
GPT4Tools
大语言模型自学使用多模态工具的创新系统
GPT4Tools是基于Vicuna (LLaMA)的创新系统,通过71K自建指令数据实现对多个视觉基础模型的智能控制。该系统能自动决策和利用不同视觉模型,实现对话中的图像交互。项目支持通过自我指导和LoRA微调教授大语言模型使用工具,为图像相关需求提供高效解决方案。GPT4Tools的开源性和灵活性使其成为AI研究与应用的重要工具。




GPT4Tools: 通过自我指导教导大语言模型使用工具
Lin Song、Yanwei Li、Rui Yang、Sijie Zhao、Yixiao Ge、Xiu Li、Ying Shan
GPT4Tools是一个可以控制多个视觉基础模型的集中系统。它基于Vicuna (LLaMA)和71K自建指令数据。通过分析语言内容,GPT4Tools能够自动决策、控制和利用不同的视觉基础模型,允许用户在对话中与图像交互。通过这种方法,GPT4Tools为在对话中满足各种图像相关需求提供了无缝高效的解决方案。与之前的工作不同,我们支持用户通过简单的自我指导和LoRA微调来教导他们自己的大语言模型使用工具。
<a href='https://gpt4tools.github.io'><img src='https://img.shields.io/badge/Project-Page-Green'></a> <a href='https://huggingface.co/stevengrove/gpt4tools-vicuna-13b-lora'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Model-blue'></a> 

更新
- 🔥 我们更新了适用于vicuna-v1.5的新代码和模型!
- 🔥 我们的论文被NIPS 2023接受!
- 🔥 我们现在发布了<a href='https://arxiv.org/pdf/2305.18752.pdf'><strong><font color='#008AD7'>论文</font></strong></a>和新的<a href='https://huggingface.co/spaces/stevengrove/GPT4Tools'><strong><font color='#008AD7'>演示</font></strong></a>,包括LLAVA、OPT、LlaMA和Vicuna。
- 🔥 我们发布了使用<strong><font color="#008AD7">Vicuna-13B</font></strong>预训练的GPT4Tools模型,并发布了<strong><font color="#008AD7">自我指导</font></strong>的数据集。查看博客和演示。
