



通过冻结双向语言模型实现零样本视频问答
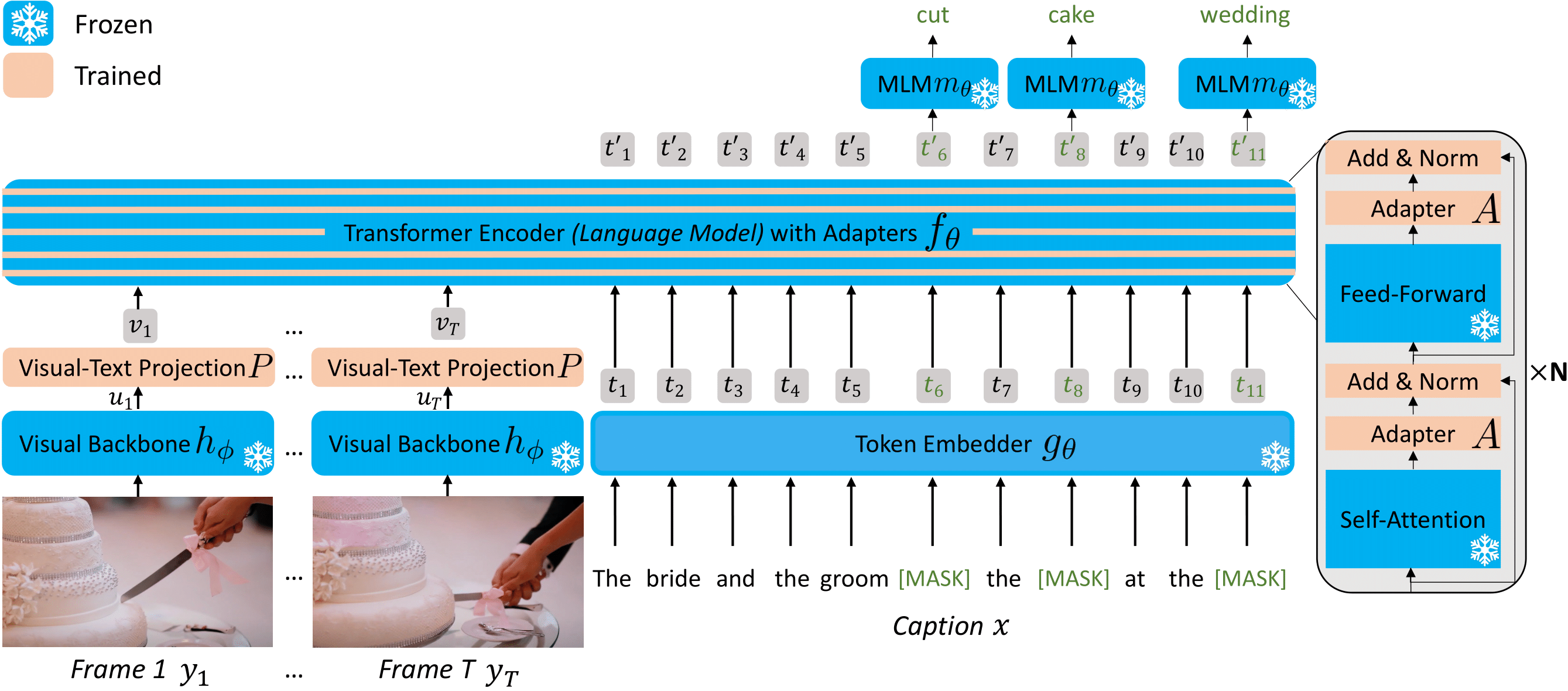
FrozenBiLM是一种新的视频问答模型,基于冻结的双向语言模型构建。FrozenBiLM在无需手动标注(零样本)或有限训练数据(少样本)的情况下表现出色,同时在标准数据集上训练时(全监督)也具有竞争力。
本代码库提供了我们FrozenBiLM论文(NeurIPS 2022)的代码,包括:
- 环境设置
- 数据下载说明
- 数据预处理和视觉特征提取脚本,以及预处理后的数据和特征
- 预训练检查点
- 跨模态训练、下游全监督、少样本和零样本视频问答的训练和评估脚本,包括各种基线模型
- 视频问答演示脚本
设置
要安装所需依赖,请运行:
conda create -n frozenbilm_env python=3.8
conda activate frozenbilm_env
conda install pytorch==1.8.1 torchvision==0.9.1 cudatoolkit=11.1 -c pytorch -c nvidia
pip install -r requirements.txt
您可以在args.py中填写全局路径。
要使用给定的预训练文本语言模型,您应该从Hugging Face Hub下载相应的权重并将它们放在TRANSFORMERS_CACHE中。
快速开始
如果您希望快速开始视频问答训练或推理。
下载预处理数据、视觉特征和检查点
要下载预训练检查点、预处理数据、ASR和视觉特征,请运行:
bash download/download_checkpoints.sh <MODEL_DIR>
bash download/download_downstream.sh <DATA_DIR>
如果您在使用gshell时遇到问题,可以在这里访问处理过的数据,在这里访问检查点。
模型大约需要8GB,数据需要12GB。
请注意,由于存储限制,大多数预训练检查点仅包含更新后的参数(而不包含冻结的参数)。
这意味着在使用提供的检查点时,您需要确保已正确从Hugging Face下载了所选语言模型的权重。
为了完整性,frozenbilm.pth、frozenbilm_bertbase_noadapter.pth和frozenbilm_bertlarge_noadapter.pth包含所有参数。
另外请注意,由于存储问题,我们不公开托管WebVid10M数据集的视觉特征。
详细说明
数据下载
<details> <summary>点击查看详情... </summary> **WebVid10M** 从[数据集提供者](https://m-bain.github.io/webvid-dataset/)下载注释和视频。 注释应位于`<DATA_DIR>/WebVid`。LSMDC-FiB 从数据集提供者下载注释和视频。
注释应位于<DATA_DIR>/LSMDC。
TGIF-FrameQA 从数据集提供者下载注释和GIF。
注释应位于<DATA_DIR>/TGIF-QA。
How2QA 从数据集提供者下载注释和视频。
注释应位于<DATA_DIR>/How2QA。
TVQA 从数据集提供者下载注释和视频。
注释应位于<DATA_DIR>/TVQA。
对于iVQA、MSRVTT-QA、MSVD-QA和ActivityNet-QA,我们使用Just Ask的预处理文件,并将�它们下载到<DATA_DIR>/iVQA、<DATA_DIR>/MSRVTT-QA、<DATA_DIR>/MSVD-QA和<DATA_DIR>/ActivityNet-QA。
要下载自动语音字幕,我们使用youtube-dl,除了LSMDC、How2QA和TVQA,这些数据集的作者提供了字幕。
然后,我们将数据集中每个视频的vtt文件转换为一个pickle文件subtitles.pkl,其中包含一个字典,将每个video_id映射到一个包含start、end和text键的字典,对应于相应video_id中的语音。
注释预处理
<details> <summary>点击查看详情... </summary> 要对不同数据集的注释进行预处理,请运行: ``` python preproc/preproc_webvid.py python preproc/preproc_lsmdc.py python preproc/preproc_tgifqa.py python preproc/preproc_how2qa.py python preproc/preproc_tvqa.py ``` iVQA、MSRVTT-QA、MSVD-QA和ActivityNet-QA已经预处理完成(参见数据下载说明)。 </details>视觉特征提取
