



快速Base64流编解码器

这是一个用C99实现的base64流编解码库,支持SIMD(AVX2、AVX512、NEON、AArch64/NEON、SSSE3、SSE4.1、SSE4.2、AVX)和OpenMP加速。它还包含了用于编解码简单长度限定字符串的包装函数。该库旨在做到:
- 快速;
- 易用;
- 优雅。
在x86平台上,该库会进行运行时特性检测。首次调用时,库会确定适合该机器的编解码例程,并在程序的整个生命周期内记住它们。如果处理器支持AVX2、SSSE3、SSE4.1、SSE4.2或AVX指令,库会选择优化的编解码器,一次处理12或24字节,比"普通"的按字节处理的编解码器快4倍或更多。
目前AVX512支持仅用于编码,使用AVX512 VL和VBMI指令。解码部分重用了AVX2实现。2018年后生产的Cannonlake之后的CPU支持这些指令。
NEON支持在编译时硬编码为开启或关闭,因为ARM平台上没有可移植的运行时特性检测。
即使处理器不支持SIMD指令,这也是一个非常快速的库。回退例程可以在一轮中处理32或64位输入,取决于处理器的字长,这仍然比朴素的按字节实现快得多。在某些64位机器上,64位例程甚至比SSSE3例程表现更好。
据作者所知,在最初发布时,这是唯一提供SIMD加速的Base64库。作者写了一篇文章解释了一种可能的SIMD方法来编解码Base64。该文章可以帮助理解代码在做什么,以及为什么这样做。
主要特点:
- 通过使用SIMD向量处理,在x86和ARM系统上非常快;
- 可以使用OpenMP实现更多并行��加速;
- 在其他32位或64位平台上通过优化例程实现高速;
- 读/写流数据块;
- 不动态分配内存;
- 有效的C99代码,可以使用严格选项编译;
- 可重入和线程安全;
- 经过单元测试;
- 使用Duff's Device。
致谢
原始的AVX2、NEON和Aarch64/NEON编解码器由Inkymail慷慨贡献,他们在自己的分支中还实现了一些额外功能。他们的工作正在逐步移植回这个项目。
SSSE3和AVX2编解码器通过使用Wojciech Muła在一系列文章中描述的非常巧妙的优化而得到了实质性改进。他自己的代码在这里。
AVX512编码器基于Wojciech Muła的base64simd库中的代码。
OpenMP实现由来自Exalon Delft的Ferry Toth (@htot)添加。
构建
lib目录包含实际库的代码。在顶级目录中输入make将构建lib/libbase64.o和bin/base64。前者是一个单独的、自包含的目标文件,可以链接到你自己的项目中。后者是一个独立的测试二进制文件,其工作方式类似于base64系统工具。
使用该库所需的匹配头文件在include/libbase64.h中。
要仅编译不带SIMD编解码器的"普通"库,输入:
make lib/libbase64.o
可以通过指定AVX2_CFLAGS、AVX512_CFLAGS、NEON32_CFLAGS、NEON64_CFLAGS、SSSE3_CFLAGS、SSE41_CFLAGS、SSE42_CFLAGS和/或AVX_CFLAGS环境变量来包含可选的SIMD编解码器。x86上典型的构建调用如下:
AVX2_CFLAGS=-mavx2 SSSE3_CFLAGS=-mssse3 SSE41_CFLAGS=-msse4.1 SSE42_CFLAGS=-msse4.2 AVX_CFLAGS=-mavx make lib/libbase64.o
AVX2
要构建并包含AVX2编解码器,将AVX2_CFLAGS环境变量设置为一个能在编译器中开启AVX2支持的值,通常是-mavx2。
示例:
AVX2_CFLAGS=-mavx2 make
AVX512
要构建并包含AVX512编解码器,将AVX512_CFLAGS环境变量设置为一个能在编译器中开启AVX512支持的值,通常是-mavx512vl -mavx512vbmi。
示例:
AVX512_CFLAGS="-mavx512vl -mavx512vbmi" make
只有当运行时特性检测显示目标机器支持AVX2时,才会使用该编解码器。
SSSE3
要构建并包含SSSE3编解码器,将SSSE3_CFLAGS环境变量设置为一个能在编译器中开启SSSE3支持的值,通常是-mssse3。
示例:
SSSE3_CFLAGS=-mssse3 make
只有当运行时特性检测显示目标机器支持SSSE3时,才会使用该编解码器。
NEON
该库包含两个NEON编解码器:一个用于常规32位ARM,另一个用于64位AArch64 with NEON,后者��有双倍数量的SIMD寄存器,可以进行完整的64字节表查找。这些编解码器以48字节块进行编码,以64字节大块进行解码,所以它们必须增加一个uint32/64编解码器以在较小的输入上保持快速!
使用LLVM/Clang来编译NEON编解码器。至少GCC 4.6(Raspbian附带的版本,用于测试)在编译vstq4_u8()时存在一个bug,生成的汇编代码质量低。NEON内联函数是GCC的已知弱点。Clang做得更好。