演示
我们在本节提供了一些使用GPT4Tools的精选示例。更多示例可以在我们的项目页面找到。欢迎尝试我们的在线演示!
<div align=center> <img width="80%" src="https://yellow-cdn.veclightyear.com/2b54e442/6f08d3a9-05d6-4f9c-8d62-537002add3fe.gif"/> </div> <details> <summary>更多演示</summary>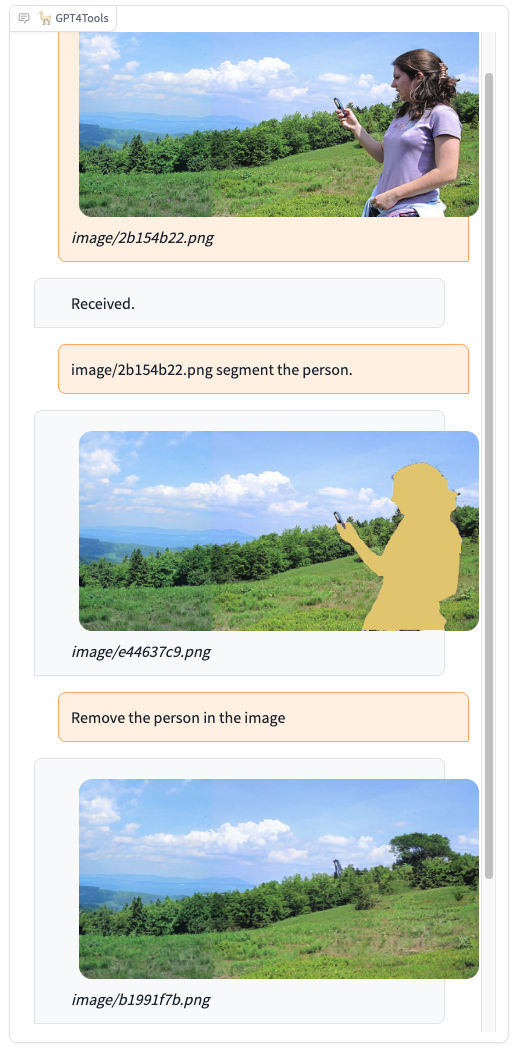 | 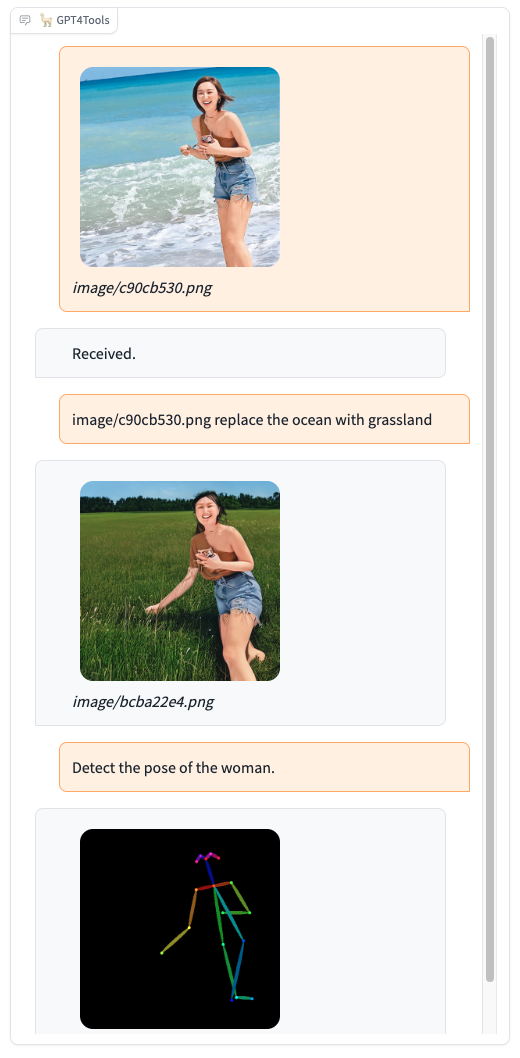 |
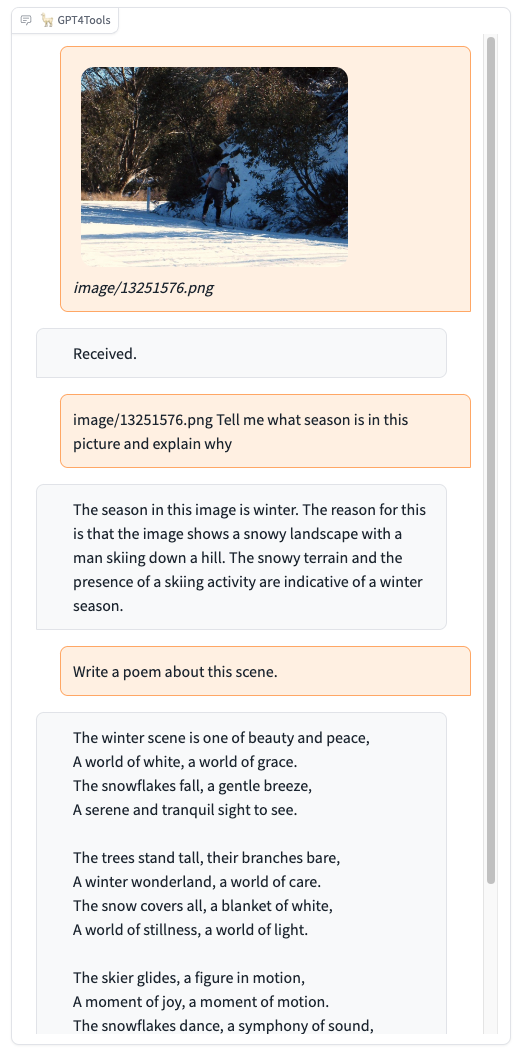 | 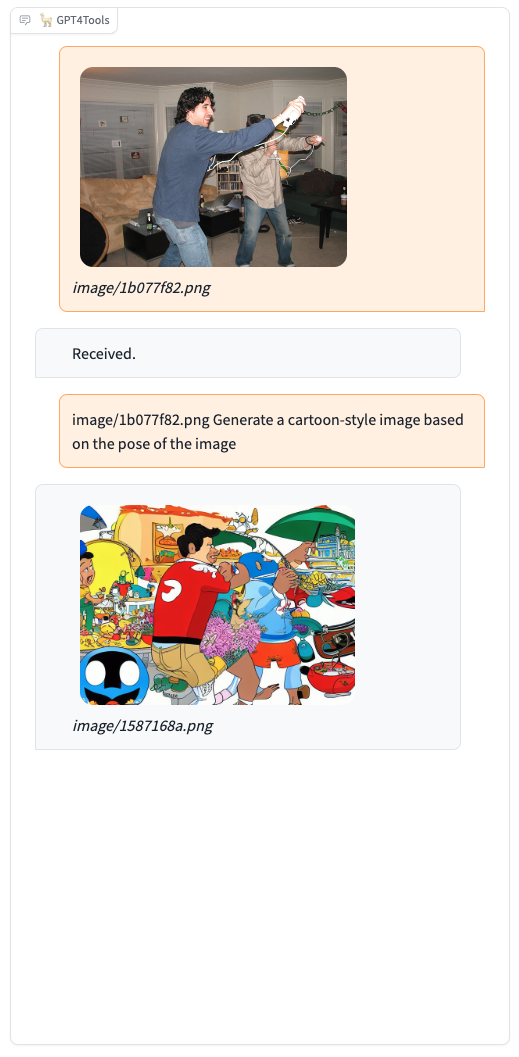 |
数据集
| 数据文件名 | 大小 | OneDrive | Google Drive |
|---|---|---|---|
| gpt4tools_71k.json | 229 MB | 链接 | 链接 |
| gpt4tools_val_seen.json | -- | 链接 | 链接 |
| gpt4tools_test_unseen.json | -- | 链接 | 链接 |
-
gpt4tools_71k.json包含我们用于微调GPT4Tools模型的71K指令跟随数据。 -
gpt4tools_val_seen.json是用于验证的手动清理的指令数据,包括与gpt4tools_71k.json中工具相关的指令。 -
gpt4tools_test_unseen.json是用于测试的清理过的指令数据,包括一些在gpt4tools_71k.json中不存在的工具相关指令。
data.md展示了如何生成、格式化和清理数据。
模型
GTP4Tools主要包含三个部分:用于指令��的LLM、用于适配的LoRA和用于提供功能的Visual Agent。这是一个灵活且可扩展的系统,可以轻松扩展以支持更多工具和功能。例如,用户可以用自己的模型替换现有的LLM或工具,或向系统添加新工具。唯一需要做的是用提供的指令微调LoRA,这会教导LLM使用提供的工具。
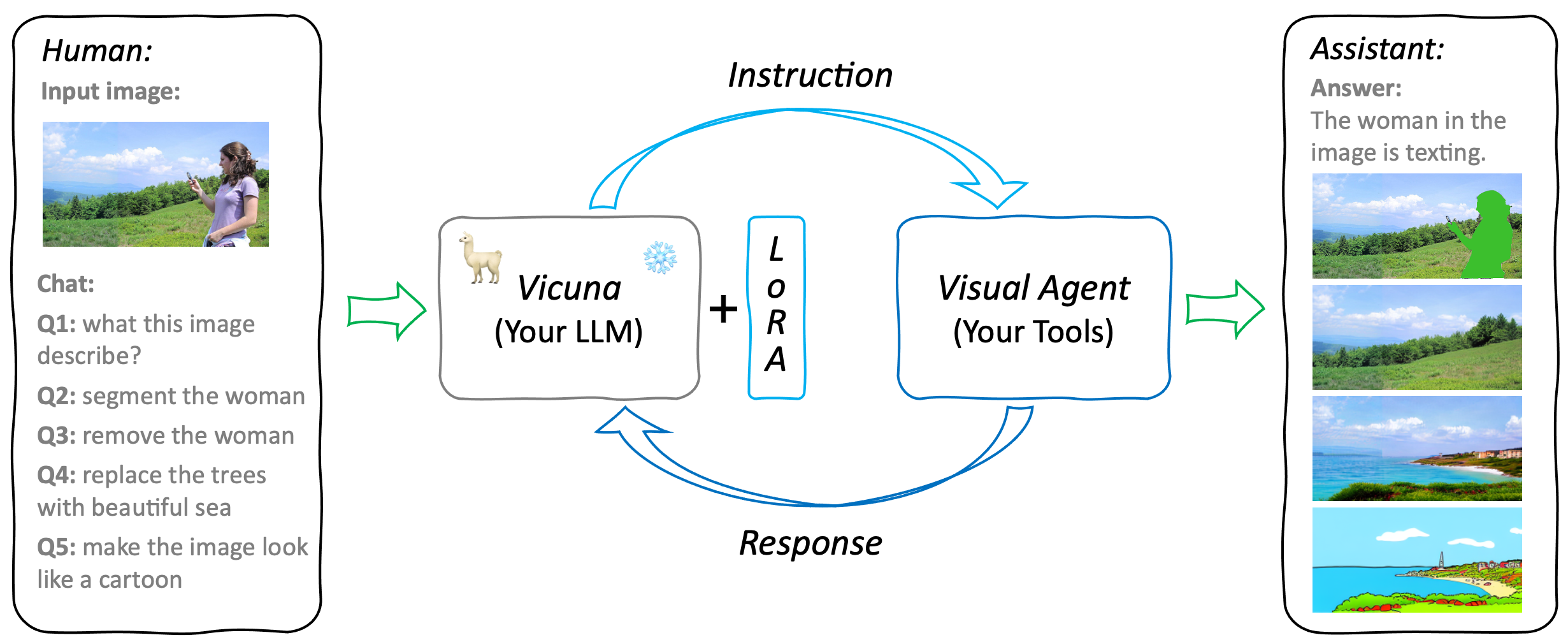 GPT4Tools 基于 Vicuna,我们发布了 GPT4Tools 的 LoRA 权重以遵守 LLaMA 模型许可。您可以将我们的 LoRA 权重与 Vicuna 权重合并以获得 GPT4Tools 权重。
GPT4Tools 基于 Vicuna,我们发布了 GPT4Tools 的 LoRA 权重以遵守 LLaMA 模型许可。您可以将我们的 LoRA 权重与 Vicuna 权重合并以获得 GPT4Tools 权重。