<details> <summary>点击查看详情... </summary> 我们在`extract`文件夹中提供了使用CLIP ViT-L/14@224px从视频中提取视觉特征的代码。 这需要下载[此仓库](https://github.com/openai/CLIP)中提供的预训练权重。 **提取** 对于每个数据集,您应该准备一个包含 `video_path` 和 `feature_path` 列的csv文件。然后使用以下命令(您可以在多个GPU上启动此脚本以加快提取过程): ``` python extract/extract.py --csv <csv路径> ```合并文件 要将提取的特征合并为每个下游数据集的单个文件,请使用:
python extract/merge_features.py --folder <特征路径> \
--output_path <默认数据集目录>/clipvitl14.pth --dataset <数据集>
对于WebVid10M,您可以将特征保留在单独的文件中(每个视频一个文件),因为数据集太大,无法将特征存储在单个文件中。 最好将这些特征放在SSD上,以加快训练期间的实时读取速度。
可用的检查点
| 训练数据 | LSMDC | iVQA | MSRVTT-QA | MSVD-QA | ActivityNet-QA | TGIF-QA | How2QA | TVQA | 链接 | 大小 |
|---|---|---|---|---|---|---|---|---|---|---|
| WebVid10M | 51.5 | 26.8 | 16.7 | 33.8 | 25.9 | 41.9 | 58.4 | 59.7 | Drive | 3.7GB(包括冻结权重) |
| WebVid10M + LSMDC | 63.5 | Drive | 114MB | |||||||
| WebVid10M + iVQA | 39.6 | Drive | 114MB | |||||||
| WebVid10M + MSRVTT-QA | 47.0 | Drive | 114MB | |||||||
| WebVid10M + MSVD-QA | 54.8 | Drive | 114MB | |||||||
| WebVid10M + ActivityNet-QA | 43.2 | Drive | 114MB | |||||||
| WebVid10M + TGIF-QA | 68.6 | Drive | 114MB | |||||||
| WebVid10M + How2QA | 86.3 | Drive | 114MB | |||||||
| WebVid10M + TVQA | 82.0 | Drive | 114MB |
请注意,在下游数据集的10%或1%上微调的检查点(少样本设置)也可以在这里访问。 使用BERT-Base或BERT-Large语言模型(不带适配器)而不是DeBERTa的变体也在此文件夹中。
跨模态训练
FrozenBiLM
要在WebVid10M上训练FrozenBiLM,请运行:
python -m torch.distributed.launch --nproc_per_node 8 --use_env main.py \
--combine_datasets webvid --combine_datasets_val webvid --save_dir=trainwebvid \
--lr=3e-5 --ds_factor_ff=8 --ds_factor_attn=8 \
--batch_size=16 --batch_size_val=16 --epochs=2 \
基准模型
<details> <summary>点击查看详情... </summary> 基于之前的命令: - 不使用适配器的变体: 传入 `--lr=3e-4 --ds_factor_ff=0 --ds_factor_attn=0` - UnFrozenBiLM变体: 传入 `--lr=1e-5 --ft_lm --ft_mlm --ds_factor_ff=0 --ds_factor_attn=0 --batch_size=8` - 无语言初始化的UnFrozenBiLM变体: 传入 `-lr=1e-5 --ft_lm --ft_mlm --scratch --ds_factor_ff=0 --ds_factor_attn=0 --batch_size=8` - 其他语言模型: 传入 `--model_name=bert-large-uncased` 或 `--model_name=bert-base-uncased` 以使用BERT-Base或BERT-Large代替Deberta-V2-XLarge - 在WebVid10M的子集上训练: 对训练数据框文件进行随机采样,并更改 `--webvid_train_csv_path`。论文中使用的随机子集将很快发布。 </details>自回归变体
