



目录
<br/> </details>👋🏻 简介
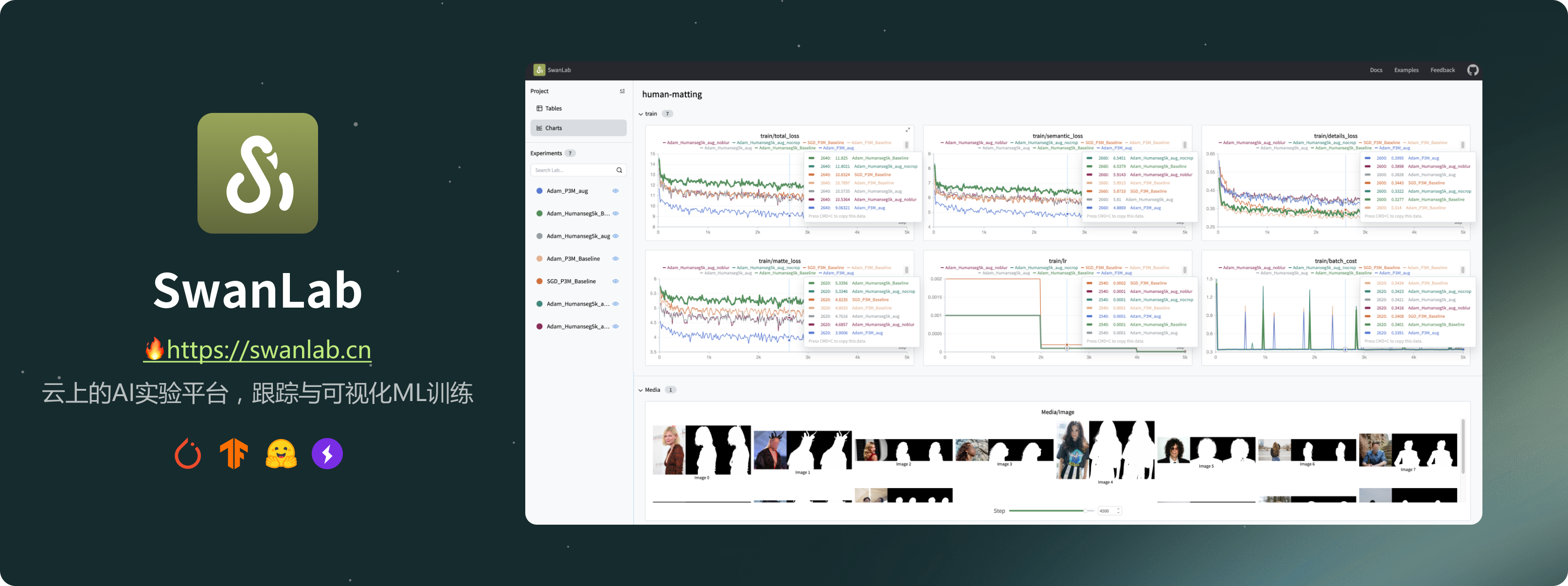
SwanLab是一个开源、轻量级的AI实验跟踪工具,提供了一个用于跟踪、比较和协作实验的平台。
它提供了用户友好的API和decent的界面,结合了跟踪超参数、记录指标、在线协作和分享实验链接等功能。
以下是AI平台核心功能列表的中文版本:
1. 📊 实验指标和超参数跟踪:使用简洁的代码嵌入您的机器学习流程,并跟踪关键训练指标。
- 灵活记录超参数和实验配置。
- 支持的元数据类型:标量指标、图像、音频、文本等。
- 支持的图表类型:线图、媒体图表(图像、音频、文本)等。
- 自动记录:控制台日志、GPU硬件信息、Git信息、Python解释器、Python库列表、代码目录。
2. ⚡️ 综合框架集成:PyTorch、Tensorflow、PyTorch Lightning、🤗HuggingFace、Transformers、MMEngine、Ultralytics、fastai、Tensorboard、OpenAI、ZhipuAI、Hydra、...