开始使用
环境
git clone https://github.com/AILab-CVC/GPT4Tools
cd GPT4Tools
pip install -r requirements.txt
权重
# 下载到您的缓存目录
python3 scripts/download.py \
--model-names "lmsys/vicuna-13b-v1.5" "lmsys/vicuna-7b-v1.5" \
--cache-dir $your_cache_dir
- 从以下链接下载 gpt4tools LoRA 权重:
| 模型 | OneDrive | Google Driver | Huggingface |
|---|---|---|---|
| vicuna-7b-v1.5-gpt4tools | 链接 | 链接 | |
| vicuna-13b-v1.5-gpt4tools | 链接 | 链接 |
旧版权重可以在这里找到。
工具
GPT4Tools 支持 22 种工具。详情请查看 tools.md。 首次使用工具时,需要将工具的权重下载到缓存中。如果您不想将它们存储在默认缓存中,请修改 shell 环境变量:
export TRANSFORMERS_CACHE=${your_transformers_cache}
export HUGGINGFACE_HUB_CACHE=${your_diffusers_cache}
此外,您还可以将权重下载到自定义缓存中。
# 下载 huggingface 模型
python3 scripts/download.py \
--model-names "Salesforce/blip-image-captioning-base" "Salesforce/blip-vqa-base" "timbrooks/instruct-pix2pix" "runwayml/stable-diffusion-v1-5" "runwayml/stable-diffusion-inpainting" "lllyasviel/ControlNet" "fusing/stable-diffusion-v1-5-controlnet-canny" "fusing/stable-diffusion-v1-5-controlnet-mlsd" "fusing/stable-diffusion-v1-5-controlnet-hed" "fusing/stable-diffusion-v1-5-controlnet-scribble" "fusing/stable-diffusion-v1-5-controlnet-openpose" "fusing/stable-diffusion-v1-5-controlnet-seg" "fusing/stable-diffusion-v1-5-controlnet-depth" "fusing/stable-diffusion-v1-5-controlnet-normal" "sam" "groundingdino" \