<details> <summary>点击查看详情... </summary> 要在WebVid10M上训练基于GPT-J-6B的自回归变体,运行: ``` python -m torch.distributed.launch --nproc_per_node 8 --use_env main_ar.py \ --combine_datasets webvid --combine_datasets_val webvid --save_dir=trainarwebvid \ --lr=3e-4 --model_name=gpt-j-6b \ --batch_size=4 --batch_size_val=4 --epochs=2 ``` 其他语言模型: 传入 `--model_name=gpt-neo-1p3b --batch_size=16 --batch_size_val=16` 或 `--model_name=gpt-neo-2p7b --batch_size=8 --batch_size_val=8` 以使用GPT-Neo-1.3B或GPT-Neo-2.7B代替GPT-J-6B </details>零样本视频问答
填空和开放式视频问答
FrozenBiLM
要在LSMDC-FiB、iVQA、MSRVTT-QA、MSVD-QA、ActivityNet-QA或TGIF-QA FrameQA上评估跨模态训练的FrozenBiLM,运行:
python -m torch.distributed.launch --nproc_per_node 8 --use_env videoqa.py --test --eval \
--combine_datasets <dataset> --combine_datasets_val <dataset> --save_dir=zs<dataset> \
--ds_factor_ff=8 --ds_factor_attn=8 --suffix="." \
--batch_size_val=32 --max_tokens=256 --load=<CKPT_PATH> --<dataset>_vocab_path=$DATA_DIR/<dataset>/vocab1000.json
基准模型
<details> <summary>点击查看详情... </summary> 基于之前的命令: - 不使用适配器的变体: 传入 `--ds_factor_ff=0 --ds_factor_attn=0` - UnFrozenBiLM变体: 传入 `--ft_lm --ft_mlm --ds_factor_ff=0 --ds_factor_attn=0` - 无语言初始化的UnFrozenBiLM变体: `--ft_lm --ft_mlm --scratch --ds_factor_ff=0 --ds_factor_attn=0` - 其他语言模型: 传入 `--model_name=bert-large-uncased` 或 `--model_name=bert-base-uncased` 以使用BERT-Base或BERT-Large代替Deberta-V2-XLarge - 仅文本: 传入 `--no_video` 且不传入 `--load` - 无语音: 传入 `--no_context` 以移除语音 - 无后缀: 传入 `--no_context` 且不传入 `--suffix` 参数 </details>自回归变体
