


Capsolver
Capsolver.com is an AI-powered service that specializes in solving various types of captchas automatically. It supports captchas such as reCAPTCHA V2, reCAPTCHA V3, hCaptcha, FunCaptcha, DataDome, AWS Captcha, Geetest, and Cloudflare Captcha / Challenge 5s, Imperva / Incapsula, among others.
For developers, Capsolver offers API integration options detailed in their documentation, facilitating the integration of captcha solving into applications. They also provide browser extensions for Chrome and Firefox, making it easy to use their service directly within a browser. Different pricing packages are available to accommodate varying needs, ensuring flexibility for users.
SimGAN-Captcha
With simulated unsupervised learning, breaking captchas has never been easier. There is no need to label any captchas manually for convnet. By using a captcha synthesizer and a refiner trained with GAN, it's feasible to generate synthesized training pairs for classifying captchas.
Link to paper: SimGAN by Apple
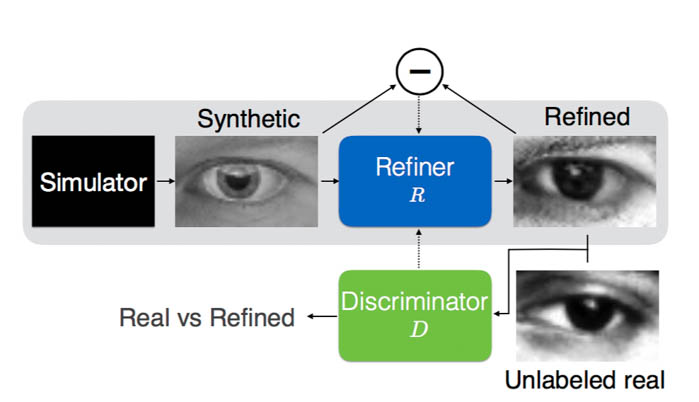
The task
Correctly label 10000 out of 15000 captcha or 90% per character.
Preprocessing
Download target captcha files
Here we download some captchas from the contest website. Each batch has 1000 captchas. We'll use 20000 so 20 batches.
import requests import threading URL = "https://captcha.delorean.codes/u/rickyhan/challenge" DIR = "challenges/" NUM_CHALLENGES = 20 lock = threading.Lock()
def download_file(url, fname): # NOTE the stream=True parameter r = requests.get(url, stream=True) with open(fname, 'wb') as f: for chunk in r.iter_content(chunk_size=1024): if chunk: # filter out keep-alive new chunks f.write(chunk) #f.flush() commented by recommendation from J.F.Sebastian with lock: pass # print fname ts = [] for i in range(NUM_CHALLENGES): fname = DIR + "challenge-{}".format(i) t = threading.Thread(target=download_file, args=(URL, fname)) ts.append(t) t.start() for t in ts: t.join() print "Done"
Done
Decompression
Each challenge file is actually a json object containing 1000 base64 encoded jpg image file. So for each of these challenge files, we decompress each base64 strs into a jpeg and put that under a seprate folder.
import json, base64, os IMG_DIR = "./orig" fnames = ["{}/challenge-{}".format(DIR, i) for i in range(NUM_CHALLENGES)] if not os.path.exists(IMG_DIR): os.mkdir(IMG_DIR) def save_imgs(fname): with open(fname) as f: l = json.loads(f.read()) for image in l['images']: b = base64.decodestring(image['jpg_base64']) name = image['name'] with open(IMG_DIR+"/{}.jpg".format(name), 'w') as f: f.write(b) for fname in fnames: save_imgs(fname) assert len(os.listdir(IMG_DIR)) == 1000 * NUM_CHALLENGES
from PIL import Image imgpath = IMG_DIR + "/"+ os.listdir(IMG_DIR)[0] imgpath2 = IMG_DIR + "/"+ os.listdir(IMG_DIR)[3] im = Image.open(example_image_path) im2 = Image.open(example_image_path2) IMG_FNAMES = [IMG_DIR + '/' + p for p in os.listdir(IMG_DIR)]
im