--cache-dir $your_cache_dir
使用 Web GUI 提供服务
按照 scripts/demo.sh 或以下代码在您自己的设备上创建 gradio 界面:
# 1 个 GPU 的建议
python gpt4tools_demo.py \
--base_model $path_to_vicuna_with_tokenizer \
--lora_model $path_to_lora_weights \
--llm_device "cpu" \
--load "Text2Box_cuda:0,Segmenting_cuda:0,Inpainting_cuda:0,ImageCaptioning_cuda:0" \
--cache-dir $your_cache_dir \
--server-port 29509 \
--share
# 4 个 GPU 的建议
python gpt4tools_demo.py \
--base_model $path_to_vicuna_with_tokenizer
--lora_model $path_to_lora_weights \
--llm_device "cuda:3" \
--load "Text2Box_cuda:0,Segmenting_cuda:0,Inpainting_cuda:0,ImageCaptioning_cuda:0,Text2Image_cuda:1,VisualQuestionAnswering_cuda:1,InstructPix2Pix_cuda:2,SegText2Image_cuda:2,Image2Pose_cpu,PoseText2Image_cuda:2" \
--cache-dir $your_cache_dir \
--server-port 29509 \
--share
您可以通过在 gpt4tools_demo.py 的 --load 参数后指定 {tools_name}_{devices} 来自定义使用的工具。tools_name 在 tools.md 中有说明。
微调
将 gpt4tools_71k.json 下载到 ./datasets 后,您可以按照 scripts/finetune_lora.sh 或运行以下代码来微调您的模型:
deepspeed train.py \
--base_model $path_to_vicuna_with_tokenizer \