3. 📦 组织实验:集中式仪表板,高效管理多个项目和实验,一目了然地概览训练情况。
4. 🆚 比较结果:使用在线表格和配对图表比较不同实验的超参数和结果,启发迭代灵感。
5. 👥 在线协作:与团队成员在训练项目上协作,支持同一项目下实验的实时同步,让您能在线同步团队的训练记录,并基于结果分享见解和建议。
6. ✉️ 分享结果:复制并发送持久性URL以分享每个实验,高效地发送给同事,或嵌入在线笔记中。
7. 💻 自托管支持:支持离线模式,提供自托管社区版,同样允许查看仪表板和管理实验。
[!重要]
为我们点星,您将及时收到来自GitHub的所有发布通知 ~ ⭐️

📃 演示
查看SwanLab的在线演示:
| ResNet50 猫狗分类 | Yolov8-COCO128 |
|---|---|
| <a href="https://swanlab.cn/@ZeyiLin/Cats_Dogs_Classification/runs/jzo93k112f15pmx14vtxf/chart"> <img src="https://yellow-cdn.veclightyear.com/0a4dffa0/0b29a0b8-c98a-4a58-954a-39e4592b2752.png"> </a> | <a href="https://swanlab.cn/@ZeyiLin/ultratest/runs/yux7vclmsmmsar9ear7u5/chart"> <img src="https://yellow-cdn.veclightyear.com/0a4dffa0/f07152fd-9f92-4ad7-a4fe-5aae51decaa3.png"> </a> |
| 跟踪在猫狗数据集上训练简单ResNet50模型的图像分类任务。 | 使用Yolov8在COCO128数据集上执行目标检测任务,跟踪训练超参数和指标。 |
| Qwen2指令微调 | LSTM谷歌股票预测 |
|---|---|
| <a href="https://swanlab.cn/@ZeyiLin/Qwen2-fintune/runs/cfg5f8dzkp6vouxzaxlx6/chart"> <img src="https://yellow-cdn.veclightyear.com/0a4dffa0/b3e334f6-317f-4fdc-be12-a3c6e93d8035.png"> </a> | <a href="https://swanlab.cn/@ZeyiLin/Google-Stock-Prediction/charts"> <img src="https://yellow-cdn.veclightyear.com/0a4dffa0/5f3db686-6230-4f78-8e75-80975d022ebd.png"> </a> |
| 跟踪Qwen2大语言模型的指令微调训练,完成简单的指令遵循。 | 在谷歌股价数据集上训练简单的LSTM模型,预测未来股价。 |
🏁 快速开始
1.安装
pip install swanlab
2.登录并获取API密钥
swanlab login
当提示时,输入您的API密钥并按回车完成登录。
3. 将SwanLab集成到您的代码中
import swanlab # 创建一个新的SwanLab实验 swanlab.init( project="my-first-ml", config={'learning-rate': 0.003} ) # 记录指标 for i in range(10): swanlab.log({"loss": i})
一切就绪! 访问SwanLab查看您的第一个SwanLab实验。
💻 自托管
社区版支持离线查看SwanLab仪表板。
离线实验追踪
在swanlab.init中设置参数logdir和mode以进行离线实验追踪:
... swanlab.init( logdir='./logs', mode='local', ) ...