不幸的是,NEON支持无法在用户空间可移植地在运行时检测(mrc指令是特权指令),所以使用NEON编解码器的默认值在编译时确定。但你可以进行自己的运行时检测。你可以包含NEON编解码器并将其设为默认,然后在运行时检查CPU是否支持NEON,如果不支持,强制降级到非NEON,使用BASE64_FORCE_PLAIN。
你有这些选项:
- 不包含NEON支持;
- 构建NEON支持并将其设为默认,但构建所有其他代码时不使用NEON标志,这样你可以在运行时用
BASE64_FORCE_PLAIN覆盖默认设置; - 用NEON支持构建所有内容并将其设为默认;
- 用NEON支持构建所有内容,但不将其设为默认(这没有意义)。
对于选项1,只需完全不指定任何NEON特定的编译器标志,像这样:
CC=clang CFLAGS="-march=armv6" make
对于选项2,保持CFLAGS简单,但将NEON32_CFLAGS环境变量设置为一个能构建NEON支持的值。例如,下面的行将在ARMv6级别构建所有代码,除了NEON编解码器,它在ARMv7级别构建。它还会将NEON编解码器设为默认。对于ARMv6平台,在运行时用BASE64_FORCE_PLAIN标志覆盖该默认设置。这样就不会触及任何ARMv7/NEON代码。
CC=clang CFLAGS="-march=armv6" NEON32_CFLAGS="-march=armv7 -mfpu=neon" make
对于选项3,将所有内容放入CFLAGS并使用一个存根但非空的NEON32_CFLAGS。这�个例子适用于Raspberry Pi 2B V1.1,它支持NEON:
CC=clang CFLAGS="-march=armv7 -mtune=cortex-a7" NEON32_CFLAGS="-mfpu=neon" make
要构建并包含NEON64编解码器,像往常一样使用CFLAGS定义平台,并将NEON64_CFLAGS设置为一个非空的存根。(AArch64目标强制支持NEON64。)
示例:
CC=clang CFLAGS="--target=aarch64-linux-gnu -march=armv8-a" NEON64_CFLAGS=" " make
OpenMP
要在GCC上启用OpenMP,需要使用-fopenmp构建。这可以通过将OPENMP环境变量设置为1来实现。
示例:
OPENMP=1 make
这将让编译器定义_OPENMP,从而将OpenMP优化的lib_openmp.c包含到lib.c中。
默认情况下,并行线程数将等于处理器的核心数。在一个带有超线程的四核处理器上,将检测到八个核心,但超线程不会提高性能。
要获取有关OpenMP的详细信息,可以使用OMP_DISPLAY_ENV=VERBOSE启动程序,例如
OMP_DISPLAY_ENV=VERBOSE test/benchmark
要限制线程数,请使用OMP_THREAD_LIMIT=n启动程序,例如:
OMP_THREAD_LIMIT=2 test/benchmark
一个运行启用OpenMP、SSSE3和AVX2的基准测试的例子:
make clean && OPENMP=1 SSSE3_CFLAGS=-mssse3 AVX2_CFLAGS=-mavx2 make && OPENMP=1 make -C test
API参考
字符串由指针和长度表示;它们不以零结尾。这是一个有意识的设计决定。在解码步骤中,依赖零终止是没有意义的,因为输出可能包含合法的零字节。在编码步骤中,返回长度可以节省对输出调用strlen()的开销。如果你坚持要追加零,可以在给定的偏移量处轻松添加。
标志
一些API调用接受flags参数。
该参数可用于强制使用特定编解码器,即使该编解码器在当前构建中是无操作的。
主要用于测试目的,这在ARM上也很有用,因为在ARM上进行运行时NEON检测的唯一方法是询问操作系统它是否可用。
可以使用以下常量:
BASE64_FORCE_AVX2BASE64_FORCE_AVX512BASE64_FORCE_NEON32BASE64_FORCE_NEON64BASE64_FORCE_PLAINBASE64_FORCE_SSSE3BASE64_FORCE_SSE41BASE64_FORCE_SSE42BASE64_FORCE_AVX
将flags设置为0以获得默认行为,即在x86上进行运行时特性检测,在ARM上使用编译时固定编解码器,在其他平台上使用普通编解码器。
编码
base64_encode
void base64_encode ( const char *src , size_t srclen , char *out , size_t *outlen , int flags ) ;
包装函数,用于编码给定长度的普通字符串。
输出写入out,不带尾随零。
输出长度(以字节为单位)写入outlen。
out中的缓冲区由调用者分配,至少为输入大小的4/3。
base64_stream_encode_init
void base64_stream_encode_init ( struct base64_state *state , int flags ) ;
在调用base64_stream_encode()之前调用此函数来初始化状态。
base64_stream_encode
