





用于表格数据生成的GAN、TimeGAN、扩散模型和大型语言模型
<img src="https://yellow-cdn.veclightyear.com/0a4dffa0/fee27021-a960-413a-800d-8a17551a7bbe.png" height="15%" width="15%"> 生成对抗网络以其在生成逼真图像方面的成功而闻名。然而,它们也可以用于生成表格数据。这里将给你机会尝试其中的一些方法。- Arxiv文章:"用于不均匀分布的表格GAN"
- Medium文章:用于表格数据的GAN
如何使用库
- 安装:
pip install tabgan - 要通过采样然后通过对抗训练进行过滤来生成新的训练数据,调用
GANGenerator().generate_data_pipe:
from tabgan.sampler import OriginalGenerator, GANGenerator, ForestDiffusionGenerator, LLMGenerator import pandas as pd import numpy as np # 随机输入数据 train = pd.DataFrame(np.random.randint(-10, 150, size=(150, 4)), columns=list("ABCD")) target = pd.DataFrame(np.random.randint(0, 2, size=(150, 1)), columns=list("Y")) test = pd.DataFrame(np.random.randint(0, 100, size=(100, 4)), columns=list("ABCD")) # 生成数据 new_train1, new_target1 = OriginalGenerator().generate_data_pipe(train, target, test, ) new_train2, new_target2 = GANGenerator(gen_params={"batch_size": 500, "epochs": 10, "patience": 5 }).generate_data_pipe(train, target, test, ) new_train3, new_target3 = ForestDiffusionGenerator().generate_data_pipe(train, target, test, ) new_train4, new_target4 = LLMGenerator(gen_params={"batch_size": 32, "epochs": 4, "llm": "distilgpt2", "max_length": 500}).generate_data_pipe(train, target, test, ) # 定义所有参数的示例 new_train4, new_target4 = GANGenerator(gen_x_times=1.1, cat_cols=None, bot_filter_quantile=0.001, top_filter_quantile=0.999, is_post_process=True, adversarial_model_params={ "metrics": "AUC", "max_depth": 2, "max_bin": 100, "learning_rate": 0.02, "random_state": 42, "n_estimators": 100, }, pregeneration_frac=2, only_generated_data=False, gen_params = {"batch_size": 500, "patience": 25, "epochs" : 500,}).generate_data_pipe(train, target, test, deep_copy=True, only_adversarial=False, use_adversarial=True)
所有采样器OriginalGenerator、ForestDiffusionGenerator、LLMGenerator和GANGenerator都具有相同的输入参数。
- GANGenerator基于CTGAN
- ForestDiffusionGenerator基于Forest Diffusion (表格扩散和流匹配)
- LLMGenerator基于语言模型是真实的表格数据生成器(GReaT框架)
- gen_x_times: float = 1.1 - 生成多少数据,由于后处理和对抗过滤,输出可能会更少
- cat_cols: list = None - 分类列
- bot_filter_quantile: float = 0.001 - 后处理过滤的底部分位数
- top_filter_quantile: float = 0.999 - 后处理过滤的顶部分位数
- is_post_process: bool = True - 是否执行后处理过滤,如果为false则忽略bot_filter_quantile和top_filter_quantile
- adversarial_model_params: 对抗过滤模型的字典参数,二元任务的默认值
- pregeneration_frac: float = 2 - 对于生成步骤,将生成gen_x_times * pregeneration_frac数量的数据。但在后处理中将返回原始数据的(1 + gen_x_times)%
- gen_params: GAN训练的字典参数
generate_data_pipe方法的参数:
- train_df: pd.DataFrame 具有单独目标的训练数据框
- target: pd.DataFrame 训练数据集的输入目标
- test_df: pd.DataFrame 测试数据框 - 新生成的训练数据框应接近它
- deep_copy: bool = True - 是否复制输入文件。如果不复制,输入数据框将被覆盖
- only_adversarial: bool = False - 只对训练数据框执行对抗过滤
- use_adversarial: bool = True - 是否执行对抗过滤
- only_generated_data: bool = False - 生成后只获取新生成的数据,不与输入训练数据框连接
- @return: -> Tuple[pd.DataFrame, pd.DataFrame] - 新生成的训练数据框和测试数据
因此,你可以使用这个库来提高你的数据集质量:
def fit_predict(clf, X_train, y_train, X_test, y_test): clf.fit(X_train, y_train) return sklearn.metrics.roc_auc_score(y_test, clf.predict_proba(X_test)[:, 1]) dataset = sklearn.datasets.load_breast_cancer() clf = sklearn.ensemble.RandomForestClassifier(n_estimators=25, max_depth=6) X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split( pd.DataFrame(dataset.data), pd.DataFrame(dataset.target, columns=["target"]), test_size=0.33, random_state=42) print("初始指标", fit_predict(clf, X_train, y_train, X_test, y_test)) new_train1, new_target1 = OriginalGenerator().generate_data_pipe(X_train, y_train, X_test, ) print("OriginalGenerator指标", fit_predict(clf, new_train1, new_target1, X_test, y_test)) new_train1, new_target1 = GANGenerator().generate_data_pipe(X_train, y_train, X_test, ) print("GANGenerator指标", fit_predict(clf, new_train1, new_target1, X_test, y_test))
时间序列GAN生成 TimeGAN
你可以轻松调整代码以生成多维时间序列数据。 基本上它从_date_中提取天、月和年。以下示例演示如何使用:
import pandas as pd import numpy as np from tabgan.utils import get_year_mnth_dt_from_date,make_two_digit,collect_dates from tabgan.sampler import OriginalGenerator, GANGenerator train_size = 100 train = pd.DataFrame( np.random.randint(-10, 150, size=(train_size, 4)), columns=list("ABCD") ) min_date = pd.to_datetime('2019-01-01') max_date = pd.to_datetime('2021-12-31') d = (max_date - min_date).days + 1 train['Date'] = min_date + pd.to_timedelta(pd.np.random.randint(d, size=train_size), unit='d') train = get_year_mnth_dt_from_date(train, 'Date')
new_train, new_target = GANGenerator(gen_x_times=1.1, cat_cols=['year'], bot_filter_quantile=0.001,
top_filter_quantile=0.999,
is_post_process=True, pregeneration_frac=2, only_generated_data=False).