im2

Convert to black and white
Instead of RGB, binarized image saves significant compute. Here we hardcode a threshold and iterate over each pixel to obtain a binary image.
def gray(img_path): # convert to grayscale, then binarize img = Image.open(img_path).convert("L") img = img.point(lambda x: 255 if x > 200 or x == 0 else x) # value found through T&E img = img.point(lambda x: 0 if x < 255 else 255, "1") img.save(img_path) for img_path in IMG_FNAMES: gray(img_path)
im = Image.open(example_image_path) im

Find mask
As you may have noticed, all the captchas share the same horizontal lines. Since this is a contest, it was a function of participant's username. In the real world, these noises can be filtered out using morphological transformation with OpenCV.
We will extract and save the lines(noise) for later use. Here we average all 20000 captchas and set a threshold as above. Another method is using a bit mask (&=) to iteratively filter out surrounding black pixels i.e.
mask = np.ones((height, width))
for im in ims:
mask &= im
The effectiveness of bit mask depends on how clean the binarized data is. With the averaging method, some error is allowed.
import numpy as np WIDTH, HEIGHT = im.size MASK_DIR = "avg.png"
def generateMask(): N=1000*NUM_CHALLENGES arr=np.zeros((HEIGHT, WIDTH),np.float) for fname in IMG_FNAMES: imarr=np.array(Image.open(fname),dtype=np.float) arr=arr+imarr/N arr=np.array(np.round(arr),dtype=np.uint8) out=Image.fromarray(arr,mode="L") out.save(MASK_DIR) generateMask()
im = Image.open(MASK_DIR) # ok this can be done with binary mask: &= im

im = Image.open(MASK_DIR) im = im.point(lambda x:255 if x > 230 else x) im = im.point(lambda x:0 if x<255 else 255, "1") im.save(MASK_DIR)
im

Generator for real captchas
Using a Keras built in generator function flow_from_directory to automatically import and preprocess real captchas from a folder.
from keras import models from keras import layers from keras import optimizers from keras import applications from keras.preprocessing import image import tensorflow as tf
# Real data generator datagen = image.ImageDataGenerator( preprocessing_function=applications.xception.preprocess_input ) flow_from_directory_params = {'target_size': (HEIGHT, WIDTH), 'color_mode': 'grayscale', 'class_mode': None, 'batch_size': BATCH_SIZE} real_generator = datagen.flow_from_directory( directory=".", **flow_from_directory_params )
(Dumb) Generator
Now that we have processed all the real captchas, we need to define a generator that outputs (captcha, label) pairs where the captchas should look almost like the real ones.
We filter out the outliers that contain overlapping characters.
# Synthetic captcha generator from PIL import ImageFont, ImageDraw from random import choice, random from string import ascii_lowercase, digits alphanumeric = ascii_lowercase + digits def fuzzy_loc(locs): acc = [] for i,loc in enumerate(locs[:-1]): if locs[i+1] - loc < 8: continue else: acc.append(loc) return acc def seg(img): arr = np.array(img, dtype=np.float) arr = arr.transpose() # arr = np.mean(arr, axis=2) arr = np.sum(arr, axis=1) locs = np.where(arr < arr.min() + 2)[0].tolist() locs = fuzzy_loc(locs) return locs def is_well_formed(img_path): original_img = Image.open(img_path) img = original_img.convert('1') return len(seg(img)) == 4 noiseimg = np.array(Image.open("avg.png").convert("1")) # noiseimg = np.bitwise_not(noiseimg) fnt = ImageFont.truetype('./arial-extra.otf', 26) def gen_one(): og = Image.new("1", (100,50)) text = ''.join([choice(alphanumeric) for _ in range(4)]) draw = ImageDraw.Draw(og) for i, t in enumerate(text): txt=Image.new('L', (40,40)) d = ImageDraw.Draw(txt) d.text( (0, 0), t, font=fnt, fill=255) if random() > 0.5: w=txt.rotate(-20*(random()-1), expand=1) og.paste( w, (i*20 + int(25*random()), int(25+30*(random()-1))), w) else: w=txt.rotate(20*(random()-1), expand=1) og.paste( w, (i*20 + int(25*random()), int(20*random())), w) segments = seg(og) if len(segments) != 4: return gen_one() ogarr = np.array(og) ogarr = np.bitwise_or(noiseimg, ogarr) ogarr = np.expand_dims(ogarr, axis=2).astype(float) ogarr = np.random.random(size=(50,100,1)) * ogarr ogarr = (ogarr > 0.0).astype(float) # add noise return ogarr, text def synth_generator(): arrs = [] while True: for _ in range(BATCH_SIZE): arrs.append(gen_one()[0]) yield np.array(arrs) arrs = []
def get_image_batch(generator): """keras generators may generate an incomplete batch for the last batch""" img_batch = generator.next() if len(img_batch) != BATCH_SIZE: img_batch = generator.next() assert len(img_batch) == BATCH_SIZE return img_batch
import matplotlib.pyplot as plt imarr = get_image_batch(real_generator)[0, :, :, 0] plt.imshow(imarr)
<matplotlib.image.AxesImage at 0x7f160fda74d0>

