
m2
子二次GEMM架构Monarch Mixer实现高效语言模型
Monarch Mixer是一种创新的子二次GEMM架构,用于训练序列长度和模型维度均为子二次的语言模型。该架构使用Monarch矩阵层替代Transformer中的注意力和MLP操作,提高了计算效率。基于此架构的M2-BERT模型在减少25%参数和计算量的同时,在GLUE基准测试中达到了与BERT相当的性能。项目开源了预训练模型权重以及预训练和微调代码,方便研究者进行further研究。




Monarch混合器
2024年1月11日更新: 我们很高兴发布新的长上下文M2-BERT模型,其中包括为嵌入微调的版本!详情请参阅博客文章,更多细节请查看bert/EMBEDDINGS.md!
<p align="center"> <img width="40%" src="https://yellow-cdn.veclightyear.com/835a84d5/2302baa3-3c47-44d6-ae6e-3b2b2f5f51fa.png"> </p>Monarch混合器:一种简单的亚二次GEMM基础架构
Daniel Y. Fu, Simran Arora*, Jessica Grogan*, Isys Johnson*, Sabri Eyuboglu*, Armin W. Thomas*, Benjamin F. Spector, Michael Poli, Atri Rudra, 和 Christopher Ré.
arXiv | M2-BERT博客文章
使用Monarch混合器的长上下文检索模型
Jon Saad-Falcon, Dan Fu, Simran Arora. 博客文章,2024年1月11日.
博客文章.
更新:
- 2024年1月11日: M2-BERT检索模型现已在Together API上提供!查看下方说明以运行它们!
- 2024年1月11日: 新的长上下文M2-BERT模型(2k、8k和32k)以及用于嵌入的检索版本现已可用。同时发布LoCo预览版,这是一个新的长上下文检索基准!查看我们的博客了解更多信息,并在这里试用这些模型!
- 2023年10月21日: M2-BERT-large检查点现已在HuggingFace上提供(260M,341M)。260M模型在GLUE微调方面与BERT-large相匹配,参数减少24%,而341M模型优于BERT-large。
- 2023年10月18日: M2论文现已在arXiv上发布,并将在NeurIPS上作为口头报告呈现!
基础M2-BERT检查点:
长上下文和检索M2-BERT检查点:
- M2-BERT-base-80M-2K
- M2-BERT-base-80M-8K
- M2-BERT-base-80M-32K
- M2-BERT-base-80M-2K-retrieval
- M2-BERT-base-80M-8K-retrieval
- M2-BERT-base-80M-32K-retrieval Transformer已经席卷了全球!该架构由两个核心操作组成:注意力机制用于混合输入序列中的信息,MLP用于混合模型维度中的信息。每个操作的复杂度都是二次方的——注意力机制的复杂度与序列长度成二次方关系,MLP的复杂度与模型维度成二次方关系。理想情况下,我们希望有更高效的替代方案,同时保持Transformer级别的质量。为此,我们一直在开发Monarch Mixer (M2),这是一个用于训练模型的框架,在序列长度和模型维度上都是亚二次方的。
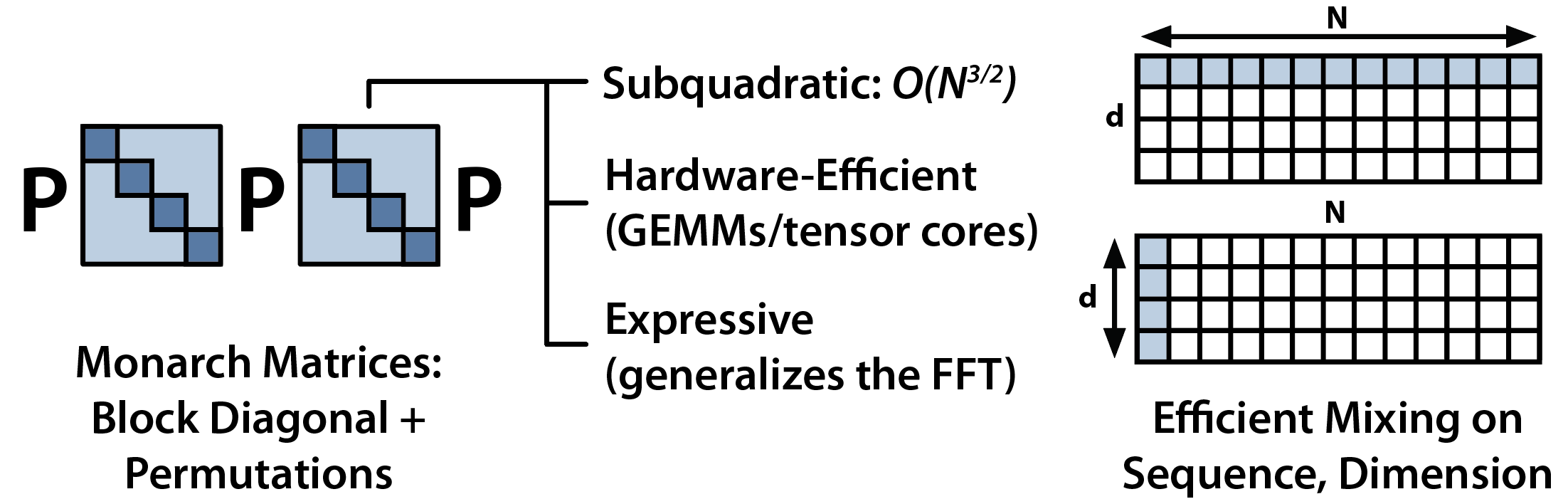
我们的基本思想是用Monarch矩阵替换Transformer的主要元素——Monarch矩阵是一类结构化矩阵,它们是FFT的推广,具有亚二次方、硬件高效和表达能力强的特点。在Monarch Mixer中,我们使用由Monarch矩阵构建的层来进行序列间的混合(替代注意力操作)和模型维度间的混合(替代密集MLP)。这个仓库包含了用于训练Monarch Mixer架构的代码和模型!