--data_path $path_to_gpt4tools_71k.json \
--deepspeed "scripts/zero2.json" \
--output_dir output/gpt4tools \
--num_epochs 6 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 16 \
--model_max_length 2048 \
--lora_target_modules '[q_proj,k_proj,v_proj,o_proj]' \
--lora_r 16 \
--learning_rate 3e-4 \
--lazy_preprocess True \
--cache_dir $your_cache_dir \
--report_to 'tensorboard' \
--gradient_checkpointing True
| 超参数 | 全局批量大小 | 学习率 | 最大长度 | 权重衰减 | LoRA 注意力维度 (lora_r) | LoRA 缩放 alpha(lora_alpha) | LoRA dropout (lora_dropout) | 应用 LoRA 的模块 (lora_target_modules) |
|---|---|---|---|---|---|---|---|---|
| GPT4Tools & Vicuna-13B | 512 | 3e-4 | 2048 | 0.0 | 16 | 16 | 0.05 | [q_proj,k_proj,v_proj,o_proj] |
如果您想评估模型使用工具的成功率,请点击这里。
致谢
- VisualChatGPT:它连接了 ChatGPT 和一系列视觉基础模型,使聊天过程中能够发送和接收图像。
- Vicuna:Vicuna 的语言能力非常出色和令人惊叹。而且它是开源的!
- Alpaca-LoRA:在消费级硬件上对 LLaMA 进行指令微调。 如果您在研究或应用中使用我们的GPT4Tools,请引用:
@misc{gpt4tools,
title = {GPT4Tools: 通过自我指导教导大语言模型使用工具},
author={杨睿, 宋林, 李彦伟, 赵思捷, 葛益骁, 李秀, 单瑛},
journal={arXiv预印本 arXiv:2305.18752},
year={2023}
}
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适��应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站�式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号