



MonoHuman:从单目视频生成可动画人体神经场(CVPR 2023)
<img src="https://yellow-cdn.veclightyear.com/835a84d5/2f24ca6b-3c24-4f2d-b51e-3c1aa823b4df.jpg">MonoHuman:从单目视频生成可动画人体神经场<br> Zhengming Yu, Wei Cheng, Xian Liu, Wayne Wu, 和 Kwan-Yee Lin <br> 演示视频 | 项目主页 | 论文
这是使用PyTorch实现的MonoHuman官方代码
在各种应用中,如虚拟现实和数字娱乐,使用自由视角控制来制作虚拟化身动画至关重要。先前的研究尝试利用神经辐射场(NeRF)的表示能力从单目视频重建人体。最近的工作提出将变形网络嫁接到NeRF中,以进一步模拟人体神经场的动态,从而制作生动的人体动作动画。然而,这些流程要么依赖于姿态相关的表示,要么由于帧独立优化而缺乏动作连贯性,难以真实地泛化到未见过的姿态序列。在本文中,我们提出了一个新颖的框架MonoHuman,它能够在任意新姿态下稳健地渲染出视角一致且高保真的化身。我们的关键洞见是使用双向约束来建模变形场,并明确利用现成的关键帧信息来推理特征相关性,以获得连贯的结果。具体而言,我们首先提出了一个共享双向变形模块,通过将后向和前向变形对应关系分解为共享的骨骼运动权重和单独的非刚性运动,创建了一个与姿态无关的可泛化变形场。然后,我们设计了一�个前向对应搜索模块,查询关键帧的对应特征来指导渲染网络。因此,即使在具有挑战性的新姿态设置下,渲染结果也具有多视角一致性和高保真度。大量实验证明了所提出的MonoHuman优于现有最先进的方法。
安装
我们推荐使用Anaconda。
创建并激活虚拟环境。
conda env create -f environment.yaml
conda activate Monohuman
下载SMPL模型
从这里下载性别中性的SMPL模型,并解压mpips_smplify_public_v2.zip。
复制SMPL模型。
cp /path/to/smpl/smplify_public/code/models/basicModel_neutral_lbs_10_207_0_v1.0.0.pkl third_parties/smpl/models
按照此页面的说明从SMPL模型中移除Chumpy对象。
下载预训练模型
从这里下载预训练模型
在ZJU-Mocap数据集上运行
准备数据集
-
从这里下载ZJU-Mocap数据集。
-
修改
tools/prepare_zju_mocap/377.yaml中的主体yaml文件,如下所示:
dataset:
zju_mocap_path: /path/to/zju_mocap
subject: '377'
sex: 'neutral'
...
- 运行数据预处理脚本。
cd tools/prepare_zju_mocap
python prepare_dataset.py --cfg 377.yaml
cd ../../
- 修改core/data/dataset_args.py中的'dataset_path'为你的/path/to/dataset
训练
python train.py --cfg configs/monohuman/zju_mocap/377/377.yaml resume False
DDP训练:
python -m torch.distributed.launch --nproc_per_node 4 train.py --cfg configs/monohuman/zju_mocap/377/377.yaml --ddp resume False
渲染和评估
渲染动作序列。(例如,主体377)
python run.py \
--type movement \
--cfg configs/monohuman/zju_mocap/377/377.yaml
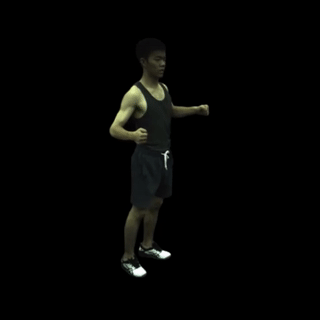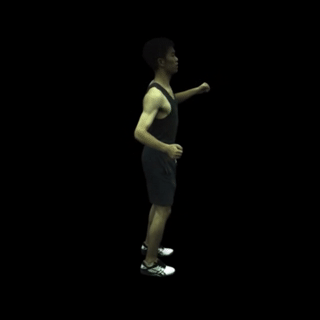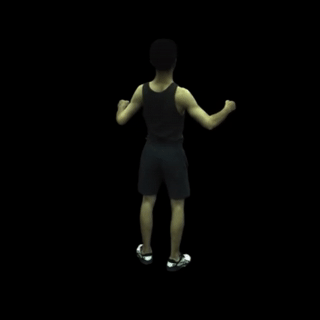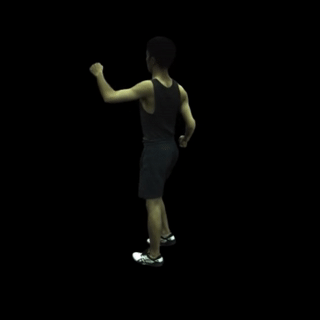
在特定帧上渲染自由视角图像(例如,主体387和第100帧)。
python run.py \
--type freeview \
--cfg configs/monohuman/zju_mocap/387/387.yaml \
freeview.frame_idx 100
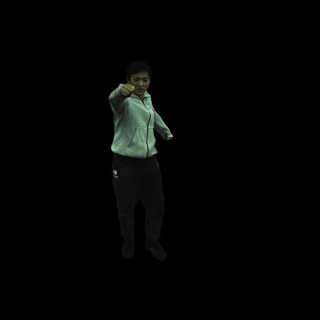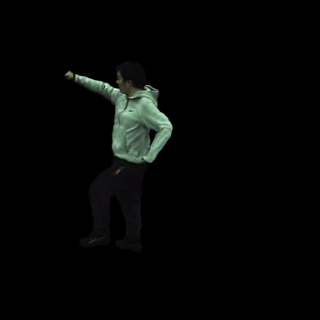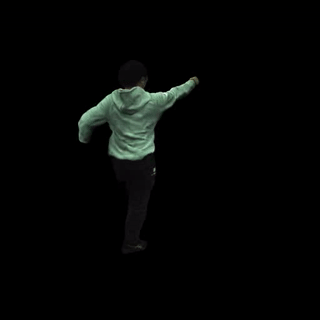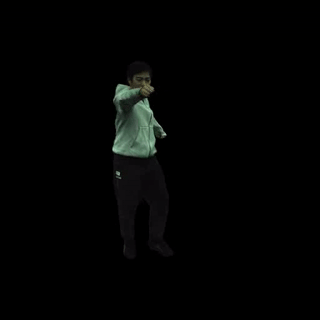
渲染文本驱动的动作序列。
从MDM生成姿态序列,并将序列放在path/to/pose_sequence/sequence.npy中(例如,主体394和后空翻)
python run.py \
--type text \
--cfg configs/monohuman/zju_mocap/394/394.yaml \
text.pose_path path/to/pose_sequence/backflip.npy
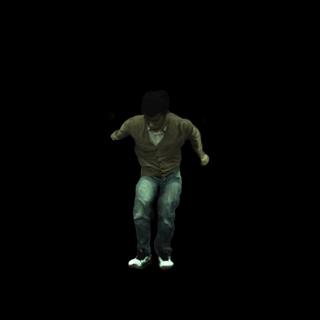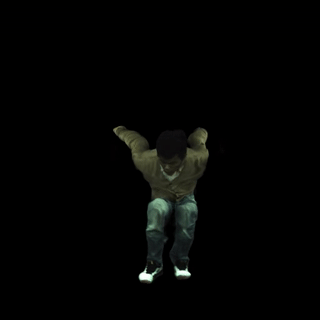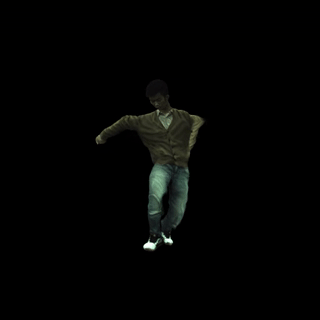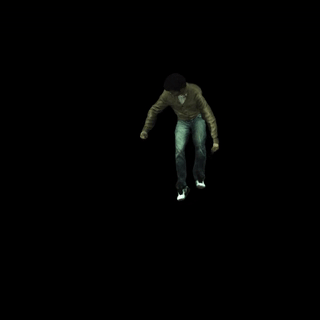
在野外视频上运行
准备数据集
然后将结果放在数据集路径中,如下所示:
dataset_path
├── images
│ └── ${item_id}.png
├── masks
│ └── ${item_id}.png
└── pare
└── ${item_id}.pkl
运行数据预处理脚本。
cd tools/prepare_wild
python process_pare.py --dataset_path path/to/dataset
python prepare_dataset.py --dataset_path path/to/dataset
python select_keyframe.py --angle_threahold 30 --dataset_path path/to/dataset
然后根据select_keyframe.py的输出修改wild.yaml中的index_a和index_b。
训练过程与ZJU_Mocap数据集相同。
渲染
以下是一个渲染输出示例(我们从互联网上随机收集了一段视频)。
python run.py \
--type freeview \
--cfg configs/monohuman/wild/wild.yaml \