开始使用嵌入
M2-BERT嵌入模型现已在Together API上可用。 你可以通过注册账户并按如下方式查询API来运行它们(你可以在这里找到你的API密钥):
import os import requests def generate_together_embeddings(text: str, model_api_string: str, api_key: str): url = "https://api.together.xyz/api/v1/embeddings" headers = { "accept": "application/json", "content-type": "application/json", "Authorization": f"Bearer {api_key}" } session = requests.Session() response = session.post( url, headers=headers, json={ "input": text, "model": model_api_string } ) if response.status_code != 200: raise ValueError(f"请求失败,状态码 {response.status_code}:{response.text}") return response.json()['data'][0]['embedding'] print(generate_together_embeddings('Hello world', 'togethercomputer/m2-bert-80M-32k-retrieval', os.environ['TOGETHER_API_KEY'])[:10])
查看bert/EMBEDDINGS.md获取更多关于如何评估这些模型并在本地运行它们的信息!
当前内容
**2024年1月9日:**长上下文M2-BERT-base检查点已上传至HuggingFace,同时还有用于嵌入模型的检索版本!
**2023年10月21日:**M2-BERT-large检查点现已上传至HuggingFace,论文也已发布在arXiv上!
**2023年7月24日:**我们很高兴发布Monarch Mixer BERT (M2-BERT),它比BERT少25%的参数/FLOPs,并在GLUE基准测试上匹配了平均质量。BERT文件夹包含了预训练和微调BERT基线和M2-BERT的代码。我们还发布了128序列长度的预训练检查点,包括一个80M参数的BERT模型,它在GLUE基准测试的平均分数上匹配了110M参数的BERT-base-uncased模型,以及一个参数匹配的M2-BERT模型。
引用
如果你使用了这个代码库,或者认为我们的工作有价值,你可以按以下方式引用我们:
@inproceedings{fu2023monarch,
title={Monarch Mixer: A Simple Sub-Quadratic GEMM-Based Architecture},
author={Fu, Daniel Y and Arora, Simran and Grogan, Jessica and Johnson, Isys and Eyuboglu, Sabri and Thomas, Armin W and Spector, Benjamin and Poli, Michael and Rudra, Atri and R{\'e}, Christopher},
booktitle={Advances in Neural Information Processing Systems},
year={2023}
}
您也可以引用我们之前的工作,本项目是在其基础上构建的:
@article{poli2023hyena,
title={鬣狗层级:迈向更大规模的卷积语言模型},
author={Poli, Michael and Massaroli, Stefano and Nguyen, Eric and Fu, Daniel Y and Dao, Tri and Baccus, Stephen and Bengio, Yoshua and Ermon, Stefano and R{\'e}, Christopher},
journal={arXiv预印本 arXiv:2302.10866},
year={2023}
}
@article{fu2023simple,
title={用于序列建模的简单高效长卷积},
author={Fu, Daniel Y. and Epstein, Elliot L. and Nguyen, Eric and Thomas, Armin W. and Zhang, Michael and Dao, Tri and Rudra, Atri and R{\'e}, Christopher},
journal={国际机器学习会议},
year={2023}
}
@inproceedings{fu2023hungry,
title={饥饿饥饿的河马:迈向状态空间模型的语言建模},
author={Fu, Daniel Y. and Dao, Tri and Saab, Khaled K. and Thomas, Armin W.
and Rudra, Atri and R{\'e}, Christopher},
booktitle={国际学习表示会议},
year={2023}
}
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生��成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号