imarr = get_image_batch(synth_generator())[0, :, :, 0] print imarr.shape plt.imshow(imarr)
(50, 100)
<matplotlib.image.AxesImage at 0x7f160fdd4390>

What happened next?
Plug all the data in an MNIST-like classifier and call it a day. Unfortunately, it's not that simple.
I actually spent a long time fine-tuning the network but accuracy plateued around 55% sampled. The passing requirement is 10000 out of 15000 submitted or 90% accuracy or 66% per char. I was facing a dilemma: tune the model even further or manually label x amount of data:
0.55 * (15000-x) + x = 10000
x = 3888
Obviously I am not going to label 4000 captchas and break my neck in the process.
Meanwhile, there happened a burnt out guy who decided to label all 10000 captchas. This dilligent dude was 2000 in. I asked if he is willing to collaborate on a solution. It's almost like he didn't want to label captchas anymore. He agreed immediately.
Using the same model, accuracy immediately shot up to 95% and we both qualified for HackMIT.
/aside
After the contest, I perfected the model and got 95% without labelling a single image. Here is the model for SimGAN:
Model Definition
There are three components to the network:
Refiner
The refiner network, Rθ, is a residual network (ResNet). It modifies the synthetic image on a pixel level, rather than holistically modifying the image content, preserving the global structure and annotations.
Discriminator
The discriminator network Dφ, is a simple ConvNet that contains 5 conv layers and 2 max-pooling layers. It's abinary classifier that outputs whether a captcha is synthesized or real.
Combined
Pipe the refined image into discriminator.
def refiner_network(input_image_tensor): """ :param input_image_tensor: Input tensor that corresponds to a synthetic image. :return: Output tensor that corresponds to a refined synthetic image. """ def resnet_block(input_features, nb_features=64, nb_kernel_rows=3, nb_kernel_cols=3): """ A ResNet block with two `nb_kernel_rows` x `nb_kernel_cols` convolutional layers, each with `nb_features` feature maps. See Figure 6 in https://arxiv.org/pdf/1612.07828v1.pdf. :param input_features: Input tensor to ResNet block. :return: Output tensor from ResNet block. """ y = layers.Convolution2D(nb_features, nb_kernel_rows, nb_kernel_cols, border_mode='same')(input_features) y = layers.Activation('relu')(y) y = layers.Convolution2D(nb_features, nb_kernel_rows, nb_kernel_cols, border_mode='same')(y) y = layers.merge([input_features, y], mode='sum') return layers.Activation('relu')(y) # an input image of size w × h is convolved with 3 × 3 filters that output 64 feature maps x = layers.Convolution2D(64, 3, 3, border_mode='same', activation='relu')(input_image_tensor) # the output is passed through 4 ResNet blocks for _ in range(4): x = resnet_block(x) # the output of the last ResNet block is passed to a 1 × 1 convolutional layer producing 1 feature map # corresponding to the refined synthetic image return layers.Convolution2D(1, 1, 1, border_mode='same', activation='tanh')(x) def discriminator_network(input_image_tensor): """ :param input_image_tensor: Input tensor corresponding to an image, either real or refined. :return: Output tensor that corresponds to the probability of whether an image is real or refined. """ x = layers.Convolution2D(96, 3, 3, border_mode='same', subsample=(2, 2), activation='relu')(input_image_tensor) x = layers.Convolution2D(64, 3, 3, border_mode='same', subsample=(2, 2), activation='relu')(x) x = layers.MaxPooling2D(pool_size=(3, 3), border_mode='same', strides=(1, 1))(x) x = layers.Convolution2D(32, 3, 3, border_mode='same', subsample=(1, 1), activation='relu')(x) x =
编辑推荐精选