<details> <summary>点击查看详情... </summary> 要在iVQA、MSRVTT-QA、MSVD-QA、ActivityNet-QA或TGIF-QA FrameQA上评估跨模态训练的基于GPT-J-6B的自回归变体,运行: ``` python -m torch.distributed.launch --nproc_per_node 8 --use_env videoqa_ar.py --test --eval \ --combine_datasets <dataset> --combine_datasets_val <dataset> --save_dir=zsar<dataset> \ --model_name=gpt-j-6b --batch_size_val=8 --max_tokens=256 --load=<CKPT_PATH> ``` 其他语言模型: 传入 `--model_name=gpt-neo-1p3b --batch_size_val=32` 或 `--model_name=gpt-neo-2p7b --batch_size_val=16` 以使用GPT-Neo-1.3B或GPT-Neo-2.7B代替GPT-J-6B </details>CLIP基准
<details> <summary>点击查看详情... </summary> 要在LSMDC-FiB、iVQA、MSRVTT-QA、MSVD-QA、ActivityNet-QA或TGIF-QA FrameQA上运行CLIP基准,运行: ``` python -m torch.distributed.launch --nproc_per_node 8 --use_env videoqa_clip.py --test --eval \ --combine_datasets <dataset> --combine_datasets_val <dataset> --save_dir=zsclip<dataset> \ --batch_size_val=16 --max_feats=1 ``` </details>多项选择视频问答
FrozenBiLM
要在How2QA或TVQA上评估跨模态训练的FrozenBiLM,运行:
python -m torch.distributed.launch --nproc_per_node 8 --use_env mc.py --eval \
--combine_datasets <dataset> --combine_datasets_val <dataset> --save_dir=zs<dataset> \
--ds_factor_ff=8 --ds_factor_attn=8 --suffix="." \
--batch_size_val=32 --max_tokens=512 --load=<CKPT_PATH>
基线模型
<details> <summary>点击查看详情... </summary> 基于上一个命令: - 不使用适配器的变体: 传入 `--ds_factor_ff=0 --ds_factor_attn=0` - UnFrozenBiLM 变体: 传入 `--ft_lm --ft_mlm --ds_factor_ff=0 --ds_factor_attn=0` - 无语言初始化的 UnFrozenBiLM 变体: `--ft_lm --ft_mlm --scratch --ds_factor_ff=0 --ds_factor_attn=0` - 其他语言模型: 传入 `--model_name=bert-large-uncased` 或 `--model_name=bert-base-uncased` 以使用 BERT-Base 或 BERT-Large 代替 Deberta-V2-XLarge - 仅文本: 传入 `--no_video` 且不使用 `--load` - 无语音: 传入 `--no_context` 以移除语音 </details>CLIP 基线模型
<details> <summary>点击查看详情... </summary> 在 How2QA 或 TVQA 上运行 CLIP 基线模型: ``` python -m torch.distributed.launch --nproc_per_node 8 --use_env mc_clip.py --test --eval \ --combine_datasets <dataset> --combine_datasets_val <dataset> \ --save_dir=zsclip<dataset> --batch_size_val=8 --max_feats=1 ``` </details>全监督视频问答
填空型和开放式视频问答
要在 LSMDC-FiB、iVQA、MSRVTT-QA、MSVD-QA、ActivityNet-QA 或 TGIF-QA FrameQA 上微调经过跨模态训练的 FrozenBiLM,请运行:
python -m torch.distributed.launch --nproc_per_node 4 --use_env videoqa.py \