致谢
我们的代码参考了HumanNeRF、IBRNet、Neural Body。我们感谢这些作者的出色工作和开源贡献。
待办事项
- 代码发布。
- 演示视频发布。
- 论文发布。
- DDP训练。
- 预训练模型发布。
<a name="citation"></a>
引用
如果你发现这项工作对你的研究有用,请考虑引用我们的论文:
@inproceedings{yu2023monohuman, title={MonoHuman: Animatable Human Neural Field from Monocular Video}, author={Yu, Zhengming and Cheng, Wei and Liu, Xian and Wu, Wayne and Lin, Kwan-Yee}, booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, pages={16943--16953}, year={2023} }
编辑推荐精选


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


QoderWork
阿里Qoder团队推出的桌面端AI智能体
QoderWork 是阿里推出的本地优先桌面 AI 智能体,适配 macOS14+/Windows10+,以自然语言交互实现文件管理、数据分析、AI 视觉生成、浏览器自动化等办公任务,自主拆解执行复杂工作流,数据本地运行零上传,技能市场可无限扩展,是高效的 Agentic 生产力办公助手。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。


seedancetwo2.0
能听懂你表达的视频模型
Seedance two是基于seedance2.0的中国大模型,支持图像、视频、音频、文本四种模态输入,表达方式更丰富,生成也更可控。


nano-banana纳米香蕉中文站
国内直接访问,限时3折
输入简单文字,生成想要的图片,纳米香蕉中文站基于 Google 模型的 AI 图片生成网站,支持文字生图、图生图。官网价格限时3折活动


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具
推荐工具精选





AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号