void base64_stream_encode ( struct base64_state *state , const char *src , size_t srclen , char *out , size_t *outlen ) ;
将src处给定长度的数据块编码到out处的缓冲区中。
调用者负责分配足够大的输出缓冲区;它必须至少是输入缓冲区大小的4/3,但要留有一些余量。
将写入的新字节数放入outlen(函数开始时设置为零)。
不会对输出进行零终止或最终处理。
base64_stream_encode_final
void base64_stream_encode_final ( struct base64_state *state , char *out , size_t *outlen ) ;
完成由之前对base64_stream_encode()的调用开始的输出。
如果适当,添加所需的流结束标记。
修改outlen,它将包含在out处写入的新字节数(通常为零)。
解码
base64_decode
int base64_decode ( const char *src , size_t srclen , char *out , size_t *outlen , int flags ) ;
包装函数,用于解码给定长度的普通字符串。
输出写入out,不带尾随零。输出长度(以字节为单位)写入outlen。
out中的缓冲区由调用者分配,至少为输入大小的3/4。
成功时返回1,由于无效输入导致解码错误时返回0。
如果所选编解码器未包含在当前构建中,则返回-1。
base64_stream_decode_init
void base64_stream_decode_init ( struct base64_state *state , int flags ) ;
在调用base64_stream_decode()之前调用此函数来初始化状态。
base64_stream_decode
int base64_stream_decode ( struct base64_state *state , const char *src , size_t srclen , char *out , size_t *outlen ) ;
将src处给定长度的数据块解码到out处��的缓冲区中。
调用者负责分配足够大的输出缓冲区;它必须至少是输入缓冲区大小的3/4,但要留有一些余量。
将写入的新字节数放入outlen(函数开始时设置为零)。
不会对输出进行零终止。
如果一切正常则返回1,如果发现解码错误(如无效字符)则返回0。
如果所选编解码器未包含在当前构建中,则返回-1。
测试工具使用此函数来检查编解码器是否可用于测试。
示例
一个将静态字符串编码为base64并将输出打印到stdout的简单示例:
#include <stdio.h> /* fwrite */ #include "libbase64.h" int main () { char src[] = "hello world"; char out[20]; size_t srclen = sizeof(src) - 1; size_t outlen; base64_encode(src, srclen, out, &outlen, 0); fwrite(out, outlen, 1, stdout); return 0; }
一个将标准输入流编码到标准输出的简��单示例(没有错误检查等):
#include <stdio.h> #include "libbase64.h" int main () { size_t nread, nout; char buf[12000], out[16000]; struct base64_state state; // 初始化流编码器: base64_stream_encode_init(&state, 0); // 将stdin的内容读入缓冲区: while ((nread = fread(buf, 1, sizeof(buf), stdin)) > 0) { // 编码缓冲区: base64_stream_encode(&state, buf, nread, out, &nout); // 如果有输出,将其打印到stdout: if (nout) { fwrite(out, nout, 1, stdout); } // 如果发生错误,退出循环: if (feof(stdin)) { break; } } // 完成编码: base64_stream_encode_final(&state, out, &nout); // 如果最终处理产生额外的输出字节,打印它们: if (nout) { fwrite(out, nout, 1, stdout); } return 0; }
另请参阅bin/base64.c,它是base64实用程序的简单重新实现。
文件或标准输入通过编码器/解码器传递,输出写入标准输出。
测试
请参阅tests/目录中的小型测试套件。测试使用GitHub Actions自动化,它在各种架构上构建和测试代码。
基准测试
可以使用内置的基准测试程序运行基准测试,如下所示:
make -C test benchmark <buildflags> && test/benchmark