--combine_datasets <dataset> --combine_datasets_val <dataset> --save_dir=ft<dataset> \
--lr=5e-5 --schedule=linear_with_warmup --load=<CKPT_PATH> \
--ds_factor_ff=8 --ds_factor_attn=8 --suffix="." \
--batch_size=8 --batch_size_val=32 --max_tokens 256 --epochs=20
对于 UnFrozenBiLM 变体,传入 --ft_lm --ft_mlm --ds_factor_ff=0 --ds_factor_attn=0。
多项选择视频问答
要在 How2QA 或 TVQA 上微调经过跨模态训练的 FrozenBiLM,请运行:
python -m torch.distributed.launch --nproc_per_node 8 --use_env mc.py \
--combine_datasets <dataset> --combine_datasets_val <dataset> --save_dir=ft<dataset> \
--lr=5e-5 --schedule=linear_with_warmup --load=<CKPT_PATH> \
--ds_factor_ff=8 --ds_factor_attn=8 --suffix="." \
--batch_size=2 --batch_size_val=8 --max_tokens=256 --epochs=20
对于 UnFrozenBiLM 变��体,传入 --ft_lm --ft_mlm --ds_factor_ff=0 --ds_factor_attn=0 --batch_size=1。
小样本视频问答
对于小样本视频问答,我们从训练数据框文件中采样一部分,并更改 --<dataset>_train_csv_path。
论文中使用的随机子集可在此处下载。
视频问答演示
使用训练好的检查点,您还可以使用自选的视频文件和问题运行视频问答示例。为此,请使用(答案词汇表来自 msrvtt_vocab_path):
python demo_videoqa.py --combine_datasets msrvtt --combine_datasets_val msrvtt \
--suffix="." --max_tokens=256 --ds_factor_ff=8 --ds_factor_attn=8 \
--load=<CKPT_PATH> --msrvtt_vocab_path=<VOCAB_PATH> \
--question_example <question> --video_example <video_path>
此演示可在至少有 4 个物理核心的 CPU 上运行。为此,请使用 --device='cpu'。请注意,此演示不使用语音输入,因为这需要使用现成的 ASR 提取器。
致谢
Transformer 模型的实现受到 Hugging Face 的 transformers 库的启发。 特征提取代码受到 Just Ask 的启发。
许可证
本代码根据 Apache License 2.0 发布。 论文中使用的数据集许可证可在以下链接获取: iVQA, MSRVTT-QA, MSVD-QA, ActivityNet-QA, How2QA 和 TVQA。
引用
如果您觉得这项工作有用,请考虑给这个仓库加星,并按以下方式引用我们的论文:
@inproceedings{yang2022frozenbilm,
title = {Zero-Shot Video Question Answering via Frozen Bidirectional Language Models},
author = {Antoine Yang and Antoine Miech and Josef Sivic and Ivan Laptev and Cordelia Schmid},
booktitle={NeurIPS}
year = {2022}}
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI�助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程��。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号