Bonito: 无需GPT的轻量级指令微调数据集生成库
 Ray
RayBonito简介
Bonito是一个由Brown大学BATS研究实验室开发的开源项目,旨在解决条件任务生成(Conditional Task Generation)问题。所谓条件任务生成,是指将未标注的文本转换为特定任务的指令微调数据集的过程。Bonito的出现为研究人员和开发者提供了一种无需依赖GPT等大型语言模型,就能生成高质量指令微调数据集的轻量级解决方案。
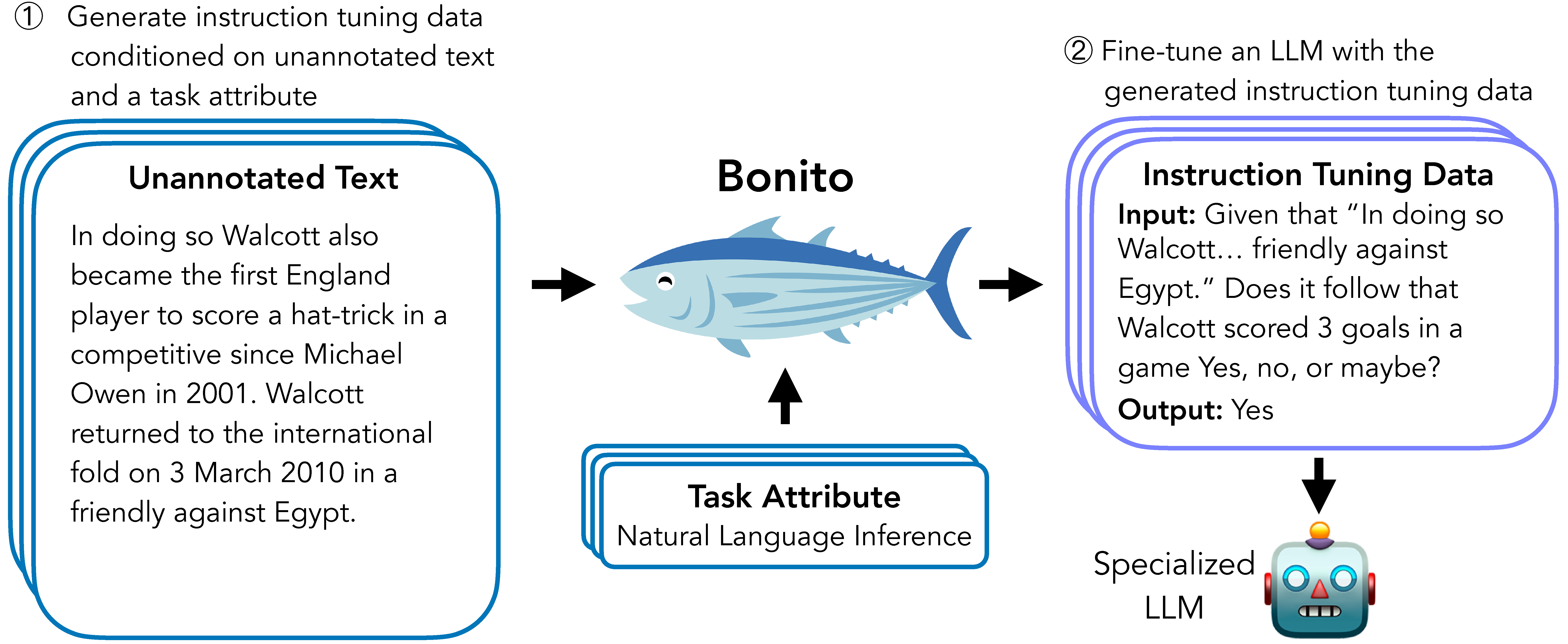
Bonito的核心特性
Bonito具有以下几个突出的特点:
-
轻量级: Bonito基于Hugging Face的transformers和vllm库构建,使用简单,易于集成。
-
多任务支持: Bonito支持多种NLP任务类型,包括问答、文本分类、摘要生成等。
-
高效性: 相比使用GPT等大模型,Bonito在生成指令微调数据集时更加高效。
-
可定制性: 用户可以根据自己的需求调整生成参数,以获得最适合的数据集。
-
开源免费: Bonito采用BSD-3-Clause许可证,可以自由使用和修改。
Bonito的工作原理
Bonito的核心是一个经过训练的条件任务生成模型。该模型接收未标注的文本作为输入,然后生成与特定任务相关的指令和示例。这个过程可以概括为以下几个步骤:
- 输入未标注文本
- 指定目标任务类型
- 模型生成相关指令和示例
- 输出结构化的指令微调数据集
通过这种方式,Bonito能够将原始文本转换为可直接用于指令微调的高质量数据集。
安装和基本使用
要开始使用Bonito,首先需要安装相关依赖。推荐使用conda创建一个新的环境:
conda create -n bonito python=3.9 conda activate bonito pip install -e .
安装完成后,可以使用以下Python代码来生成synthetic指令微调数据集:
from bonito import Bonito from vllm import SamplingParams from datasets import load_dataset # 初始化Bonito模型 bonito = Bonito("BatsResearch/bonito-v1") # 加载未标注文本数据集 unannotated_text = load_dataset( "BatsResearch/bonito-experiment", "unannotated_contract_nli" )["train"].select(range(10)) # 设置采样参数 sampling_params = SamplingParams(max_tokens=256, top_p=0.95, temperature=0.5, n=1) # 生成synthetic指令微调数据集 synthetic_dataset = bonito.generate_tasks( unannotated_text, context_col="input", task_type="nli", sampling_params=sampling_params )
支持的任务类型
Bonito支持多种NLP任务类型,包括但不限于:
- 抽取式问答 (exqa)
- 多选问答 (mcqa)
- 问题生成 (qg)
- 开放式问答 (qa)
- 是非问答 (ynqa)
- 指代消解 (coref)
- 释义生成 (paraphrase)
- 释义识别 (paraphrase_id)
- 句子补全 (sent_comp)
- 情感分析 (sentiment)
- 文本摘要 (summarization)
- 文本生成 (text_gen)
- 主题分类 (topic_class)
- 词义消歧 (wsd)
- 文本蕴含 (te)
- 自然语言推理 (nli)