generate_data_pipe(train.drop('Date', axis=1), None,
train.drop('Date', axis=1)
)
new_train = collect_dates(new_train)
实验
数据集和实验设计
检查数据生成质量 只需使用内置函数
compare_dataframes(original_df, generated_df) # 返回0到1之间的值
运行实验
按照以下步骤运行实验:
- 克隆仓库。所有所需的数据集都存储在
./Research/data文件夹中 - 安装依赖
pip install -r requirements.txt - 运行所有实验
python ./Research/run_experiment.py。运行所有实验python run_experiment.py。你可以添加更多数据集,调整验证类型和分类编码器。 - 在控制台或
./Research/results/fit_predict_scores.txt中查看所有实验的指标
实验设计
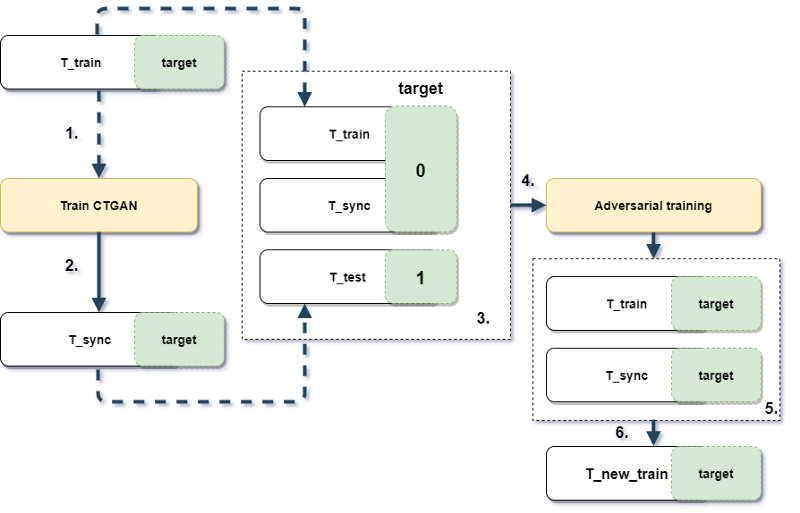
图1.1 实验设计和工作流程
结果
为确定最佳采样策略,对每个数据集的ROC AUC分数进行缩放(最小-最大缩放),然后在数据集间取平均值。
表1.2 不同数据集的采样结果,越高越好(100% - 每个数据集的最大ROC AUC)
| 数据集名称 | 无 | GAN | 原始采样 |
|---|---|---|---|
| credit | 0.997 | 0.998 | 0.997 |
| employee | 0.986 | 0.966 | 0.972 |
| mortgages | 0.984 | 0.964 | 0.988 |
| poverty_A | 0.937 | 0.950 | 0.933 |
| taxi | 0.966 | 0.938 | 0.987 |
| adult | 0.995 | 0.967 | 0.998 |
引用
如果您在科学出版物中使用GAN-for-tabular-data,我们将感谢您引用以下BibTex条目: arxiv出版物:
@misc{ashrapov2020tabular, title={Tabular GANs for uneven distribution}, author={Insaf Ashrapov}, year={2020}, eprint={2010.00638}, archivePrefix={arXiv}, primaryClass={cs.LG} }
参考文献
[1] Lei Xu LIDS, Kalyan Veeramachaneni. Synthesizing Tabular Data using Generative Adversarial Networks (2018). arXiv: 1811.11264v1 [cs.LG]
[2] Alexia Jolicoeur-Martineau and Kilian Fatras and Tal Kachman. Generating and Imputing Tabular Data via Diffusion and Flow-based Gradient-Boosted Trees ((2023) https://github.com/SamsungSAILMontreal/ForestDiffusion [cs.LG]
[3] Lei Xu, Maria Skoularidou, Alfredo Cuesta-Infante, Kalyan Veeramachaneni. Modeling Tabular data using Conditional GAN. NeurIPS, (2019)
[4] Vadim Borisov and Kathrin Sessler and Tobias Leemann and Martin Pawelczyk and Gjergji Kasneci. Language Models are Realistic Tabular Data Generators. ICLR, (2023)
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号