它将为所有已编译的编解码器运行编码和解码基准测试。
下表包含一些随机机器上的结果。所有数字均使用10MB缓冲区测量,单位为MB/秒,四舍五入到最接近的整数。
*: 需要更新
x86处理器
| 处理器 | 普通加密 | 普通解密 | SSSE3加密 | SSSE3解密 | AVX加密 | AVX解密 | AVX2加密 | AVX2解密 |
|---|---|---|---|---|---|---|---|---|
| i7-4771 @ 3.5 GHz | 833* | 1111* | 3333* | 4444* | 待定 | 待定 | 4999* | 6666* |
| i7-4770 @ 3.4 GHz DDR1600 | 1790* | 3038* | 4899* | 4043* | 4796* | 5709* | 4681* | 6386* |
| i7-4770 @ 3.4 GHz DDR1600 OPENMP 1线程 | 1784* | 3041* | 4945* | 4035* | 4776* | 5719* | 4661* | 6294* |
| i7-4770 @ 3.4 GHz DDR1600 OPENMP 2线程 | 3401* | 5729* | 5489* | 7444* | 5003* | 8624* | 5105* | 8558* |
| i7-4770 @ 3.4 GHz DDR1600 OPENMP 4线程 | 4884* | 7099* | 4917* | 7057* | 4799* | 7143* | 4902* | 7219* |
| i7-4770 @ 3.4 GHz DDR1600 OPENMP 8线程 | 5212* | 8849* | 5284* | 9099* | 5289* | 9220* | 4849* | 9200* |
| i7-4870HQ @ 2.5 GHz | 1471* | 3066* | 6721* | 6962* | 7015* | 8267* | 8328* | 11576* |
| i5-4590S @ 3.0 GHz | 3356 | 3197 | 4363 | 6104 | 4243* | 6233 | 4160* | 6344 |
| Xeon X5570 @ 2.93 GHz | 2161 | 1508 | 3160 | 3915 | - | - | - | - |
| Pentium4 @ 3.4 GHz | 896 | 740 | - | - | - | - | - | - |
| Atom N270 | 243 | 266 | 508 | 387 | - | - | - | - |
| AMD E-450 | 645 | 564 | 625 | 634 | - | - | - | - |
| Intel Edison @ 500 MHz | 79* | 92* | 152* | 172* | - | - | - | - |
| Intel Edison @ 500 MHz OPENMP 2线程 | 158* | 184* | 300* | 343* | - | - | - | - |
| Intel Edison @ 500 MHz (x86-64) | 162 | 119 | 209 | 164 | - | - | - | - |
| Intel Edison @ 500 MHz (x86-64) 2线程 | 319 | 237 | 412 | 329 | - | - | - | - |
ARM处理器
| 处理器 | 普通加密 | 普通解密 | NEON32加密 | NEON32解密 | NEON64加密 | NEON64解密 |
|---|---|---|---|---|---|---|
| Raspberry PI B+ V1.2 | 46* | 40* | - | - | - | - |
| Raspberry PI 2 B V1.1 | 85 | 141 | 300 | 225 | - | - |
| Apple iPhone SE armv7 | 1056* | 895* | 2943* | 2618* | - | - |
| Apple iPhone SE arm64 | 1061* | 1239* | - | - | 4098* | 3983* |
PowerPC处理器
| 处理器 | 普通加密 | 普通解密 |
|---|---|---|
| PowerPC E6500 @ 1.8GHz | 270* | 265* |
i7-4770 @ 3.4 GHz DDR1600不同缓冲区大小的基准测试:
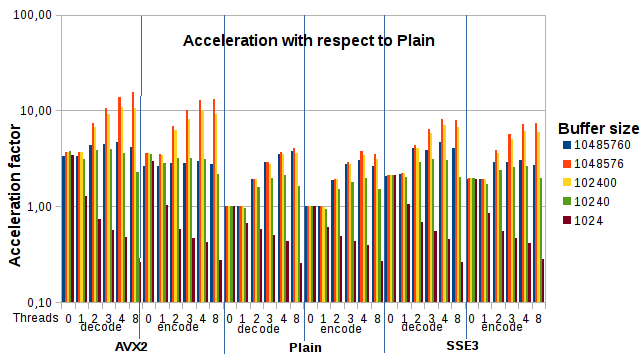
注意:利用缓存的最佳缓冲区大小范围为100 kB到1 MB,使AVX编码/解码速度比普通方式快12倍,或吞吐量达到24/27GB/秒。
还要注意,当缓冲区大小小于10 kB时,由于线程创建开销,性能会下降。
为防止这种情况发生,lib_openmp.c定义了OMP_THRESHOLD 20000,要求至少20000字节的缓冲区才能启用多线程。
许可证
本仓库采用BSD 2-clause许可证。详见LICENSE文件。
编辑推荐精选