用户可以根据具体需求选择合适的任务类型。
实际应用案例
为了更好地理解Bonito的实际应用,我们来看一个具体的例子。假设我们有一组未标注的法律合同文本,我们希望生成一个用于自然语言推理(NLI)任务的指令微调数据集。
首先,我们加载未标注的文本数据:
unannotated_text = load_dataset( "BatsResearch/bonito-experiment", "unannotated_contract_nli" )["train"].select(range(10))
然后,我们使用Bonito生成synthetic数据集:
synthetic_dataset = bonito.generate_tasks( unannotated_text, context_col="input", task_type="nli", sampling_params=sampling_params )
生成的synthetic_dataset将包含一系列NLI任务的指令和示例,这些可以直接用于训练或微调大型语言模型。
Bonito的优势
与传统的数据标注方法相比,Bonito具有以下优势:
-
成本效益: 无需人工标注,大大降低了数据集创建的成本。
-
速度: Bonito可以快速生成大量的指令微调数据,显著缩短了数据准备时间。
-
一致性: 机器生成的指令和示例往往具有更高的一致性,减少了人为错误。
-
可扩展性: Bonito可以轻松应用于不同领域和任务类型,具有良好的可扩展性。
-
隐私保护: 由于不需要人工参与标注过程,Bonito更好地保护了原始数据的隐私。
最新进展
Bonito项目一直在不断发展和改进。以下是一些最新的进展:
- 🐡 2024年8月: 发布了基于Meta Llama 3.1的新Bonito模型。
- 🐟 2024年6月: Bonito相关论文被ACL Findings 2024接收。
这些进展表明,Bonito正在得到学术界和工业界的认可,并持续改进其性能和功能。
使用教程
为了帮助用户更好地使用Bonito,项目团队提供了详细的教程:
这些教程涵盖了从基本设置到高级使用的各个方面,是新手和有经验用户的宝贵资源。
社区贡献
Bonito是一个开源项目,欢迎社区成员的贡献。目前,已经有多位贡献者参与了项目的开发和改进:
- Nihal Nayak (@nihalnayak)
- Avi Trost (@avitrost)
- Stephen Bach (@stephenbach)
- Ikko Eltociear Ashimine (@eltociear)
社区的参与不仅限于代码贡献,还包括文档改进、bug报告、功能建议等多个方面。
未来展望
随着人工智能和自然语言处理技术的不断发展,Bonito在未来可能会有更广阔的应用前景:
-
多语言支持: 扩展到更多语言,支持跨语言的指令微调数据集生成。
-
任务复杂度提升: 支持更复杂的NLP任务,如多轮对话、多模态任务等。
-
与其他AI工具集成: 与自动机器学习(AutoML)工具集成,实现端到端的模型训练和部署流程。
-
个性化定制: 允许用户根据特定领域或应用场景定制Bonito模型。
-
实时生成: 开发实时生成指令微调数据的能力,以支持动态学习场景。
结语
Bonito作为一个创新的指令微调数据集生成工具,为NLP研究和应用开辟了新的可能性。它不仅简化了数据准备过程,还提高了数据质量和一致性。随着项目的不断发展和社区的积极参与,我们有理由相信Bonito将在未来的AI和NLP领域发挥更大的作用。
无论您是研究人员、开发者还是AI爱好者,Bonito都值得您去尝试和探索。通过使用Bonito,您可以更轻松地创建高质量的指令微调数据集,从而推动您的NLP项目更快、更好地发展。
如果您对Bonito感兴趣,不妨访问项目GitHub页面了解更多信息,或者直接尝试使用它来生成您自己的指令微调数据集。让我们一起期待Bonito在NLP领域带来的更多惊喜和突破!
编辑推荐精选