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!


堆友
多风格AI绘画神器
堆友平台由阿里巴巴设计团队创建,作为一款AI驱动的设计工具,专为设计师提供一站式增长服务。功能覆盖海量3D素材、AI绘画、实时渲染以及专业抠图,显著提升设计品质和效率。平台不仅提供工具,还是一个促进创意交流和个人发展的空间,界面友好,适合所有级别的设计师和创意工作者。


码上飞
零代码AI应用开发平台
零代码AI应用开发平台,用��户只需一句话简单描述需求,AI能自动生成小程序、APP或H5网页应用,无需编写代码。


Vora
免费创建高清无水印Sora视频
Vora是一个免费创建高清无水印Sora视频的AI工具


Refly.AI
最适合小白的AI自动化工作流平台
无需编码,轻松生成可复用、可变现的AI自动化工作流


酷表ChatExcel
大模型驱动的Excel数据处理工具
基于大模型交互的表格处理系统,允许用户通过对话方式完成数据整理和可视化分析。系统采用机器学习算法解析用户指令,自动执行排序、公式计算和数据透视等操作,支持多种文件格式导入导出。数据处理响应速度保持在0.8秒以内,支持超过100万行数据的即时分析。


TRAE编程
AI辅助编程,代码自动修复
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更�快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


AIWritePaper论文写作
AI论文写作指导平台
AIWritePaper论文写作是一站式AI论文写作辅助工具,简化了选题、文献检索至论文撰写的整个过程。通过简单设定,平台可快速生成高质量论文大纲和全文,配合图表、参考文献等一应俱全,同时提供开题报告和答辩PPT等增值服务,保障数据安全,有效提升写作效率和论文质量。


博思AIPPT
AI一键生成PPT,就用博思AIPPT!
博思AIPPT,新一代的AI生成PPT平台,支持智能生成PPT、AI美化PPT、文本&链接生成PPT、导入Word/PDF/Markdown文档生成PPT等,内置海量精美PPT模板,涵盖商务、教育、科技等不同风格,同时针对每个页面提供多种版式,一键自适应切换,完美适配各种办公场景。


潮际好麦
AI赋能电商视觉革命,一站式智能商拍平台
潮际好麦深耕服装行业,是国内AI试衣效果最好的软件。使用先进AIGC能力为电商卖家批量提供优质的、低成本的商拍图。合作品牌有Shein、Lazada、安踏、百丽等65个国内外头部品牌,以及国内10万+淘宝、天猫、京东等主流平台的品牌商家,为卖家节省将近85%的出图成本,提升约3倍出图效率,让品牌能够快速上架。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号