basicsr/options/dape.yaml
你可以修改dape.yaml中的参数以适应你的具体情况,比如GPU数量、批量大小、优化器选择等。更多细节请参考Basicsr中的设置。
步骤4:训练SeeSR
CUDA_VISIBLE_DEVICES="0,1,2,3,4,5,6,7," accelerate launch train_seesr.py \
--pretrained_model_name_or_path="preset/models/stable-diffusion-2-base" \
--output_dir="./experience/seesr" \
--root_folders 'preset/datasets/training_datasets' \
--ram_ft_path 'preset/models/DAPE.pth' \
--enable_xformers_memory_efficient_attention \
--mixed_precision="fp16" \
--resolution=512 \
--learning_rate=5e-5 \
--train_batch_size=2 \
--gradient_accumulation_steps=2 \
--null_text_ratio=0.5
--dataloader_num_workers=0 \
--checkpointing_steps=10000
--pretrained_model_name_or_path步骤1中预训练SD模型的路径--root_folders步骤2中训练数据集的路径--ram_ft_path步骤3中DAPE模型的路径
总批量大小由CUDA_VISIBLE_DEVICES、--train_batch_size和--gradient_accumulation_steps共同决定。如果你的GPU内存有限,可以考虑减小--train_batch_size并增加--gradient_accumulation_steps。
❤️ 致谢
本项目基于diffusers和BasicSR。部分代码来自PASD和RAM。感谢他们出色的工作。我们也向StableSR的开创性工作致敬。
📧 联系方式
如果你有任何问题,请随时联系:rong-yuan.wu@connect.polyu.hk
🎓引用
如果我们的代码对你的研究或工作有帮助,请考虑引用我们的论文。 以下是BibTeX引用:
@inproceedings{wu2024seesr,
title={Seesr: Towards semantics-aware real-world image super-resolution},
author={Wu, Rongyuan and Yang, Tao and Sun, Lingchen and Zhang, Zhengqiang and Li, Shuai and Zhang, Lei},
booktitle={Proceedings of the IEEE/CVF conference on computer vision and pattern recognition},
pages={25456--25467},
year={2024}
}
🎫 许可证
本项目在Apache 2.0许可证下发布。
<details> <summary>统计数据</summary>编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦��深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号