Pixmax
一站式AI短剧创作平台
Pixmax专注打造下一代“ AI 视觉创作引擎”,整合行业顶尖 AI 大模型、工工业级精准控制及企业级协同管理功能,是全方位的 AI 内容创作平台。


豆包
字节跳动旗下 AI 智能助手
字节跳动旗下 AI 智能助手


GPT Plus|Pro充值
GPT充值
支持 ChatGPT Plus / Pro 充值服务,支付便捷,自动发货,售后可查。


GPT Image 2中文站
AI 图片生成平台
GPT Image 2 是面向用户的 AI 图片生成平台,支持文生图、图生图及多模型创意工作流。


Vecbase
你的AI Agent团队
Vecbase 是专为 AI 团队打造的智能工作空间,将数据管理、模型协作与知识沉淀整合于一处。算法、产品与业务在同一平台无缝协同,让从数据到 AI 应用的落地更快一步。


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


QoderWork
阿里Qoder团队推出的桌面端AI智能体
QoderWork 是阿里推出的本地优先桌面 AI 智能体,适配 macOS14+/Windows10+,以自然语言交互实现文件管理、数据分析、AI 视觉生成、浏览器自动化等办公任务,自主拆解执行复杂工作流,数据本地运行零上传,技能市场可无限扩展,是高效的 Agentic 生产力办公助手。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。


seedancetwo2.0
能听懂你表达的视频模型
Seedance two是基于seedance2.0的中国大模型,支持图像、视频、音频、文本四种模态输入,表达方式更丰富,生成也更可控。
推荐工具精选






AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号