GPT Plus|Pro充值
GPT充值
支持 ChatGPT Plus / Pro 充值服务,支付便捷,自动发货,售后可查。


GPT Image 2中文站
AI 图片生成平台
GPT Image 2 是面向用户的 AI 图片生成平台,支持文生图、图生图及多模型创意工作流。


Vecbase
你的AI Agent团队
Vecbase 是专为 AI 团队打造的智能工作空间,将数据管理、模型协作与知识沉淀整合于一处。算法、产品与业务在同一平台无缝协同,让从数据到 AI 应用的落地更快一步。


音述AI
全球首个AI音乐社区
音述AI是全球首个AI音乐社区,致力让每个人都能用音乐表达自我。音述AI提供零门槛AI创作工具,独创GETI法则帮助用户精准定义音乐风格,AI润色功能支持自动优化作品质感。音述AI支持交流讨论、二次创作与价值变现。针对中文用户的语言习惯与文化背景进行专门优化,支持国风融合、C-pop等本土音乐标签,让技术更好地承载人文表达。


QoderWork
阿里Qoder团队推出的桌面端AI智能体
QoderWork 是阿里推出的本地优先桌面 AI 智能体,适配 macOS14+/Windows10+,以自然语言交互实现文件管理、数据分析、AI 视觉生成、浏览器自动化等办公任务,自主拆解执行复杂工作流,数据本地运行零上传,技能市场可无限扩展,是高效的 Agentic 生产力办公助手。


lynote.ai
一站式搞定所有学习需求
不再被海量信息淹没,开始真正理解知识。Lynote 可摘要 YouTube 视频、PDF、文章等内容。即时创建笔记,检测 AI 内容并下载资料,将您的学习效率提升 10 倍。


AniShort
为AI短剧协作而生
专为AI短剧协作而生的AniShort正式发布,深度重构AI短剧全流程生产模式,整合创意策划、制作执行、实时协作、在线审片、资产复用等全链路功能,独创无限画布、双轨并行工业化工作流与Ani智能体助手,集成多款主流AI大模型,破解素材零散、版本混乱、沟通低效等行业痛点,助力3人团队效率提升800%,打造标准化、可追溯的AI短剧量产体系,是AI短剧团队协同创作、提升制作效率的核心工具。


seedancetwo2.0
能听懂你表达的视频模型
Seedance two是基于seedance2.0的中国大模型,支持图像、视频、音频、文本四种模态输入,表达方式更丰富,生成也更可控。


nano-banana纳米香蕉中文站
国内直接访问,限时3折
输入简单文字,生成想要的图片,纳米香蕉中文站基于 Google 模型的 AI 图片生成网站,支持文字生图、图生图。官网价格限时3折活动


扣子-AI办公
职场AI,就用扣子
AI办公助手,复杂任务高效处理。办公效率低?扣子空间AI助手支持播客生成、PPT制作、网页开发及报告写作,覆盖科研、商业、舆情等领域的专家Agent 7x24小时响应,生活工作无缝切换,提升50%效率!
推荐工具精选





AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号