-
参数
mode设置为local,这会禁用将实验同步到云端。 -
参数
logdir的设置是可选的,它指定了保存SwanLab日志文件的位置(默认保存在swanlog文件夹中)。 -
在追踪实验过程中会创建和更新日志文件,启动离线仪表板也将基于这些日志文件。
其他部分与云端使用完全一致。
打开离线仪表板
打开终端并使用以下命令来打开SwanLab仪表板:
swanlab watch ./logs
操作完成后,SwanLab将为您提供一个本地URL链接(默认为http://127.0.0.1:5092)。
访问此链接即可在浏览器仪表板中离线查看实验。
<br>🚗 集成
将您喜欢的框架与SwanLab结合,更多集成。
<details> <summary> <strong>⚡️ PyTorch Lightning</strong> </summary> <br>使用SwanLabLogger创建一个实例,并将其传递给Trainer的logger参数,以使SwanLab能够记录训练指标。
</details> <details> <summary> <strong> 🤗HuggingFace Transformers</strong> </summary> <br>from swanlab.integration.pytorch_lightning import SwanLabLogger import importlib.util import os import pytorch_lightning as pl from torch import nn, optim, utils from torchvision.datasets import MNIST from torchvision.transforms import ToTensor encoder = nn.Sequential(nn.Linear(28 * 28, 128), nn.ReLU(), nn.Linear(128, 3)) decoder = nn.Sequential(nn.Linear(3, 128), nn.ReLU(), nn.Linear(128, 28 * 28)) class LitAutoEncoder(pl.LightningModule): def __init__(self, encoder, decoder): super().__init__() self.encoder = encoder self.decoder = decoder def training_step(self, batch, batch_idx): # training_step定义了训练循环。 # 它独立于forward x, y = batch x = x.view(x.size(0), -1) z = self.encoder(x) x_hat = self.decoder(z) loss = nn.functional.mse_loss(x_hat, x) # 默认记录到TensorBoard(如果已安装) self.log("train_loss", loss) return loss def test_step(self, batch, batch_idx): # test_step定义了测试循环。 # 它独立于forward x, y = batch x = x.view(x.size(0), -1) z = self.encoder(x) x_hat = self.decoder(z) loss = nn.functional.mse_loss(x_hat, x) # 默认记录到TensorBoard(如果已安装) self.log("test_loss", loss) return loss def configure_optimizers(self): optimizer = optim.Adam(self.parameters(), lr=1e-3) return optimizer # 初始化自动编码器 autoencoder = LitAutoEncoder(encoder, decoder) # 设置数据 dataset = MNIST(os.getcwd(), train=True, download=True, transform=ToTensor()) train_dataset, val_dataset = utils.data.random_split(dataset, [55000, 5000]) test_dataset = MNIST(os.getcwd(), train=False, download=True, transform=ToTensor()) train_loader = utils.data.DataLoader(train_dataset) val_loader = utils.data.DataLoader(val_dataset) test_loader = utils.data.DataLoader(test_dataset) swanlab_logger = SwanLabLogger( project="swanlab_example", experiment_name="example_experiment", cloud=False, ) trainer = pl.Trainer(limit_train_batches=100, max_epochs=5, logger=swanlab_logger) trainer.fit(model=autoencoder, train_dataloaders=train_loader, val_dataloaders=val_loader) trainer.test(dataloaders=test_loader)
使用SwanLabCallback创建一个实例,并将其传递给Trainer的callbacks参数,以使SwanLab能够记录训练指标。
import evaluate import numpy as np import swanlab from swanlab.integration.huggingface import SwanLabCallback from datasets import load_dataset from transformers import AutoModelForSequenceClassification, AutoTokenizer, Trainer, TrainingArguments def tokenize_function(examples): return tokenizer(examples["text"], padding="max_length", truncation=True) def compute_metrics(eval_pred): logits, labels = eval_pred predictions = np.argmax(logits, axis=-1) return metric.compute(predictions=predictions, references=labels) dataset = load_dataset("yelp_review_full") tokenizer = AutoTokenizer.from_pretrained("bert-base-cased") tokenized_datasets = dataset.map(tokenize_function, batched=True) small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000)) small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000)) metric = evaluate.load("accuracy") model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5) training_args = TrainingArguments( output_dir="test_trainer", report_to="none", num_train_epochs=3, logging_steps=50, ) swanlab_callback = SwanLabCallback(experiment_name="TransformersTest", cloud=False)
trainer = Trainer( model=model, args=training_args, train_dataset=small_train_dataset, eval_dataset=small_eval_dataset, compute_metrics=compute_metrics, callbacks=[swanlab_callback], )
trainer.train()
</details>
<details>
<summary>
<strong> MMEngine(MMDetection等)</strong>
</summary>
<br>
将`SwanlabVisBackend`集成到MMEngine中,以启用SwanLab自动记录训练指标。
在MM配置文件中添加以下代码片段以开始训练:
```python
custom_imports = dict(imports=["swanlab.integration.mmengine"], allow_failed_imports=False)
vis_backends = [
dict(
type="SwanlabVisBackend",
save_dir="runs/swanlab",
init_kwargs={
"project": "swanlab-mmengine",
},
),
]
visualizer = dict(
type="Visualizer",
vis_backends=vis_backends,
)
将SwanLab集成到Ultralytics非常简单;你可以使用add_swanlab_callback函数:
</details> <br>from ultralytics import YOLO from swanlab.integration.ultralytics import add_swanlab_callback model = YOLO("yolov8n.yaml") model.load() add_swanlab_callback(model) model.train( data="./coco.yaml", epochs=50, imgsz=320, )
🆚 与熟悉工具的比较
Tensorboard vs SwanLab
-
☁️ 在线使用支持: 使用SwanLab,训练实验可以方便地同步并保存在云端,允许远程监控训练进度、管理历史项目、分享实验链接、发送实时通知消息,以及在多个设备上查看实验。相比之下,TensorBoard是一个离线的实验跟踪工具。
-
👥 协作多用户环境: SwanLab便于管理多人训练项目,并轻松分享实验链接,实现团队间的机器学习协作。它还支持跨空间的交流和讨论。另一方面,TensorBoard主要为个人使用设计,难以实现多用户之间的协作和实验共享。
-
💻 持久化、集中化的仪表板: 无论你在哪里训练模型,无论是本地计算机、实验室集群还是公有云GPU实例,你的结果都会被记录到同一个集中化的仪表板。而使用TensorBoard则需要花时间从不同机器复制和管理TFEvent文件。
-
💪 更强大的表格: SwanLab表格允许你查看、搜索和过滤来自各种实验的结果,便于审查数千个模型版本,找出不同任务的最佳表现模型。TensorBoard不太适合大规模项目。
Weights and Biases vs SwanLab
-
Weights and Biases是一个仅在线的专有MLOps平台。
-
SwanLab不仅支持在线使用,还提供开源、免费和自托管版本。
👥 社区
社区和支持
- GitHub Issues:使用SwanLab时遇到的错误和问题
- 电子邮件支持:关于使用SwanLab问题的反馈
- <a href="https://geektechstudio.feishu.cn/wiki/NIZ9wp5LRiSqQykizbGcVzUKnic">微信</a>:讨论使用SwanLab的问题,分享最新AI技术。
SwanLab README徽章
如果你喜欢在你的工作中使用SwanLab,请在你的README中添加SwanLab徽章:
[](https://github.com/swanhubx/swanlab)
在论文中引用SwanLab
如果你发现SwanLab对你的研究有帮助,请考虑以以下格式引用:
@software{Zeyilin_SwanLab_2023, author = {Zeyi Lin, Shaohong Chen, Kang Li, Qiushan Jiang, Zirui Cai, Kaifang Ji and {The SwanLab team}}, doi = {10.5281/zenodo.11100550}, license = {Apache-2.0}, title = {{SwanLab}}, url = {https://github.com/swanhubx/swanlab}, year = {2023} }
为SwanLab做贡献
考虑为SwanLab做贡献?首先,请花些时间阅读贡献指南。
同时,我们热烈欢迎通过社交媒体、活动和会议分享来支持SwanLab。谢谢!
<br>贡献者
<a href="https://github.com/swanhubx/swanlab/graphs/contributors"> <img src="https://contrib.rocks/image?repo=swanhubx/swanlab" /> </a>下载图标
<br>📃 许可证
本仓库遵循Apache 2.0 许可证开源许可。
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专��家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应��俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




{kind=link}
AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号